1. 背景
市面上的静态代码检测SAST工具越来越多,除了业界比较知名的Coverity、Fortify、CheckMax,还有CodeQL、SonarQube、CppCheck等,国内也涌现了一大波检测工具,如鸿渐SAST、奇安信代码卫士、北大Cobot、酷德啄木鸟等,市场上能叫上名的SAST工具约200+种。不同SAST工具检测能力差异较大,比如支持的扫描规则,扫描规则能力。如何有效衡量这些检测工具规则扫描能力,给企业选型SAST工具提供参考,成为了一项业界难题。如果没有能力衡量这些工具,就很难了解它们的优点和缺点,并将它们相互比较。
2. OWASP Benchmark 概览
OWASP Benchmark项目是一个 Java 测试套件,旨在自动化评估软件漏洞检测工具的准确性、覆盖范围和速度。在下文的介绍中,OWASP Benchmark也被称为OWASP 基准项目。
OWASP 基准项目是一个完全可运行的开源 Web 应用程序,包含3000左右个测试用例,每个测试用例都映射到特定的 CWE,可以通过任何类型的应用程序安全测试 (AST) 工具进行分析,包括 SAST、DAST(如 OWASP ZAP,AWVS)、和 IAST 工具。基准测试的所有漏洞实际上都是可利用的,因此它对任何类型的应用程序漏洞检测工具都是公平的测试。 Benchmark 还包括数十个用于众多开源和商业 AST 工具的记分卡生成器(ScoreCard),并且支持的工具集一直在增长。
3. 发布历史
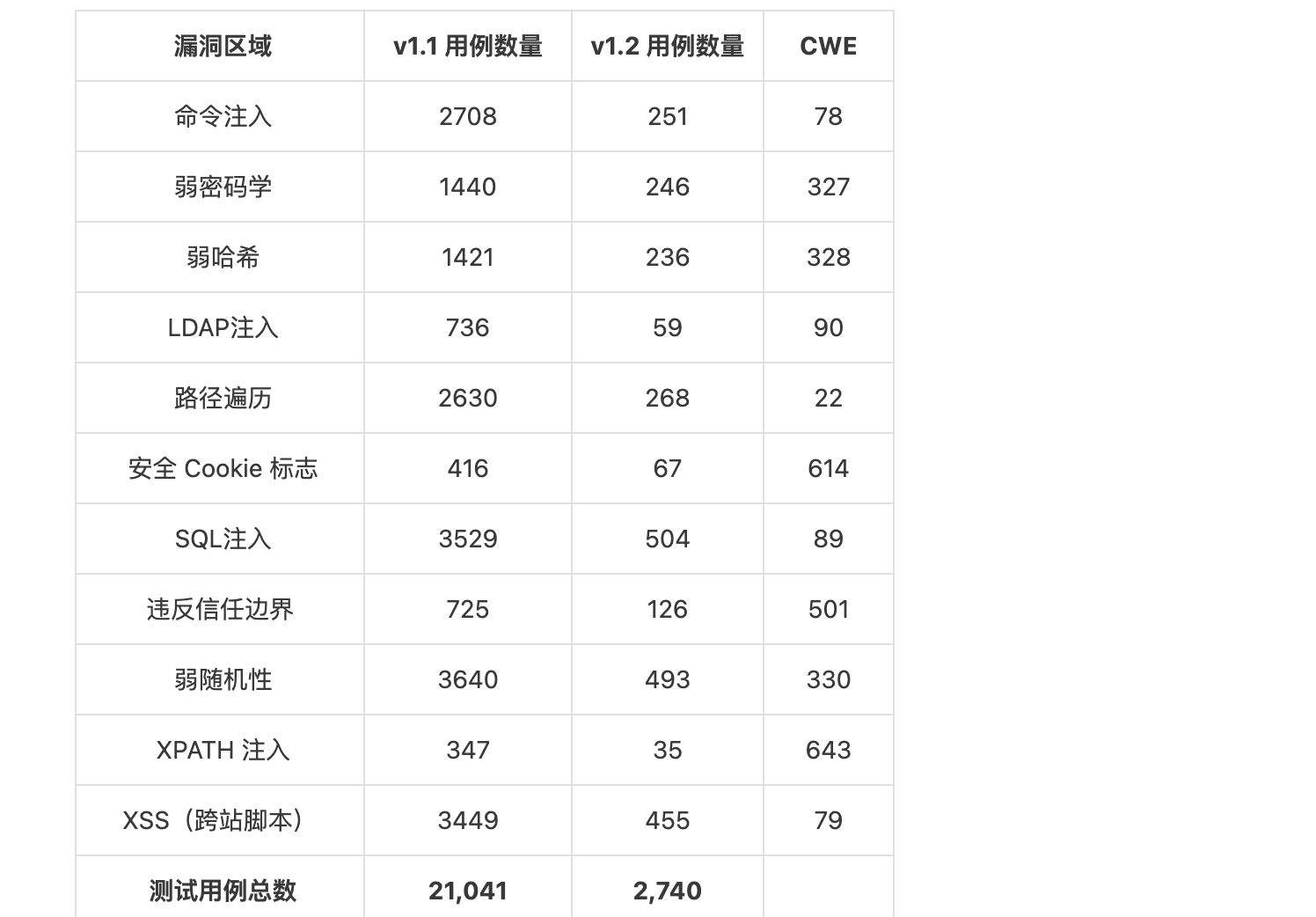
- 1.2版本于2016年6月5日首次发布(1.2beta版本于2015年8月15日)。从那时起,v1.2 版本不断进行调整,用例做了大量简化,拥有 2,740 个测试用例。
- 基准测试的 1.1 版于 2015 年 5 月 23 日发布。1.1 版在之前版本的基础上进行了改进,确保每个漏洞区域都存在真阳性和假阳性,拥有21,041 个测试用例。
- Benchmark 1.0 版本于 2015 年 4 月 15 日发布,拥有 20,983 个测试用例。
4. Benchmark 中具体有什么?
4.1. 用例代码
Benchmark 是一个 Java Maven 项目。它的主要组成部分是数千个测试用例(例如,BenchmarkTest00001.java),每个测试用例都是包含单个漏洞(真阳性或假阳性)的单个 Java servlet。目前,这些漏洞涉及大约十几个不同的 CWE。
4.2. 预期结果文件 Expectedresults.csv
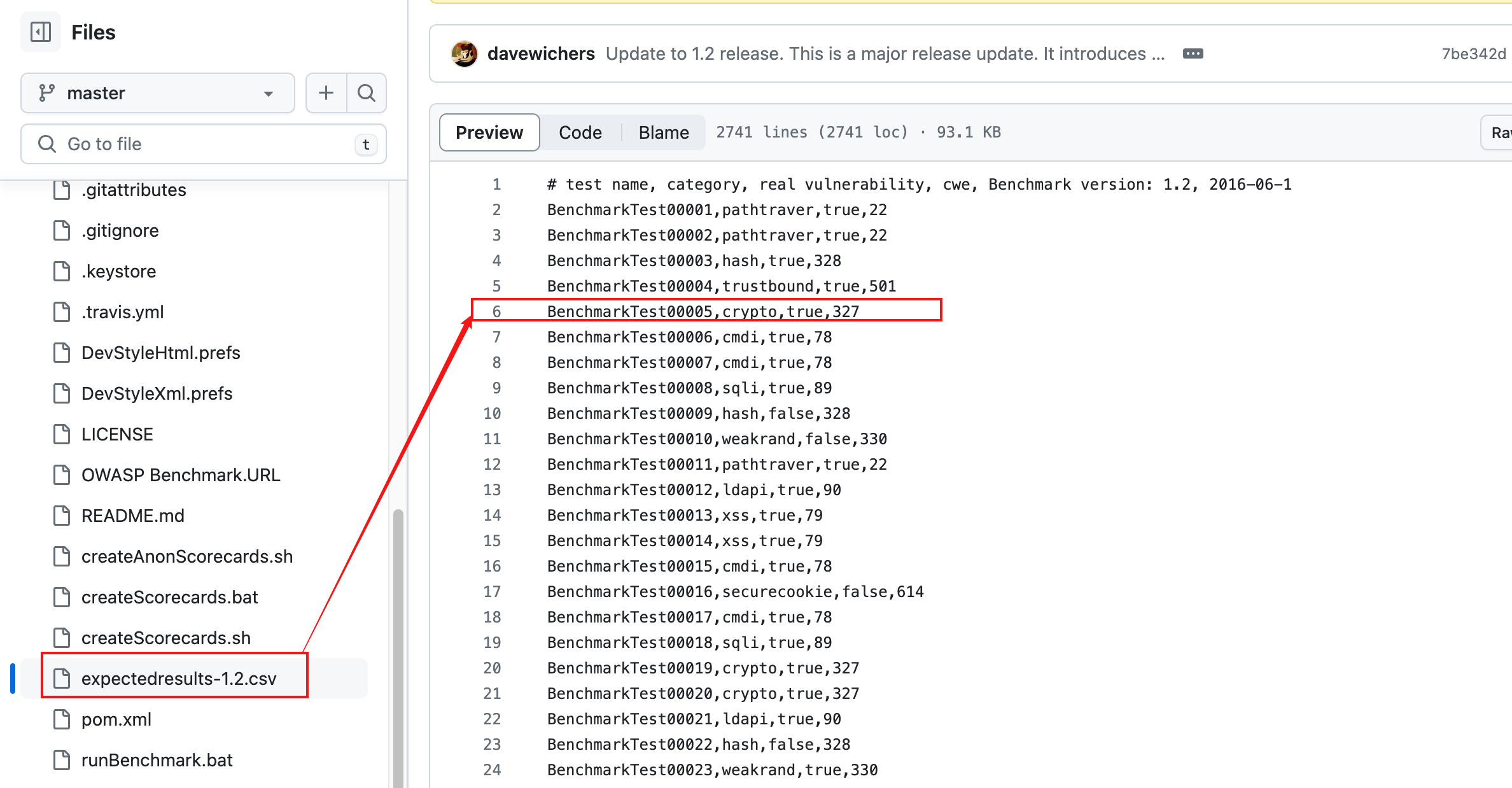
Expectedresults.csv 随基准测试的每个版本一起发布(例如,expectedresults-1.2.csv),它专门列出了每个测试用例的预期结果。对于 1.2 版基准测试,该文件的截图如下所示:
注解:
- 第6行表明第6个测试用例是加密测试用例(使用弱加密算法),这是一个真正的漏洞(而不是误报),并且此问题映射到 CWE 327。它还表明此预期结果文件适用于 Benchmark 版本 1.2(2016 年 6 月 1 日发布)。
- 对于基准测试中的数万个测试用例,此文件中的每一个都有一行。每次发布新版本的基准测试时,都会生成一个新的相应结果文件,并且每个测试用例在一个版本与下一个版本之间都可以完全不同。
4.3. 配套工具
Benchmark 还附带了一堆不同的实用程序、命令和预打包的开源安全分析工具,所有这些都可以通过 Maven 目标执行,包括:
- 将针对基准运行的开源漏洞检测工具
- 记分卡生成器,它为您拥有结果文件的每个工具计算记分卡。
5. 我们可以使用基准做什么?
- 编译Benchmark项目中的所有软件(例如mvn编译)
- 针对 Benchmark 测试用例代码运行静态漏洞分析工具 (SAST)
- 使用动态应用程序安全测试工具 (DAST) 扫描正在运行的基准版本
- 提供了有关如何运行它的说明,并为有结果的每个工具生成记分卡
6. 参考
[1] https://owasp.org/www-project-benchmark/
[2] https://github.com/OWASP-Benchmark/BenchmarkJava