在BEVFusion的相机工作流中,图像编码之后会经过一个FPN+ADP的网络,那么这个结构的作用是什么呢
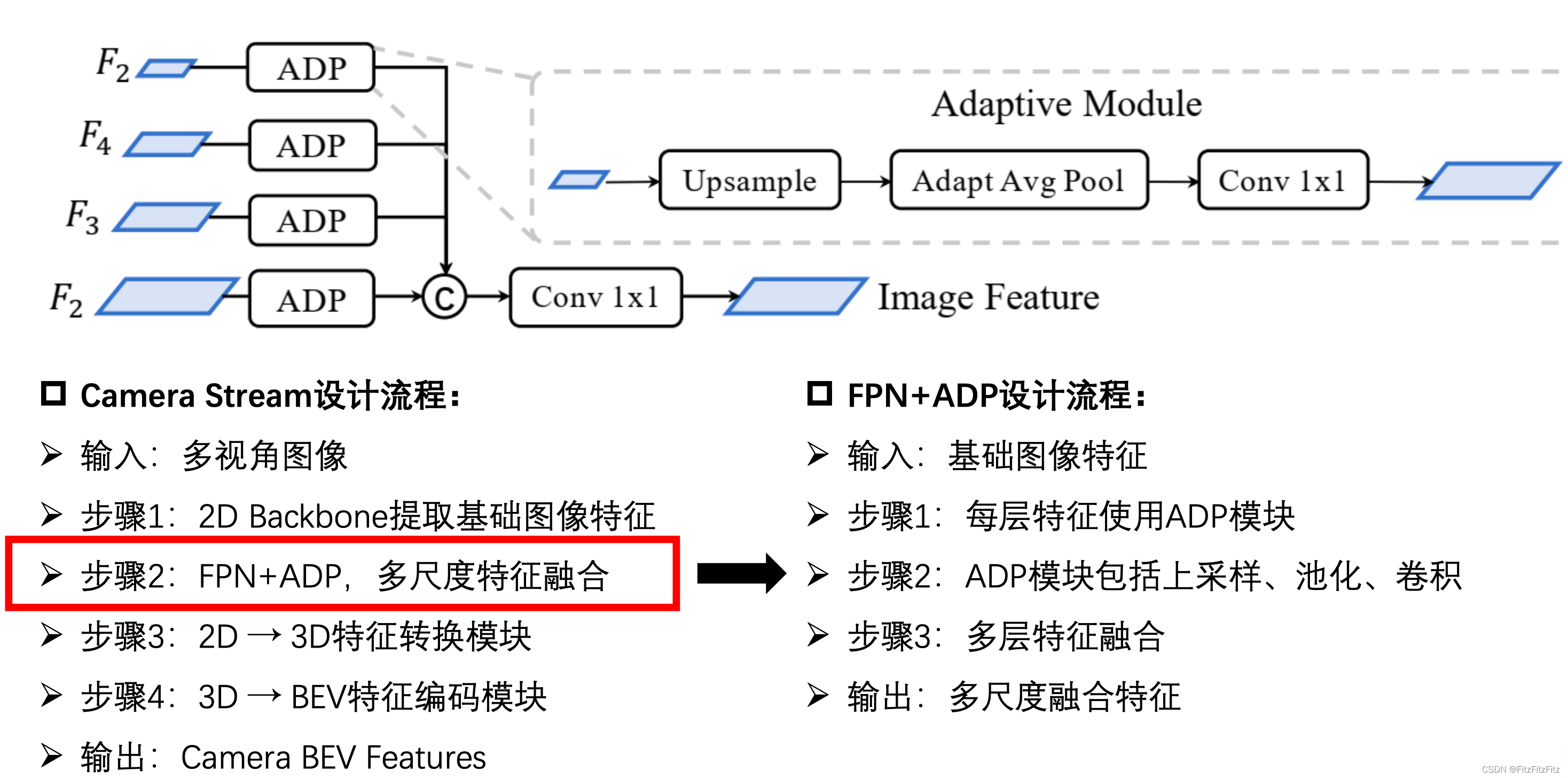
FPN大家都很熟悉,就是特征金字塔。但是这里还是贴一些来自GPT的废话
在Bird’s Eye View (BEV) 算法中使用的特征金字塔网络(FPN, Feature Pyramid Network)是一种常见的深度学习架构,它用于多尺度目标检测。FPN通过高效地结合不同分辨率的特征图,增强了模型对各种尺寸目标的检测能力。在BEV应用中,FPN尤为重要,因为它有助于处理来自不同视角(如车载摄像头)的图像数据,并对环境中的各种对象进行准确的空间定位和识别。
FPN在BEV算法中的作用
多尺度特征提取:
FPN能够提供丰富的上下文信息,这对于预测物体在BEV图像中的准确位置至关重要。通过聚合高分辨率的细节信息和低分辨率的上下文信息,FPN增强了算法对物体空间布局的解析能力。
效率与性能的平衡:
通过利用深层和浅层特征,FPN可以在不牺牲计算效率的情况下,提高模型的性能。这在实时或近实时的自动驾驶系统中尤为重要,其中快速和准确的环境感知是必需的。
跨视角特征融合:
在BEV任务中,图像数据可能来自车辆的多个摄像头,覆盖不同的视角。FPN有助于整合这些多视角数据,生成一个统一的、高度信息化的BEV图像,从而改善场景理解和决策制定。
很明显经过FPN之后的各层会给出不同尺度的输出,这显然是不利于我们对特征进行融合的。因此这里ADP的作用其实就是对齐FPN的各层:
通过上采样来使f2,f3,f4,f5的宽高统一,
再通过自适应池化(adaptive pooling)来调整特征图的尺寸,以适应网络中不同的需求。
例如,在某些情况下,可能需要将所有特征图统一到一个固定的尺寸,以便进行特定的处理或操作,如分类层的输入。自适应池化通过自动计算所需的池化核大小和步长,能够从输入特征图中生成固定尺寸的输出,这在实际应用中提供了极大的灵活性。
1*1的卷积 来进行通道调整和特征融合增强
通道调整
即使通过上采样后的特征图在空间尺寸上与高层特征图匹配,它们的通道数可能仍然不同。例如,低层可能有512个通道,而更高层可能只有256个通道。1x1卷积可以有效地调整这些通道数,使特征图在通道维度上也能匹配,便于进行后续的特征融合。
特征融合
通过1x1卷积不仅可以调整通道数,还可以在特征层之间实现更深层次的信息混合。这种卷积操作可以帮助模型学习如何在不同特征层之间有效地组合信息,从而产生更具代表性和区分力的特征。