HDFS分布式文件系统
分布式:将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情
单机模式
厨房里只有一个人,这个人既要买菜,又要切菜,还要炒菜,效率低。
分布式模式
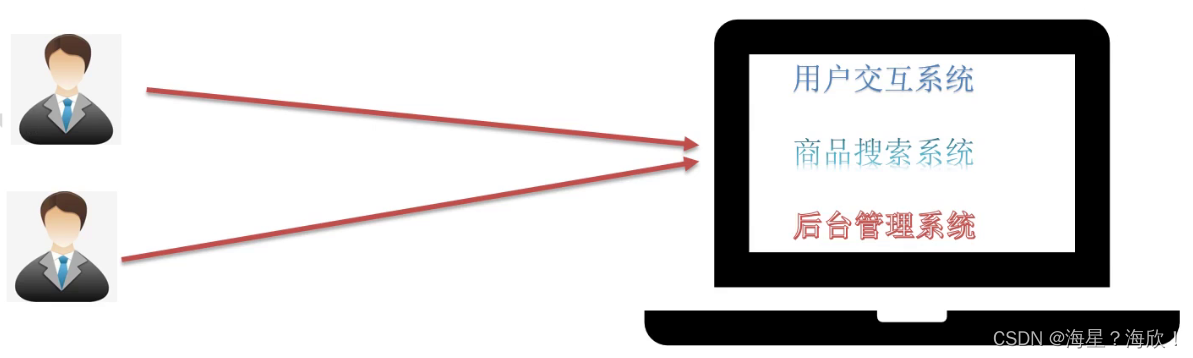
厨房里有三个人,一个人买菜,一个切菜,一个炒菜,效率提高了。
问题:
1,用户交互系统的压力大,都要访问它
2,单点故障问题
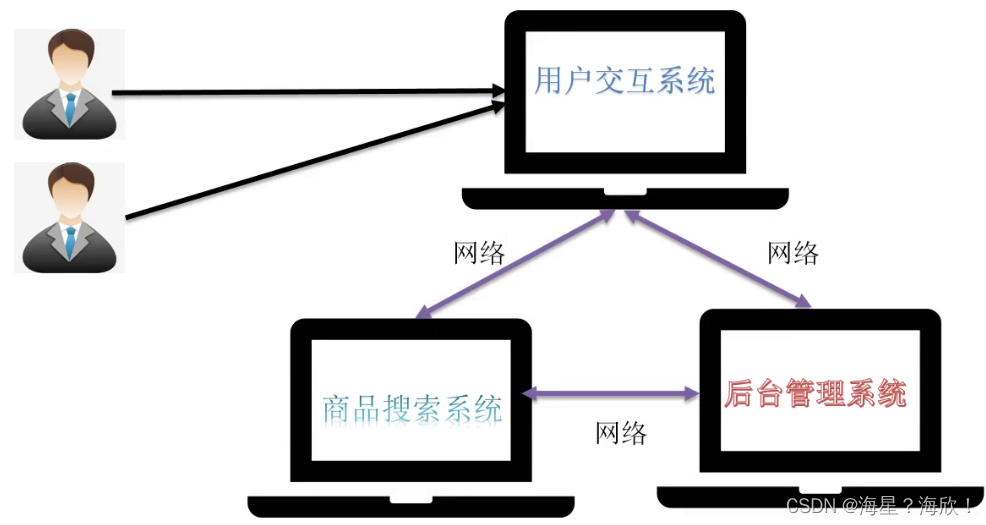
集群
解决上面分布式的问题,引入集群概念
集群:一组独立的计算机系统构成的一多处理器系统,它们之间通过网络实现进程间的通信,让若干个计算机联合起来工作,可以并行,也可以是备份的
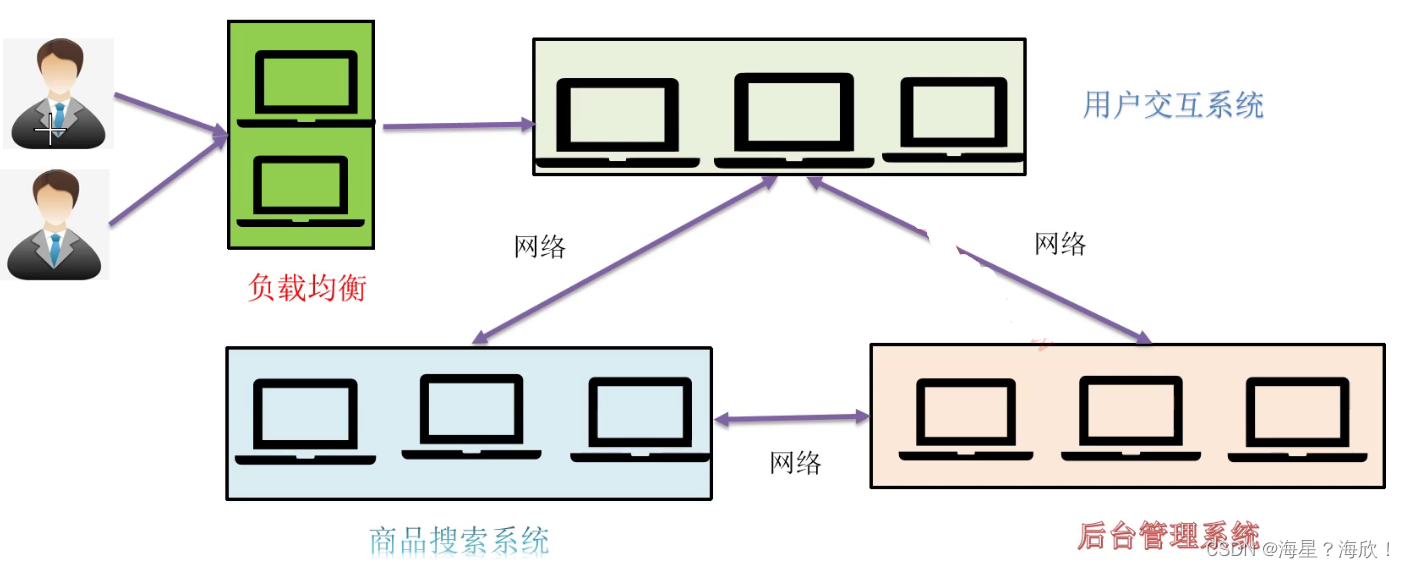
集群相比于分布式方法:备份(多台服务器)
分布式和集群的区别:
分布式:分布式的主要工作是分解任务,将职能拆解,多个人在一起做不同的事
集群:集群主要是将同一个业务,部署在多个服务器,多个人在一起做同样的事
Hadoop框架介绍
Hadoop是用Java语言实现的开源软件框架,是一个储存和计算的大规模数据的软件平台
Hadoop的核心组件:
- HDFS(交叉式文件系统):解决海量数据存储
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
- YARN(作业调度和集群资源管理框架):解决资源任务调度
广义的Hadoop:Hadoop生态圈,包括LInux、zookeeper、hive、spark等等
版本
2.x版本,开源社区版
Hadoop1.x与Hadoop2.x的区别:
- 1.x中mapreduce(数据计算、资源管理)、hdfs(数据存储问题,自动备份)
- 2.x中mapreduce(数据计算)、yarn(资源管理)、hdfs(数据存储问题,自动备份)因为mapreduce压力减轻了,从而更稳定
内部结构
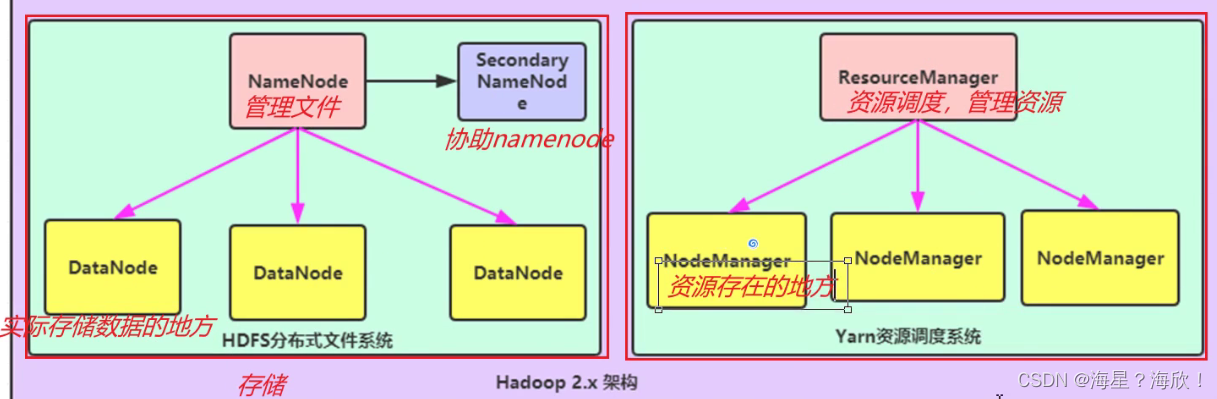
Hadoop集群包括两个集群:HDFS集群和YARN集群,两者逻辑上分离(一个存储,一个管理),但物理上常在一起(指在同一个服务器上)
HDFS模块:
- NameNode:集群中的主节点,用于管理集群中的各种数据。存储元数据
- SecondaryNameNode:用于Hadoop当中元数据(描述数据的数据)信息的辅助管理。(移动硬盘,备份元数据)
- DataNode:集群中的从节点,存储集群中的各种数据
YARN模块:
- ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
- NodeManager:负责执行主节点分配的任务,实际执行任务
mapreduce模块:
mapreduce计算需要的数据和产生的结果需要HDFS来进行存储。—mapreduce慢的主要原因(读磁盘慢)
mapreduce的运行需要yarn集群来提供资源调度
mapreduce是一个计算框架。map(先分布式计算)、reduce(将分布式计算的结果合并)
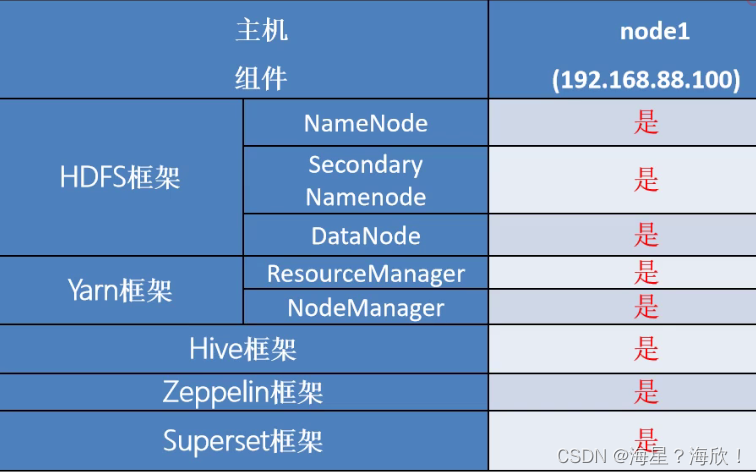
单机模式:
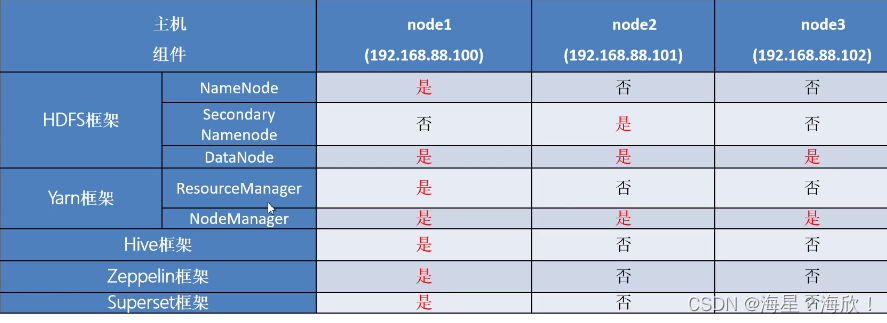
集群模式,角色分配:

![[iHooya]1月15日寒假班作业解析](https://img-blog.csdnimg.cn/c430bcda67d442ba8c8b982909add71e.png#pic_center)