Spring AI默认gpt版本源码探究
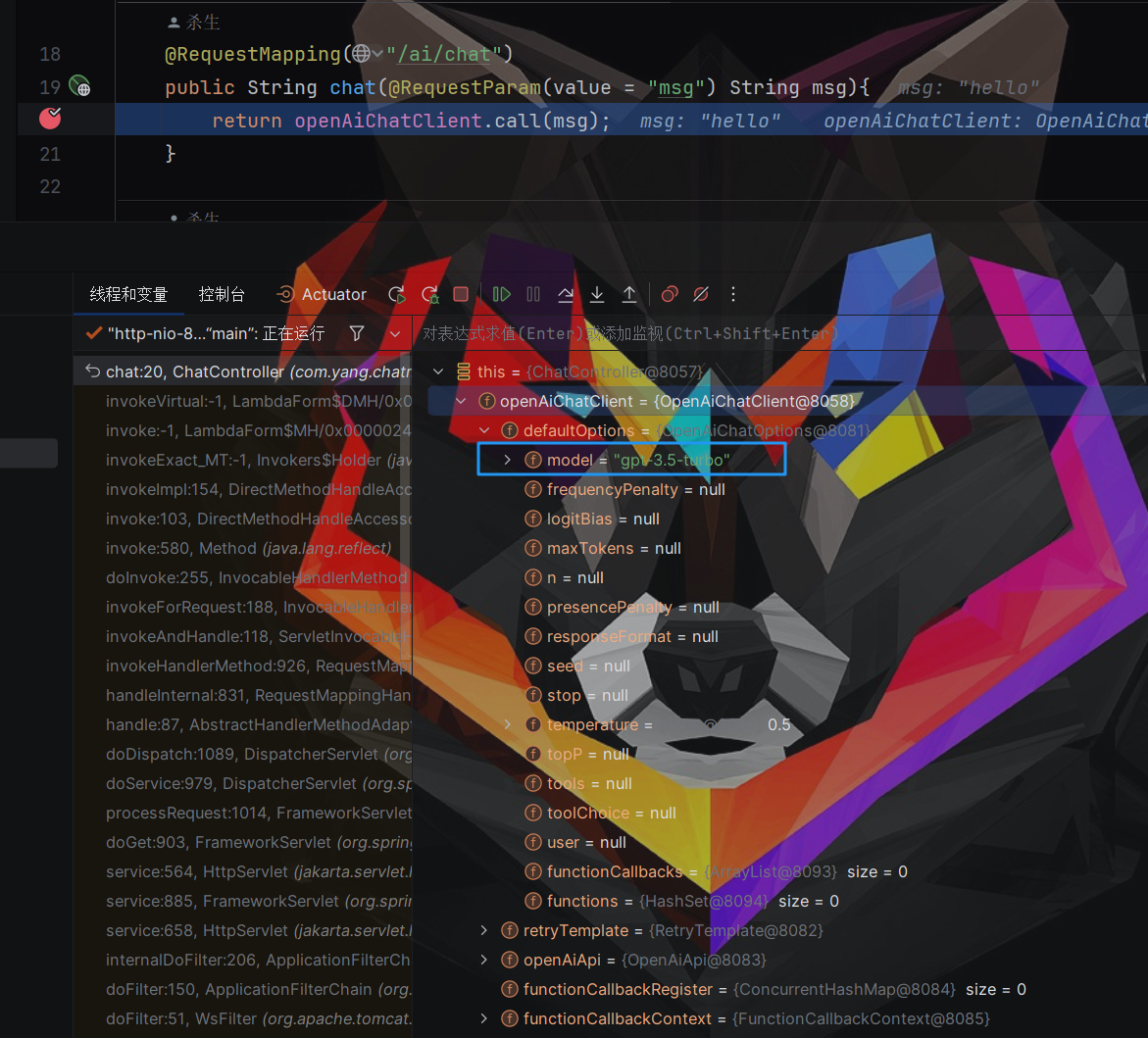
调试代码
- 通过调试,可以看到默认mdel为gpt-3.5-turbo
源码探究
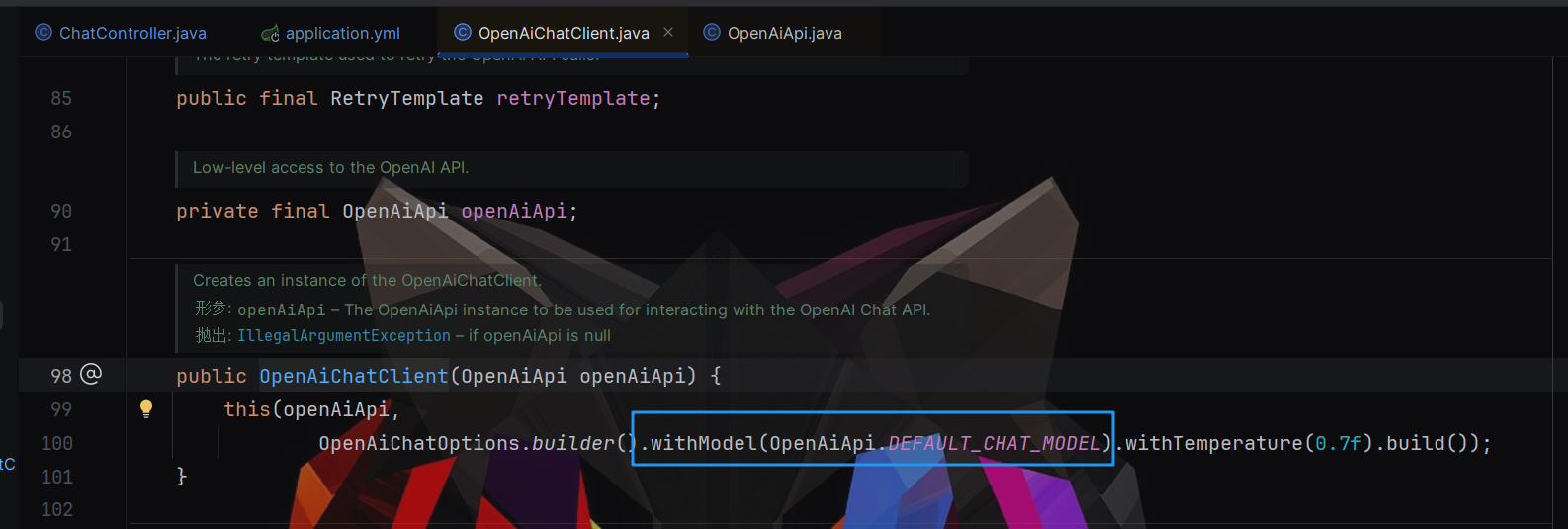
- 进入OpenAiChatClient类查看具体的代码信息

- 可以看到如下代码,在有参构造方法中可以看到,model默认使用
OpenAiApi.DEFAULT_CHAT_MODELpublic class OpenAiChatClient extends AbstractFunctionCallSupport<OpenAiApi.ChatCompletionMessage, OpenAiApi.ChatCompletionRequest, ResponseEntity<OpenAiApi.ChatCompletion>> implements ChatClient, StreamingChatClient { private static final Logger logger = LoggerFactory.getLogger(OpenAiChatClient.class); private OpenAiChatOptions defaultOptions; public final RetryTemplate retryTemplate; private final OpenAiApi openAiApi; public OpenAiChatClient(OpenAiApi openAiApi) { this(openAiApi, OpenAiChatOptions.builder().withModel(OpenAiApi.DEFAULT_CHAT_MODEL).withTemperature(0.7F).build()); } }
- 继续进入
OpenAiApi类查看DEFAULT_CHAT_MODEL的具体信息,可以看到使用枚举类ChatModel为DEFAULT_CHAT_MODEL赋值
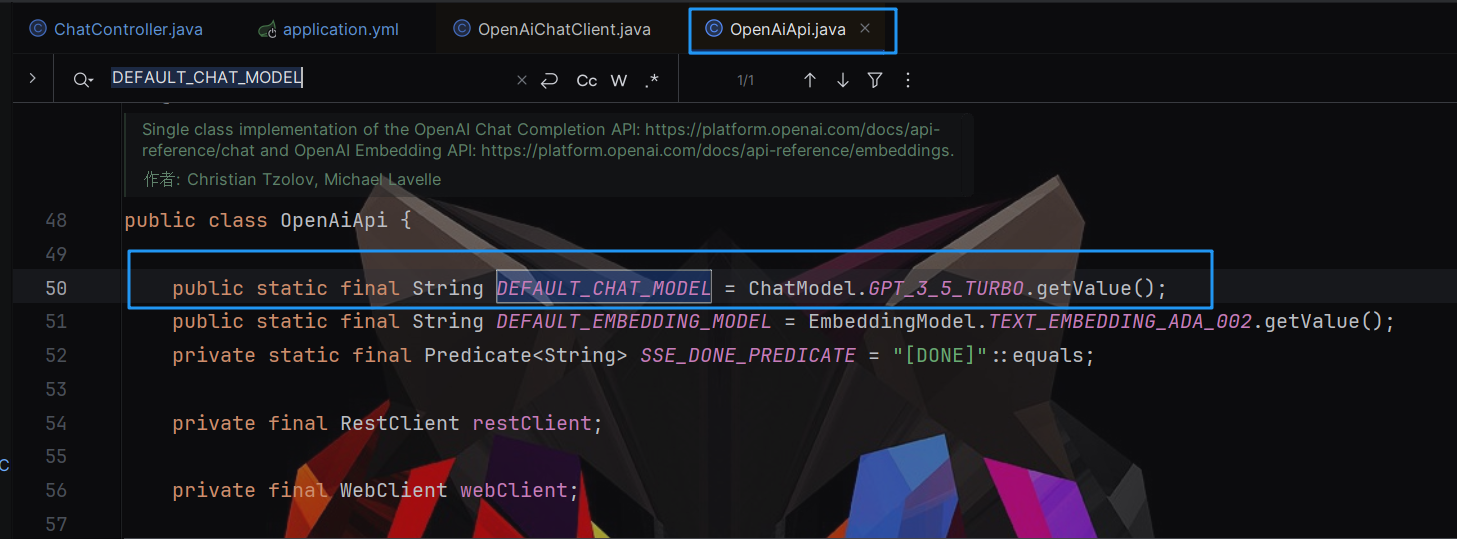
- 点击查看
ChatModel的具体内容,可以看到这里列举了常用的gpt版本
public enum ChatModel {
/**
* (New) GPT-4 Turbo - latest GPT-4 model intended to reduce cases
* of “laziness” where the model doesn’t complete a task.
* Returns a maximum of 4,096 output tokens.
* Context window: 128k tokens
*/
GPT_4_0125_PREVIEW("gpt-4-0125-preview"),
/**
* Currently points to gpt-4-0125-preview - model featuring improved
* instruction following, JSON mode, reproducible outputs,
* parallel function calling, and more.
* Returns a maximum of 4,096 output tokens
* Context window: 128k tokens
*/
GPT_4_TURBO_PREVIEW("gpt-4-turbo-preview"),
/**
* GPT-4 with the ability to understand images, in addition
* to all other GPT-4 Turbo capabilities. Currently points
* to gpt-4-1106-vision-preview.
* Returns a maximum of 4,096 output tokens
* Context window: 128k tokens
*/
GPT_4_VISION_PREVIEW("gpt-4-vision-preview"),
/**
* Currently points to gpt-4-0613.
* Snapshot of gpt-4 from June 13th 2023 with improved
* function calling support.
* Context window: 8k tokens
*/
GPT_4("gpt-4"),
/**
* Currently points to gpt-4-32k-0613.
* Snapshot of gpt-4-32k from June 13th 2023 with improved
* function calling support.
* Context window: 32k tokens
*/
GPT_4_32K("gpt-4-32k"),
/**
*Currently points to gpt-3.5-turbo-0125.
* model with higher accuracy at responding in requested
* formats and a fix for a bug which caused a text
* encoding issue for non-English language function calls.
* Returns a maximum of 4,096
* Context window: 16k tokens
*/
GPT_3_5_TURBO("gpt-3.5-turbo"),
/**
* (new) The latest GPT-3.5 Turbo model with higher accuracy
* at responding in requested formats and a fix for a bug
* which caused a text encoding issue for non-English
* language function calls.
* Returns a maximum of 4,096
* Context window: 16k tokens
*/
GPT_3_5_TURBO_0125("gpt-3.5-turbo-0125"),
/**
* GPT-3.5 Turbo model with improved instruction following,
* JSON mode, reproducible outputs, parallel function calling,
* and more. Returns a maximum of 4,096 output tokens.
* Context window: 16k tokens.
*/
GPT_3_5_TURBO_1106("gpt-3.5-turbo-1106");
public final String value;
ChatModel(String value) {
this.value = value;
}
public String getValue() {
return value;
}
}
model配置
- 官方的
OpenAiApi.ChatModel列举了常用gpt 版本,我们可以在配置model时直接使用,避免手动输入的错误 - 当然application.yaml配置时还需要使用字符串定义
@RequestMapping("/ai/chat5")
public Object chatStream(@RequestParam(value = "msg") String msg){
Flux<ChatResponse> flux = openAiChatClient.stream(new Prompt(msg,
OpenAiChatOptions.builder()
.withModel(OpenAiApi.ChatModel.GPT_4_VISION_PREVIEW.getValue()) //gpt版本 "gpt-4-vision-preview"
.withTemperature(0.5F) //温度高,回答创新型越高;越低,越准确
.withMaxTokens(4096) //显示最大token
.build()
)
);
flux.toStream().forEach(chatResponse -> {
System.out.print(chatResponse.getResult().getOutput().getContent());
});
return flux.collectList();
}