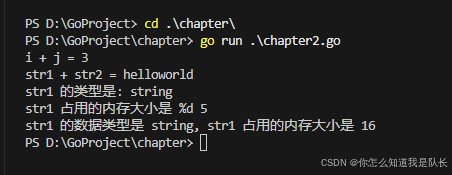
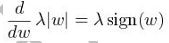此处重点讨论在特定条件下,重建场景的三维结构和相机的三维姿态的一些应用实现。下面是完整投影公式最通用的表示方式。
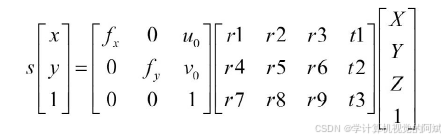
在上述公式中,可以了解到,真实物体转为平面之后,s系数丢失了,因而无法会的三维坐标,而s系数其实是与直接距离Z相关,实际上,如果知道物体到相机成像平面距离,相机的内参、外参就可以获得空间坐标:

1. 相机标定
相机标定就是设置相机各种参数(即投影公式中的内参,外参)的过程。当然也可以使用相机厂家提供的技术参数,利用正确的相机标定方法,即可得到精确的标定信息。
相机标定的基本原理:确定场景中一系列点的三维坐标并拍摄这个场景,然后观测这些点
在图像上投影的位置。有了足够多的三维点和图像上对应的二维点,就可以根据投影方程推断出
准确的相机参数。
(1)一种方法是对一个包含大量三维点的场景取像(一些车辆在出场会使用)。
(2)更实用的做法是从不同的视角为一些三维点拍摄多个照片。这种方法相对比较简单,但是它除了需要计算相机本身的参数,还需要计算每个相机视图的位置,OpenCV 推荐使用国际象棋棋盘的图案生成用于标定的三维场景点的集合。

这个图案在每个方块的角点位置创建场景点;由于图案是平面的,可以假设棋盘位于Z=0 且X 和Y 的坐标轴与网格对齐的位置。
// 1. 输出图像角点的向量
std::vector<cv::Point2f> imageCorners;
// 棋盘内部角点的数量
cv::Size boardSize(7,5);
// 获得棋盘角点
bool found = cv::findChessboardCorners(
image, // 包含棋盘图案的图像
boardSize, // 图案的尺寸
imageCorners); // 检测到的角点列表
// 2. 画出角点
cv::drawChessboardCorners(image, boardSize,
imageCorners, found); // 找到的角点连接角点的线条的次序,就是角点在向量中存储的次序。在进行标定前,需要指定相关的三维点。指定这些点时可自由选择单位(例如厘米或英寸),不过最简单的办法是将方块的边长指定为一个单位。这样第一个点的坐标就是(0, 0, 0)(假设棋盘的纵深坐标为Z = 0),第二个点的坐标是(1, 0, 0),最后一个点的坐标是(6, 4, 0)。这个图案共有35 个点;若要进行精确的标定,这些点是远远不够的。为了得到更多的点,需要从不同的视角对同一个标定图案拍摄更多的照片。可以在相机前移动图案,也可以在棋盘周围移动相机。从数学的角度看,这两种方法是完全等效的。OpenCV 的标定函数假定由标定图案确定坐标系,并计算相机相对于坐标系的旋转量和平移量。
// 打开棋盘图像,提取角点
int CameraCalibrator::addChessboardPoints(
const std::vector<std::string> & filelist, // 文件名列表
cv::Size & boardSize) { // 标定面板的大小
// 棋盘上的角点
std::vector<cv::Point2f> imageCorners;
std::vector<cv::Point3f> objectCorners;
// 场景中的三维点:
// 在棋盘坐标系中,初始化棋盘中的角点
// 角点的三维坐标(X,Y,Z)= (i,j,0)
for (int i=0; i<boardSize.height; i++) {
for (int j=0; j<boardSize.width; j++) {
objectCorners.push_back(cv::Point3f(i, j, 0.0f));
}
}
// 图像上的二维点:
cv::Mat image; // 用于存储棋盘图像
int successes = 0;
// 处理所有视角
for (int i=0; i<filelist.size(); i++) {
// 打开图像
image = cv::imread(filelist[i],0);
// 取得棋盘中的角点
bool found = cv::findChessboardCorners(
image, // 包含棋盘图案的图像
boardSize, // 图案的大小
imageCorners); // 检测到角点的列表
// 取得角点上的亚像素级精度
if (found) {
cv::cornerSubPix(image, imageCorners,
cv::Size(5,5), // 搜索窗口的半径
cv::Size(-1,-1),
cv::TermCriteria( cv::TermCriteria::MAX_ITER +
cv::TermCriteria::EPS,30, // 最大迭代次数
0.1)); // 最小精度
// 如果棋盘是完好的,就把它加入结果
if (imageCorners.size() == boardSize.area()) {
// 加入从同一个视角得到的图像和场景点
addPoints(imageCorners, objectCorners);
successes++;
}
}
// 如果棋盘是完好的,就把它加入结果
if (imageCorners.size() == boardSize.area()) {
// 加入从同一个视角得到的图像和场景点
addPoints(imageCorners, objectCorners);
successes++;
}
}
return successes;
}

处理完足够数量的棋盘图像后(这时就有了大量的三维场景点/二维图像点的对应关系),就可以开始计算标定参数了:
// 返回重投影误差
double CameraCalibrator::calibrate(cv::Size &imageSize) {
// 输出旋转量和平移量
std::vector<cv::Mat> rvecs, tvecs;
// 开始标定
return calibrateCamera(objectPoints, // 三维点
imagePoints, // 图像点
imageSize, // 图像尺寸
cameraMatrix, // 输出相机矩阵
distCoeffs, // 输出畸变矩阵
rvecs, tvecs, // Rs、Ts
flag); // 设置选项
}
//根据经验,10~20 个棋盘图像就足够了,但是这些图像的深度和拍摄视角必须不同用刚标定的相机拍摄的所有图像,在标定类中增加了一个额外畸变矫正的方法:
// 去除图像中的畸变(标定后)
cv::Mat CameraCalibrator::remap(const cv::Mat &image) {
cv::Mat undistorted;
if (mustInitUndistort) { // 每个标定过程调用一次
cv::initUndistortRectifyMap(
cameraMatrix, // 计算得到的相机矩阵
distCoeffs, // 计算得到的畸变矩阵
cv::Mat(), // 可选矫正项(无)
cv::Mat(), // 生成无畸变的相机矩阵
image.size(), // 无畸变图像的尺寸
CV_32FC1, // 输出图片的类型
map1, map2); // x 和y 映射功能
mustInitUndistort= false;
}
// 应用映射功能
cv::remap(image, undistorted, map1, map2,
cv::INTER_LINEAR); // 插值类型
return undistorted;
}
2. 相机姿态还原
标定后,相机就可以用来构建照片与现实场景的对应关系。如果一个物体的三维结构是已知的,就能得到它在相机传感器上的成像情况。如果该方程中的大多数项目是已知的,利用若干张照片,就可以计算出其他元素(二维或三维)的值。在已知三维结构的情况下,计算出相机的姿态。
// 根据三维/二维点得到相机姿态
cv::Mat rvec, tvec;
cv::solvePnP(
objectPoints, imagePoints, // 对应的三维/二维点
cameraMatrix, cameraDistCoeffs, // 标定
rvec, tvec); // 输出姿态
// 转换成三维旋转矩阵
cv::Mat rotation;
cv::Rodrigues(rvec, rotation);本质是求解刚体变换(旋转和平移),这就是透视n 点定位(Perspective-n-Point,PnP)问题,把物体坐标转换到以相机为中心的坐标系上(即以焦点为坐标原点)。
在OpenCV 中,cv::viz 是一个基于可视化工具包(Visualization Toolkit,VTK)的附加模块。它是一个强大的三维计算机视觉框架,可以创建虚拟的三维环境,并添加各种物体。它会创建可视化的窗口,用来显示从特定视角观察到的虚拟环境。
// 1 创建viz 窗口
cv::viz::Viz3d visualizer("Viz window");
visualizer.setBackgroundColor(cv::viz::Color::white());
// 2 创建一个虚拟相机
cv::viz::WCameraPosition cam(
cMatrix, // 内部参数矩阵
image, // 平面上显示的图像
30.0, // 缩放因子
cv::viz::Color::black());
// 在环境中添加虚拟相机
visualizer.showWidget("Camera", cam);
// 3 用长方体表示虚拟的长椅
cv::viz::WCube plane1(cv::Point3f(0.0, 45.0, 0.0),
cv::Point3f(242.5, 21.0, -9.0),
true, // 显示线条框架
cv::viz::Color::blue());
plane1.setRenderingProperty(cv::viz::LINE_WIDTH, 4.0);
cv::viz::WCube plane2(cv::Point3f(0.0, 9.0, -9.0),
cv::Point3f(242.5, 0.0, 44.5),
true, // 显示线条框架
cv::viz::Color::blue());
plane2.setRenderingProperty(cv::viz::LINE_WIDTH, 4.0);
// 4 把虚拟物体加入到环境中
visualizer.showWidget("top", plane1);
visualizer.showWidget("bottom", plane2);
cv::Mat rotation;
// 将rotation 转换成3×3 的旋转矩阵
cv::Rodrigues(rvec, rotation);
// 移动长椅
cv::Affine3d pose(rotation, tvec);
visualizer.setWidgetPose("top", pose);
visualizer.setWidgetPose("bottom", pose);
最后用一个循环,不断显示可视化窗口。中间暂停1 毫秒,以响应鼠标事件:
// 循环显示
while(cv::waitKey(100)==-1 && !visualizer.wasStopped()) {
visualizer.spinOnce(1, // 暂停1 毫秒
true); // 重绘
}
3. 用标定相机实现三维重建
当从多个视角观察同一个场景时,即使没有三维场景的任何信息,也可以重建三维姿态和结构。我们这次将利用不同视角下图像点之间的关系,计算出三维信息。
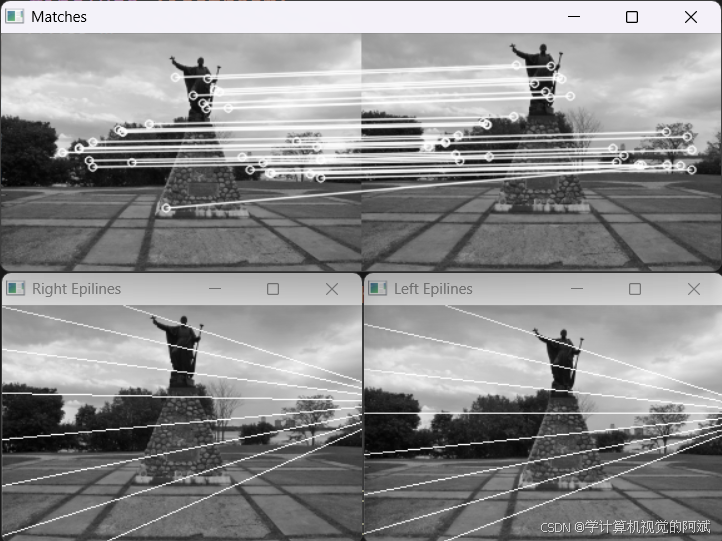
相机的标定参数是能够获取到的,因此可以使用世界坐标系,还可以用它在相机姿态和对应点的位置之间建立一个物理约束。这里引入一个新的数学实体——本质矩阵。简单来说,本质矩阵就是经过标定的基础矩阵。
// 找出image1 和image2 之间的本质矩阵
cv::Mat inliers;
cv::Mat essential = cv::findEssentialMat(points1, points2,
Matrix, // 内部参数 相当于给出了内参
cv::RANSAC,
0.9, 1.0, // RANSAC 方法
inliers); // 提取到的内点将匹配到的同名点调用triangulate 函数,计算三角剖分点的位置:
// 根据旋转量R 和平移量T 构建投影矩阵
cv::Mat projection2(3, 4, CV_64F); // 3×4 的投影矩阵
rotation.copyTo(projection2(cv::Rect(0, 0, 3, 3)));
translation.copyTo(projection2.colRange(3, 4));
// 构建通用投影矩阵
cv::Mat projection1(3, 4, CV_64F, 0.); // 3×4 的投影矩阵
cv::Mat diag(cv::Mat::eye(3, 3, CV_64F));
diag.copyTo(projection1(cv::Rect(0, 0, 3, 3)));
// 用于存储内点
std::vector<cv::Vec2d> inlierPts1;
std::vector<cv::Vec2d> inlierPts2;
// 创建输入内点的容器,用于三角剖分
int j(0);
for (int i = 0; i < inliers.rows; i++) {
if (inliers.at<uchar>(i)) {
inlierPts1.push_back(cv::Vec2d(points1[i].x, points1[i].y));
inlierPts2.push_back(cv::Vec2d(points2[i].x, points2[i].y));
}
}
// 矫正并标准化图像点
std::vector<cv::Vec2d> points1u;
cv::undistortPoints(inlierPts1, points1u,
cameraMatrix, cameraDistCoeffs);
std::vector<cv::Vec2d> points2u;
cv::undistortPoints(inlierPts2, points2u,
cameraMatrix, cameraDistCoeffs);
// 三角剖分
std::vector<cv::Vec3d> points3D;
triangulate(projection1, projection2,
points1u, points2u, points3D); 图中有两个相机,相对的旋转量为R,平移量为T。平移向量T 刚好连接了两个相机的投影中心点。此外,向量x 连接第一个相机的中心点与一个图像点,向量x'连接第二个相机的中心点
与对应的图像点。因为这两个相机之间的移动量是已知的,所以可以用与第二个相机的相对值来表示x 的方向,记为Rx。仔细观察图像点的几何形状,就能发现T、Rx 和x'在同一个平面上。这个关系可用数学公式表示![]()
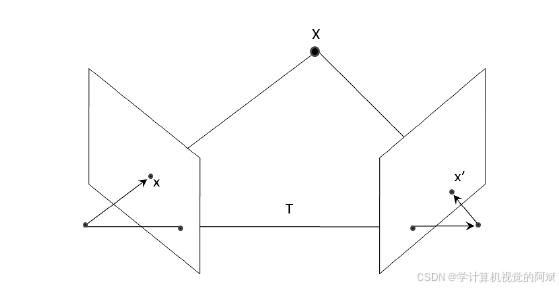
由于噪声和数字化过程的影响,理想情况下应该相交的投影线在实际中一般不会相交。所以用最小二乘法就可以大致找到交点的位置。但这种方法无法重建无穷远处的点,因为它们的齐次坐标的第4 个元素为0,而不是假定的1。还有一点很重要,三维重建只受限于缩放因子。如果要测量实际尺寸,就必须预先确定至少一个长度值,例如两个相机之间的实际距离或者画面中某个物体的实际高度。
4. 计算立体图像的深度
人类用两只眼睛观察三维世界,装上两台相机后,机器也可以看到三维世界,这就是立体视觉。在同一个设备上安装两台相机,让它们观察同一个场景,并且两者之间有固定的基线(即相机之间的距离),就构成了一个立体视觉装置。
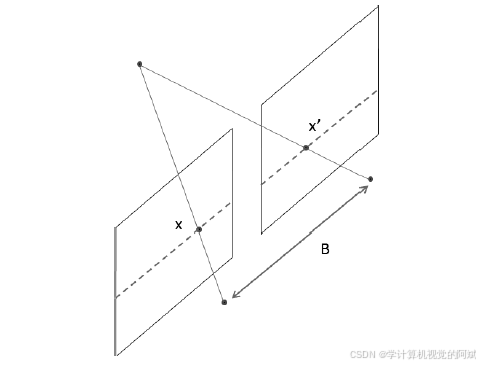
两台相机之间只有水平方向的平移,因此它们的所有对极线都是水平方向的。这意味着所有关联点的y 坐标都是相同的,只需要在一维的线条上寻找匹配项即可。关联点x 坐标的差值则取决于点的深度。无穷远处的点对应图像点的坐标相同,都是(x, y),而它们离装置越近,x 坐标的差值就越大,这时计算差值x -x'(注意要除以s 以符合齐次坐标系),并分离出z 坐标,可得到:![]()
// 1 计算单应变换矫正量
cv::Mat h1, h2;
cv::stereoRectifyUncalibrated(points1, points2,
fundamental,
image1.size(), h1, h2);
// 2 用变换实现图像矫正
cv::Mat rectified1;
cv::warpPerspective(image1, rectified1, h1, image1.size());
cv::Mat rectified2;
cv::warpPerspective(image2, rectified2, h2, image1.size());
// 3 计算视差
cv::Mat disparity;
cv::Ptr<cv::StereoMatcher> pStereo =
cv::StereoSGBM::create(0, // 最小视差
32, // 最大视差
5); // 块的大小
pStereo->compute(rectified1, rectified2, disparity);