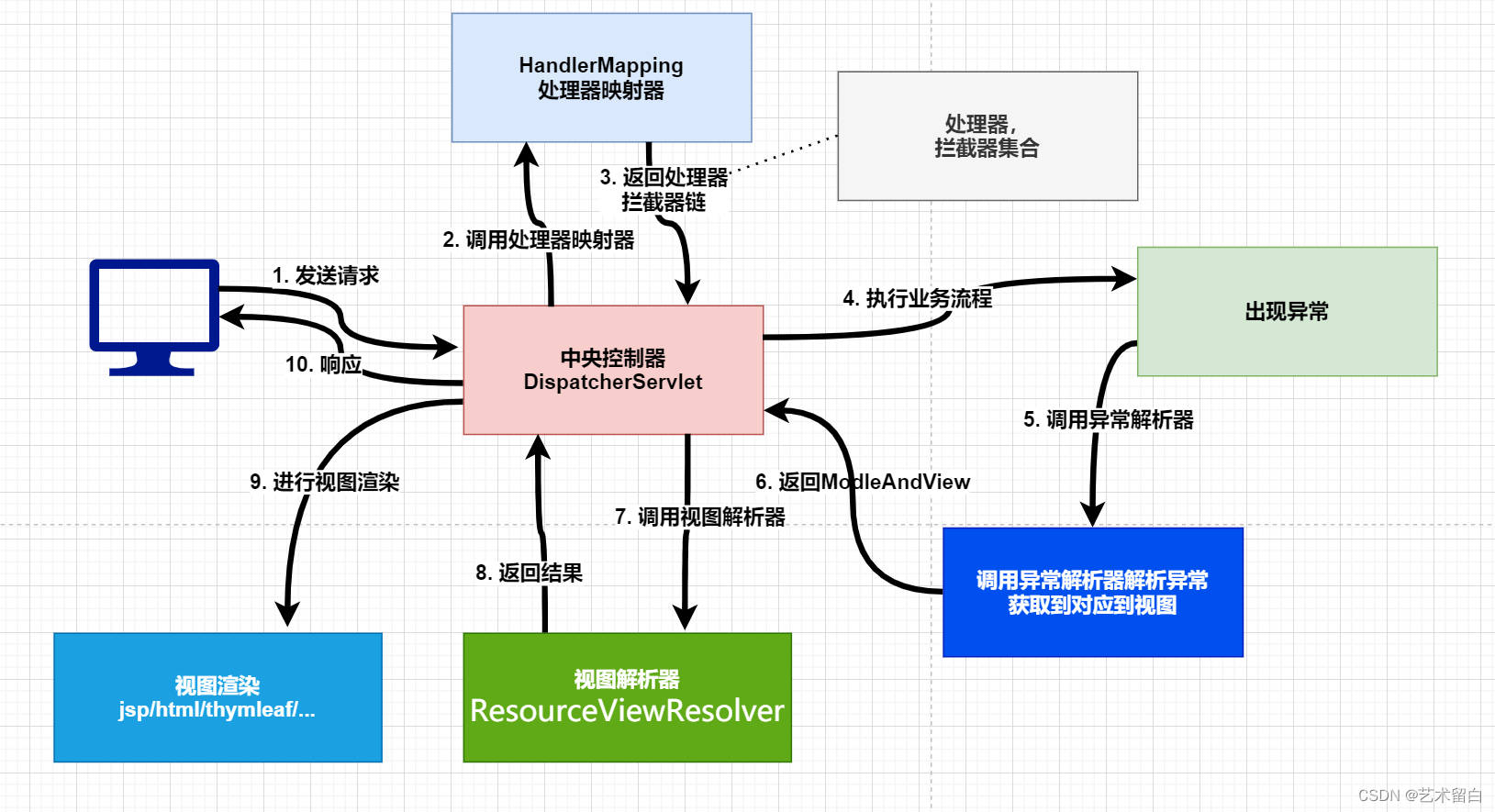
之前,我们分别介绍了边界框、锚框、多尺度目标检测和用于目标检测的数据集。 现在我们已经准备好使用这样的背景知识来设计一个目标检测模型:单发多框检测(SSD) 。该模型简单、快速且被广泛使用。尽管这只是其中一种目标检测模型,但本节中的一些设计原则和实现细节也适用于其他模型。
1. 模型
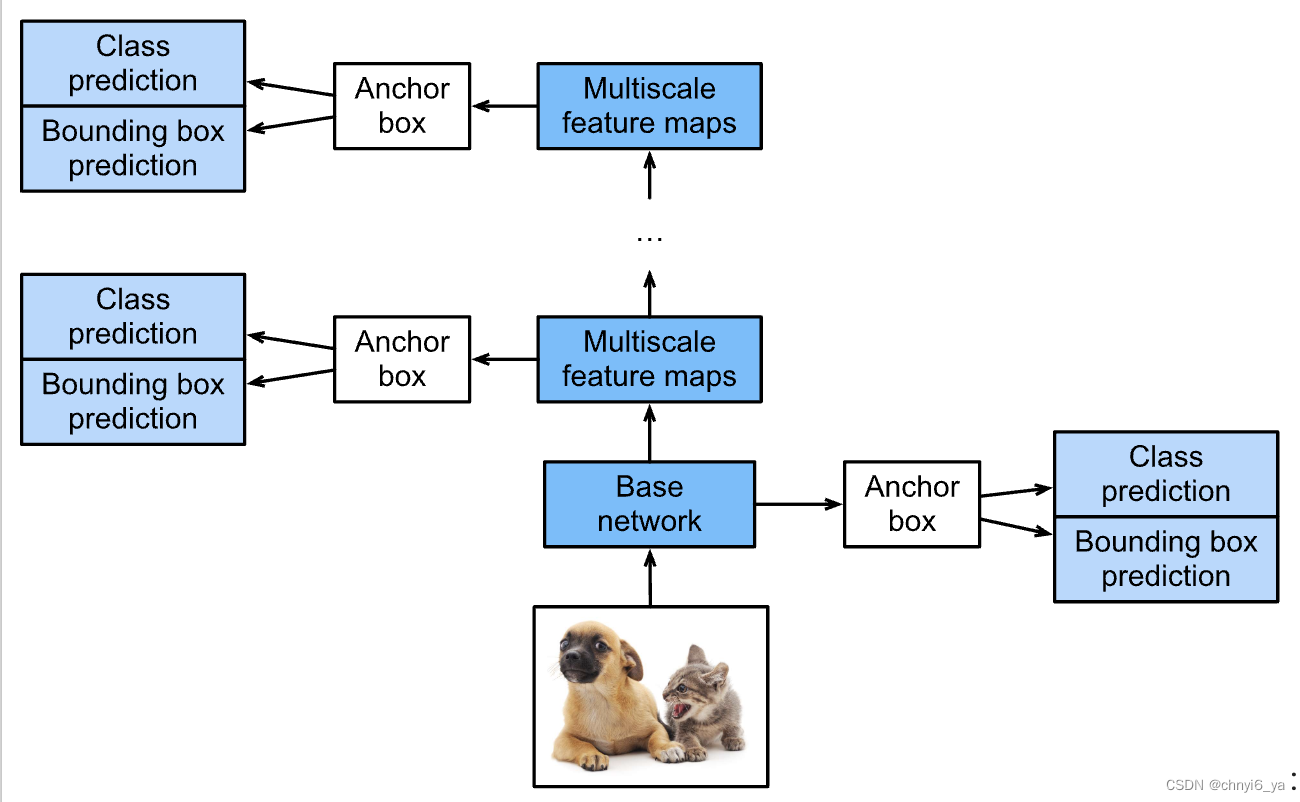
简而言之,通过多尺度特征块,单发多框检测生成不同大小的锚框,并通过预测边界框的类别和偏移量来检测大小不同的目标,因此这是一个多尺度目标检测模型。
2. 类别预测层
设目标类别的数量为 𝑞 。这样一来,锚框有 𝑞+1 个类别,其中0类是背景。 在某个尺度下,设特征图的高和宽分别为 ℎ 和 𝑤 。 如果以其中每个单元为中心生成 𝑎 个锚框,那么我们需要对 ℎ𝑤𝑎 个锚框进行分类。 如果使用全连接层作为输出,很容易导致模型参数过多。 回忆 :numref:sec_nin一节介绍的使用卷积层的通道来输出类别预测的方法, 单发多框检测采用同样的方法来降低模型复杂度。
具体来说,类别预测层使用一个保持输入高和宽的卷积层。 这样一来,输出和输入在特征图宽和高上的空间坐标一一对应。 考虑输出和输入同一空间坐标( 𝑥 、 𝑦 ):输出特征图上( 𝑥 、 𝑦 )坐标的通道里包含了以输入特征图( 𝑥 、 𝑦 )坐标为中心生成的所有锚框的类别预测。 因此输出通道数为 𝑎(𝑞+1) ,其中索引为 𝑖(𝑞+1)+𝑗 ( 0≤𝑗≤𝑞 )的通道代表了索引为 𝑖 的锚框有关类别索引为 𝑗 的预测。
在下面,我们定义了这样一个类别预测层,通过参数num_anchors和num_classes分别指定了 𝑎 和 𝑞 。 该图层使用填充为1的 3×3 的卷积层。此卷积层的输入和输出的宽度和高度保持不变。
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 这个函数是用来预测锚框的类别,参数分别为:输入通道数、锚框数量、类别数量
# 假设香蕉的话就是1类,5种车就是5类
def cls_predictor(num_inputs, num_anchors, num_classes):
# nn.Conv2d函数中第1、2个参数:输入通道数和输出通道数
# 第2个参数是输出通道数是锚框个数*(类别数+1),这里的1代表背景类
# 所以对每一个锚框对应(num_classes + 1)个类别,然后要去预测是哪一类
# 这里用的是卷积,而不是全连接
# kernel_size=3, padding=1表示不会改变输入的高宽
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1)
# num_anchors = size的个数+ratios个数-1,也就是以每个像素为中心生成了多少个m+n-1个锚框
# 那么一个feature map有h*w个像素,而一个锚框对应(num_classes + 1)个类别
# 所以实际的预测值 = h * w * num_anchors * (num_classes + 1)
之前的图片分类,是在卷积层的特征输出后面接上一个全连接层,而在这里,卷积层的特征后面不再用全连接层了,而是用一个卷积层,卷积层的输入是输入通道数,输出
num_anchors * (num_classes + 1)
这是和之前图片分类不同的一个核心点:是要对特征图的每一个像素做预测(注意不是原始图像),因此做了很多的预测。
2. 边界框预测层
边界框预测层的设计与类别预测层的设计类似。 唯一不同的是,这里需要为每个锚框预测4个偏移量,而不是 𝑞+1 个类别。
def bbox_predictor(num_inputs, num_anchors):
# 为什么是4个数字呢? 因为锚框到真实的bounding box的偏移是有4个值
# 分别是锚框左上角的x,y轴坐标和右下角的x,y轴坐标。
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)
3. 连结多尺度的预测
正如我们所提到的,单发多框检测使用多尺度特征图来生成锚框并预测其类别和偏移量。 在不同的尺度下,特征图的形状或以同一单元为中心的锚框的数量可能会有所不同。 因此,不同尺度下预测输出的形状可能会有所不同。
在以下示例中,我们为同一个小批量构建两个不同比例(Y1和Y2)的特征图,其中Y2的高度和宽度是Y1的一半。 以类别预测为例,假设Y1和Y2的每个单元分别生成了 5 个和 3 个锚框。 进一步假设目标类别的数量为 10 ,对于特征图Y1和Y2,类别预测输出中的通道数分别为 5×(10+1)=55 和 3×(10+1)=33 ,其中任一输出的形状是(批量大小,通道数,高度,宽度)。
def forward(x, block):
return block(x)
# cls_predictor(8, 5, 10),8是输入通道数,5是锚框数,10是代表10个类别
Y1 = forward(torch.zeros((2, 8, 20, 20)), cls_predictor(8, 5, 10))
# cls_predictor(16, 3, 10):输入通道16,3个锚框,10个类别
Y2 = forward(torch.zeros((2, 16, 10, 10)), cls_predictor(16, 3, 10))
Y1.shape, Y2.shape
运行结果:

正如我们所看到的,除了批量大小这一维度外,其他三个维度都具有不同的尺寸。 为了将这两个预测输出链接起来以提高计算效率,我们将把这些张量转换为更一致的格式。
通道维包含中心相同的锚框的预测结果。我们首先将通道维移到最后一维。 因为不同尺度下批量大小仍保持不变,我们可以将预测结果转成二维的(批量大小,高 × 宽 × 通道数)的格式,以方便之后在维度 1 上的连结。
def flatten_pred(pred):
# 原本是(批量,通道数,高,宽),(0,1,2,3)
# 现在把通道数挪到最后,高和宽往前挪一步
# start_dim=1表示把后面3个维度拉成一个向量
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)
这样一来,尽管Y1和Y2在通道数、高度和宽度方面具有不同的大小,我们仍然可以在同一个小批量的两个不同尺度上连接这两个预测输出。
concat_preds([Y1, Y2]).shape

4. 高和宽减半块
为了在多个尺度下检测目标,我们在下面定义了高和宽减半块down_sample_blk,该模块将输入特征图的高度和宽度减半。
事实上,该块应用了 VGG模块设计。 更具体地说,每个高和宽减半块由两个填充为 1 的 3×3 的卷积层、以及步幅为 2 的 2×2 最大汇聚层组成。 我们知道,填充为 1 的 3×3 卷积层不改变特征图的形状。但是,其后的 2×2 的最大汇聚层将输入特征图的高度和宽度减少了一半。 对于此高和宽减半块的输入和输出特征图,因为 1×2+(3−1)+(3−1)=6 ,所以输出中的每个单元在输入上都有一个 6×6 的感受野。因此,高和宽减半块会扩大每个单元在其输出特征图中的感受野。
def down_sample_blk(in_channels, out_channels):
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1)) # 不改变高宽
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels # 不对通道做变换
blk.append(nn.MaxPool2d(2)) # 用一个最大池化层把高宽减半,因为默认stride=2
return nn.Sequential(*blk)
在以下示例中,我们构建的高和宽减半块会更改输入通道的数量,并将输入特征图的高度和宽度减半。
forward(torch.zeros((2, 3, 20, 20)), down_sample_blk(3, 10)).shape
运行结果:

5. 基本网络块
基本网络块用于从输入图像中抽取特征。 为了计算简洁,我们构造了一个小的基础网络,该网络串联3个高和宽减半块,并逐步将通道数翻倍。 给定输入图像的形状为 256×256 ,此基本网络块输出的特征图形状为 32×32 ( 256/2^3=32 )。
# 从原始图片抽特征直到第一次对feature map 做锚框
def base_net():
blk = []
# num_filters是通道数,输入是3,第一次增加到16,再逐步翻倍
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
# 3个down_sample_blk放在一起,第一个down_sample_blk把通道数从3变成16
# 第二个把通道数从16变成32,第三个把通道数从32变成64
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
# 因为用了3次,那么原始图片会减少8倍
return nn.Sequential(*blk)
forward(torch.zeros((2, 3, 256, 256)), base_net()).shape
运行结果:

6. 完整的模型
完整的单发多框检测模型由五个模块组成。每个块生成的特征图既用于生成锚框,又用于预测这些锚框的类别和偏移量。在这五个模块中,第一个是基本网络块,第二个到第四个是高和宽减半块,最后一个模块使用全局最大池将高度和宽度都降到1。从技术上讲,第二到第五个区块都是 多尺度特征块。
# 这是我们手动构造的,也可以构造别的网络结构
def get_blk(i):
if i == 0:
blk = base_net() # 变成32x32的高宽,通道数变成64的feature map
elif i == 1: # 第2个stage,就是down_sample_blk,但是通道数翻倍,并且高宽减半
blk = down_sample_blk(64, 128)
elif i == 4: # 最后一块将高度和宽度降为1
blk = nn.AdaptiveMaxPool2d((1,1))
else: # block2和block3虽然也是down_sample_blk,但是通道数不变
# 因为这个数据集比较小,没必要做特别大的通道数,所以维持不变也可以
# 通常来说,如果数据集比较复杂的话,还是要把通道数往上增加
blk = down_sample_blk(128, 128)
return blk
有5个模块的话,就是在5个尺度上做目标检测,就是每个block的后面,都会做一次。
现在我们为每个块定义前向传播。与图像分类任务不同,此处的输出包括:CNN特征图Y;在当前尺度下根据Y生成的锚框;预测的这些锚框的类别和偏移量(基于Y)。
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X) # X是输入,blk是network,Y就是这个stage的feature map
anchors = d2l.multibox_prior(Y, sizes=size, ratios=ratio)
cls_preds = cls_predictor(Y)# 这里没有传入参数num_anchors, num_classes,因为预测网络
bbox_preds = bbox_predictor(Y)# 只需要前向传播,计算损失函数才需要锚框
# Y是当前的feature map,也就是卷积层的输出
# anchors是在卷积层的输出上面生成的锚框
# cls_preds是对每一个锚框的类别预测,以及到真实边缘框的预测
return (Y, anchors, cls_preds, bbox_preds)
回想一下,一个较接近顶部的多尺度特征块是用于检测较大目标的,因此需要生成更大的锚框。 在上面的前向传播中,在每个多尺度特征块上,我们通过调用的multibox_prior函数的sizes参数传递两个比例值的列表。
在下面,0.2和1.05之间的区间被均匀分成五个部分,以确定五个模块的在不同尺度下的较小值:0.2、0.37、0.54、0.71和0.88。 之后,他们较大的值由 根号下0.2×0.37=0.272 、 根号下0.37×0.54=0.447 等给出。
# 因为有5个stage,所以要对每一个stage去设置锚框的大小和高宽比
# 第一个层是feature map是32x32的那个层
sizes = [[0.2, 0.272],
[0.37, 0.447],
[0.54, 0.619],
[0.71, 0.79],
[0.88, 0.961]]
# 也可以看出越往底层走,feature map越大,size取得相对比较小,就去看比较小的图片
# 因为size表示占图片的百分之多少,越小,则占图片比例越小,就去检测小目标
# 越往顶层走,则相反,去检测较大目标
ratios = [[1, 2, 0.5]] * 5 # [1, 2, 0.5]是常用的ratio组合
# sizes是一个列表,sizes[0]返回的是列表中第一个元素的长度
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
现在,我们就可以按如下方式定义完整的模型TinySSD了。
class TinySSD(nn.Module):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
# 类别数量
self.num_classes = num_classes
# 有5个stage,5个stage的输出通道分别是64、128、128、128、128
idx_to_in_channels = [64, 128, 128, 128, 128]
# 因为在5个尺度上做预测,所以每一个尺度都要定义cls_predictor和bbox_predictor
for i in range(5):
# 即赋值语句self.blk_i=get_blk(i)
# 每个stage都要通过get_blk来定义网络
setattr(self, f'blk_{i}', get_blk(i))
# 并且每个stage要定义cls_predictor
setattr(self, f'cls_{i}', cls_predictor(idx_to_in_channels[i],
num_anchors, num_classes))
# 每个stage要定义bbox_predictor
setattr(self, f'bbox_{i}', bbox_predictor(idx_to_in_channels[i],
num_anchors))
def forward(self, X):
# 初始化
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5): # 有5个stage
# 对每个stage迭代都应用blk_forward函数
# 使用 getattr(self,'blk_%d'%i)把对应属性拿出来,这些都在init函数中定义了
# 对于每一个stage,除了X是不断被重写,其余的都是存入anchors[i], cls_preds[i], bbox_preds[i]
# 所以anchors[i], cls_preds[i], bbox_preds[i]都是list
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],
getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))
# 5个stage跑完之后,把所有anchors并在一起
anchors = torch.cat(anchors, dim=1)
# 并且cls_preds也要concat到一起
cls_preds = concat_preds(cls_preds)
# 还要进行reshape,最后一个维度存self.num_classes + 1,中间是3d的东西,
# 这样方便做softmax
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1)
# bbox_preds也concat到一起
bbox_preds = concat_preds(bbox_preds)
# 最后返回的内容中,不需要卷积层的输出(因为X一直在被重写)
# 需要的是每一个层的anchors,对每一个锚框类别的预测,以及真实边缘框的预测
return anchors, cls_preds, bbox_preds
也能看出,这个和之前的图片分类不一样,图片分类拿到的是原始输入经过多层卷积到最后输出,在这里我们只要每一层跑的一些输出然后合并起来。
我们创建一个模型实例,然后使用它对一个 256×256 像素的小批量图像X(执行前向传播)。
如前面部分所示,第一个模块输出特征图的形状为 32×32 。 回想一下,第二到第四个模块为高和宽减半块,第五个模块为全局汇聚层。 由于以特征图的每个单元为中心有 4 个锚框生成,因此在所有五个尺度下,每个图像总共生成 (32^2 + 16 ^2 + 8^ 2+ 4^2+1)×4=5444 个锚框。
net = TinySSD(num_classes=1)
X = torch.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)
print('output anchors:', anchors.shape)
print('output class preds:', cls_preds.shape)
print('output bbox preds:', bbox_preds.shape)
运行结果如下:

anchor的第0维度为1,是因为所有图片的锚框都是一样的,所以就用一套锚框就可以表示所有图片的初始锚框了。
7. 训练模型
现在,我们将描述如何训练用于目标检测的单发多框检测模型。
7.1 读取数据集和初始化
首先,让我们读取中描述的香蕉检测数据集。
batch_size = 32
train_iter, _ = d2l.load_data_bananas(batch_size)
运行结果:

香蕉检测数据集中,目标的类别数为1。 定义好模型后,我们需要初始化其参数并定义优化算法。
device, net = d2l.try_gpu(), TinySSD(num_classes=1)
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)
7. 2 定义损失函数和评价函数
目标检测有两种类型的损失。
第一种有关锚框类别的损失:我们可以简单地复用之前图像分类问题里一直使用的交叉熵损失函数来计算;
第二种有关正类锚框偏移量的损失:预测偏移量是一个回归问题。 但是,对于这个回归问题,我们在这里不使用 平方损失,而是使用 𝐿1 范数损失,即预测值和真实值之差的绝对值。 掩码变量bbox_masks令负类锚框和填充锚框不参与损失的计算。 最后,我们将锚框类别和偏移量的损失相加,以获得模型的最终损失函数。
# reduction='none'表示不要把每个样本上的损失加起来,就保留每个样本的loss
cls_loss = nn.CrossEntropyLoss(reduction='none')
# 为什么不用L2 loss,因为当预测特别不靠谱的时候,平方会使loss变得特别大
bbox_loss = nn.L1Loss(reduction='none')
# cls_labels 是真实的类别,bbox_labels真实的边缘框
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
# cls_preds.reshape(-1, num_classes) 会使得批量大小维度和锚框数量维度放在一起,这样
# 的话,每个锚框就是一个样本,同理,label也做这样的reshape
# 放进CrossEntropyLoss可以得到对锚框分类的loss
cls = cls_loss(cls_preds.reshape(-1, num_classes),
cls_labels.reshape(-1)).reshape(batch_size, -1).mean(dim=1)
# bbox_preds * bbox_masks 和 bbox_labels * bbox_masks表示:
# 当锚框对应的是背景框的时候,bbox_masks=0,反之为1
bbox = bbox_loss(bbox_preds * bbox_masks,
bbox_labels * bbox_masks).mean(dim=1)
return cls + bbox
我们可以沿用准确率评价分类结果。 由于偏移量使用了 𝐿1 范数损失,我们使用平均绝对误差来评价边界框的预测结果。这些预测结果是从生成的锚框及其预测偏移量中获得的。
def cls_eval(cls_preds, cls_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维。
return float((cls_preds.argmax(dim=-1).type(
cls_labels.dtype) == cls_labels).sum())
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
7.3 训练模型
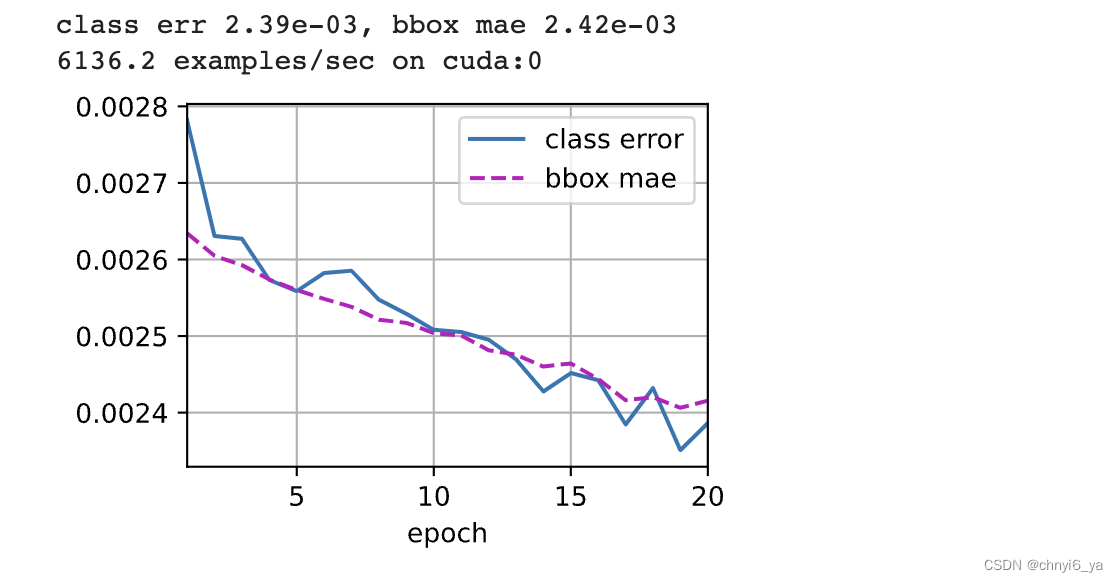
在训练模型时,我们需要在模型的前向传播过程中生成多尺度锚框(anchors),并预测其类别(cls_preds)和偏移量(bbox_preds)。 然后,我们根据标签信息Y为生成的锚框标记类别(cls_labels)和偏移量(bbox_labels)。 最后,我们根据类别和偏移量的预测和标注值计算损失函数。为了代码简洁,这里没有评价测试数据集。
num_epochs, timer = 20, d2l.Timer()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['class error', 'bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):
# 训练精确度的和,训练精确度的和中的示例数
# 绝对误差的和,绝对误差的和中的示例数
metric = d2l.Accumulator(4)
net.train()
for features, target in train_iter:
timer.start()
trainer.zero_grad()
# 把X,Y都放到gpu上,Y是真实的bounding box(边缘框),我们不能直接预测真实边缘框
X, Y = features.to(device), target.to(device)
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, cls_preds, bbox_preds = net(X) # 生成预测(类别和偏移量),这3个值要和真实的Y做对比
# 为每个锚框标注类别和偏移量
# d2l.multibox_target这个函数是根据锚框和真实边缘框Y去生成3个值
# 怎么把锚框映射到真实边缘框,一一对应起来,这样能对每一个锚框变成一个样本,拿到3个值:
# bbox_labels:真实边缘框的偏移,bbox_masks:是背景还是有物体,cls_labels:类别
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y)
# 根据类别和偏移量的预测和标注值计算损失函数
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.mean().backward()
trainer.step()
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),
bbox_eval(bbox_preds, bbox_labels, bbox_masks),
bbox_labels.numel())
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on '
f'{str(device)}')
运行结果:
8. 预测目标
在预测阶段,我们希望能把图像里面所有我们感兴趣的目标检测出来。
在下面,我们读取并调整测试图像的大小,然后将其转成卷积层需要的四维格式。
X = torchvision.io.read_image('drive/MyDrive/chapter13/img/banana.jpg').unsqueeze(0).float()
img = X.squeeze(0).permute(1, 2, 0).long()
使用下面的multibox_detection函数,我们可以根据锚框及其预测偏移量得到预测边界框。然后,通过非极大值抑制来移除相似的预测边界框。
def predict(X):
net.eval() # 预测模式
# 把X挪到GPU上
anchors, cls_preds, bbox_preds = net(X.to(device))
# 把cls_preds换成softmax的概率
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1)
# 把锚框anchors和bbox_preds结合起来还原出真实预测的边界框,再根据cls_probs的置信度
# 来预测边界框,再通过NMS(非极大值抑制)来一出相似的预测边缘框
# 也就得到最终的输出output,那也是机器挑出的最好的一个
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors)
# 也可以看出这里和图片分类的区别是要run一下NMS,而NMS在GPU上跑起来不容易,
# NMS要非常好的实现,才能保证在GPU上跑得很快
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
return output[0, idx]
output = predict(X)
最后,我们筛选所有置信度不低于0.9的边界框,做为最终输出。
def display(img, output, threshold):
d2l.set_figsize((5, 5))
fig = d2l.plt.imshow(img)
for row in output:
score = float(row[1])
if score < threshold:
continue
h, w = img.shape[0:2]
bbox = [row[2:6] * torch.tensor((w, h, w, h), device=row.device)]
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
display(img, output.cpu(), threshold=0.9)
运行结果:

上面图片中,白色框框是预测框,旁边的数字是对类别的预测度。
9. 总结
- 对每一个锚框的类别的预测以及到真实边界框的偏移,是kernel_size为3的一个卷积层来解决,因为没有改变高宽,所以对每个像素都要做预测,预测值全部在通道里面。通道数=每个像素生成的锚框数 x( 每个锚框需要预测的类别+1)
- 图片进来之后,输出的东西不再是Y,要的是锚框,锚框的预测,类别的预测以及偏移的预测
- 最后是不同的尺度下面所有东西都concat到一起,再做loss的时候是类别的loss和偏移的loss是L1范式
- 在预测的时候要做NMS,这样能把重复的锚框去掉,得到干净的预测
- 在做forward的时候,对锚框的类别预测根本没看锚框是什么样子的。那在什么时候会去看锚框的样子呢?是在计算loss的时候。虽然没告诉这个锚框到底是在什么地方,但是在loss上会告诉对应的位置应该是某个类,使得神经网络尽量把注意力转移到锚框真正地圈住的位置。以及要去predict 偏移,也是真正地去学。
- 没有告诉神经网络要到某一块区域里去看,而是让机器看所有区域,但是在loss中告诉这个区域很有可能在这一块/那一块。所以锚框的信息是通过loss进去的。
- 训练的时候用锚框和损失训练整个图,不过是按照框内的做优化损失。
10. Q&A
Q1:分辨率和size什么关系?w,h和s。
A1:分辨率是当前feature map的高宽,越大分辨率越高,也就是每个block输入的大小,size是锚框要占feature map的占比。当w,h比较大时,会选择比较小的s;反之依然。
Q2:多尺度是什么意思?
A2:当一个图片进来,每一个层输出的大小会不一样,看到的尺度是不一样的,分辨率是不一样的,越到顶层,分辨率越低,但是更高维;越底层,空间分辨率越高,看到的是局部。在不同的stage都去做目标检测就是多尺度的意思。