文章目录
- Filebeat的概念
- 简介
- Filebeat特点
- Filebeat与Logstash对比
- Filebeat安装
- 安装地址
- Logstash部署安装
- Filebeat实战
- 对接Logstash
- Filebeat模块使用(配置Kafka)
- 对接ES案例展示
- 对接Kafka案例展示
- 总结
Filebeat的概念
简介
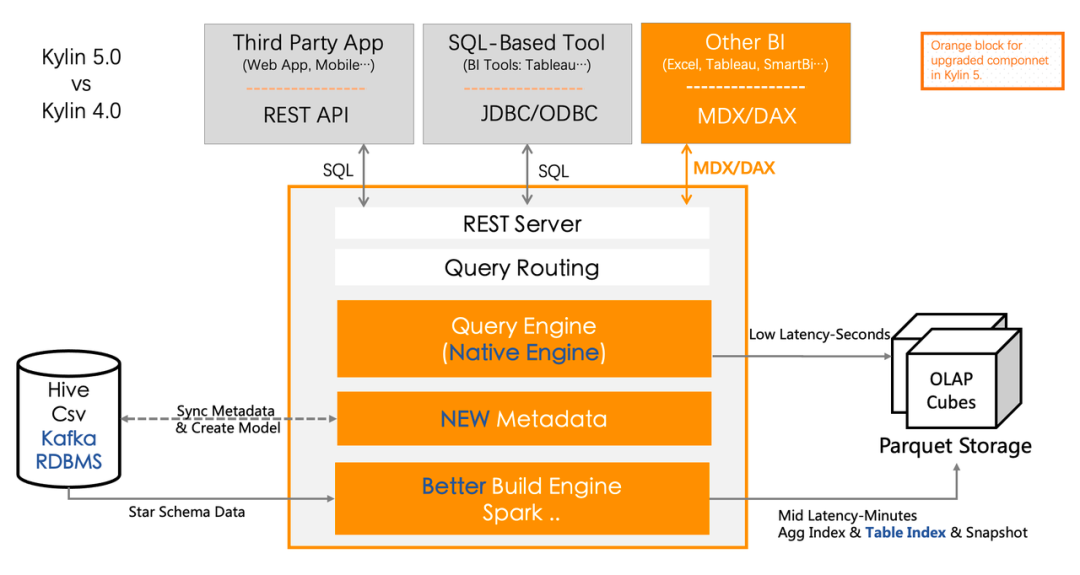
Filebeat是一种轻量型日志采集器,内置有多种模块(auditd、Apache、NGINX、System、MySQL 等等),可针对常见格式的日志大大简化收集、解析和可视化过程,只需一条命令即可。之所以能实现这一点,是因为它将自动默认路径(因操作系统而异)与 Elasticsearch 采集节点管道的定义和 Kibana 仪表板组合在一起。不仅如此,数个 Filebeat 模块还包括预配置的 Machine Learning 任务。另一点需要声明的是:根据采集的数据形式不同,形成了由多个模块组成的Beats。Beats是开源数据传输程序集,可以将其作为代理安装在服务器上,将操作数据发送给Elasticsearch,或者通过Logstash,在Kibana中可视化数据之前,在Logstash中进一步处理和增强数据。
Beats组成模块如下:
| 日志格式 | 采集所需组件框架 |
|---|---|
| Audit data | Auditbeat(轻量型审计日志采集器) |
| Log files | Filebeat(轻量型日志采集器) |
| Availability | Heartbeat(轻量型运行时间监控采集器) |
| Metrics | Metricbeat(轻量型指标采集器) |
| Network traffic | Packetbeat(轻量型网络数据采集器) |
| Windows event logs | Winlogbeat(轻量型 Windows 事件日志采集器) |
Beat日志采集流程图:
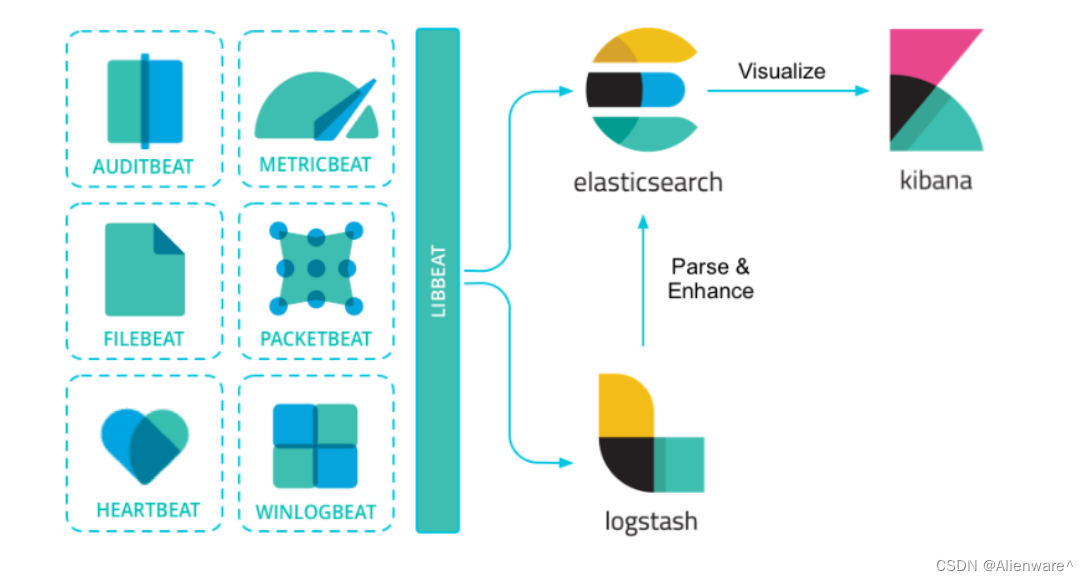
Filebeat特点
1)轻量型日志采集器,占用资源更少,对机器配置要求极低。
2)操作简便,可将采集到的日志信息直接发送到ES集群、Logstash、Kafka集群等消息队列中。
3)异常中断重启后会继续上次停止的位置。(通过${filebeat_home}\data\registry文件来记录日志的偏移量)。
4)使用压力敏感协议(backpressure-sensitive)来传输数据,在logstash 忙的时候,Filebeat 会减慢读取-传输速度,一旦 logstash 恢复,则 Filebeat 恢复原来的速度。
5)Filebeat带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。
bin/logstash -e 'input { stdin{} } output { stdout{} }'
Filebeat与Logstash对比
1)Filebeat是轻量级数据托运者,您可以在服务器上将其作为代理安装,以将特定类型的操作数据发送到Elasticsearch。与Logstash相比,其占用空间小,使用的系统资源更少。
2)Logstash具有更大的占用空间,但提供了大量的输入,过滤和输出插件,用于收集,丰富和转换来自各种来源的数据。
3)Logstash是使用Java编写,插件是使用jruby编写,对机器的资源要求会比较高。在采集日志方面,对CPU、内存上都要比Filebeat高很多。
Filebeat安装
Filebeat本身对机器性能要求不高,所以对机器性能无需过多关注。加之,其采集数据后采用的Http请求发送的数据,所以对运行环境也无过多要求,因此在部署Filebeat时,应过多的关注其它组件的部署问题。
安装地址
1)Filebeat官网地址:https://www.elastic.co/cn/products/beats/filebeat
2)安装包下载地址:https://www.elastic.co/cn/downloads/beats/filebeat
笔者这里用的是8.5.2版本,包括ES,Kibana,Logstash框架等。一律使用的均是8.5.2版本
在这里笔者为了节省主节点资源,不将组件放到主节点了,放到次节点上
[root@hadoop103 ~]# cd /opt/software/
[root@hadoop103 software]# mkdir elk
[root@hadoop103 software]# cd elk/
#将组件放入该目录中

[root@hadoop103 elk]# tar -zxvf filebeat-8.5.2-linux-x86_64.tar.gz -C /opt/module/
[root@hadoop103 elk]# cd /opt/module/
[root@hadoop103 module]# mv filebeat-8.5.2-linux-x86_64/ filebeat
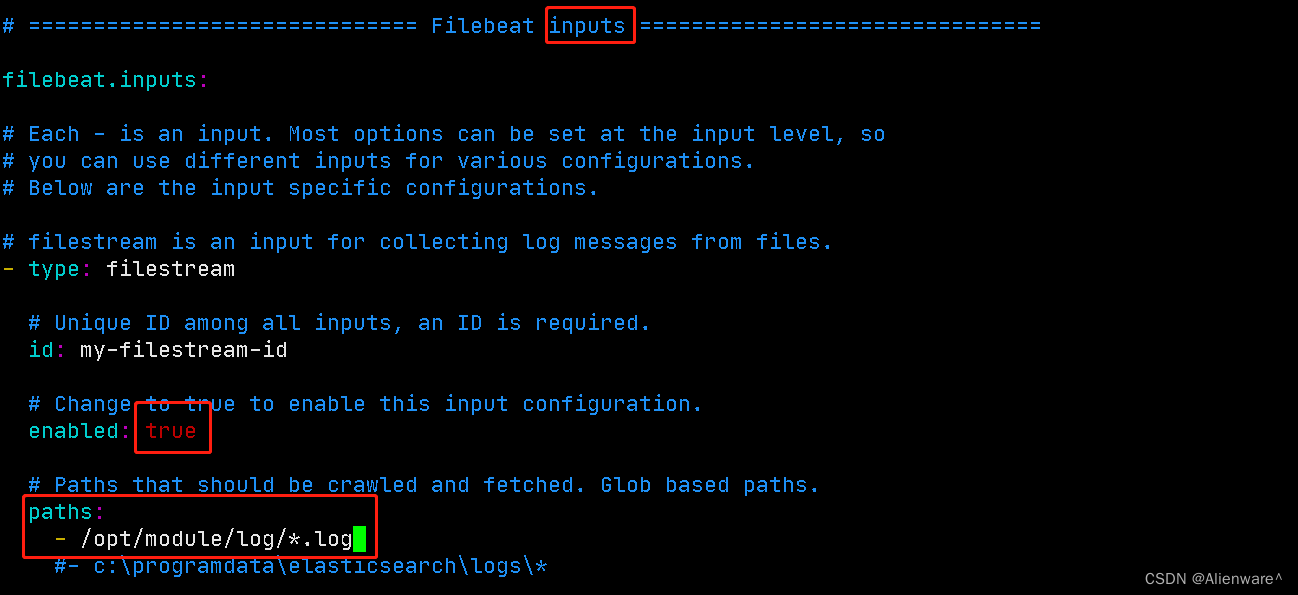
进入filebeat,指定监控日志的输入输出路径
[root@hadoop103 module]# mkdir log
[root@hadoop103 module]# cd filebeat/
[root@hadoop103 filebeat]# vim filebeat.yml
对图片内容进行修改
Logstash部署安装
[root@hadoop103 elk]# tar -zxvf logstash-8.5.2-linux-x86_64.tar.gz -C /opt/module/
[root@hadoop103 module]# mv logstash-8.5.2/ logstash
注意:logstash在使用的时候单独配置运行文件。
Filebeat实战
对接Logstash
1)创建文件夹加job编写数据采集文件:filebeat_to_logstash.conf文件
[root@hadoop103 logstash]$ mkdir job
[root@hadoop103 logstash]$ cd job/
[root@hadoop103 job]$ vim filebeat_to_logstash.conf
# 添加内容如下
input {
#对接的是beats
beats {
#端口号5044
port=>5044
#编码格式GBK
codec=>plain{
charset=>"GBK"
}
}
}
filter {
mutate{
split=>["message","|"]
add_field => {
"field1" => "%{[message][0]}"
}
add_field => {
"field2" => "%{[message][1]}"
}
remove_field => ["message"]
}
json{
source => "field1"
target => "field2"
}
}
#输出数据到控制台
output{
stdout{
codec=>rubydebug
}
}
配置filebeat中的output部分(Logstash)
[root@hadoop103 filebeat]# vim filebeat.yml
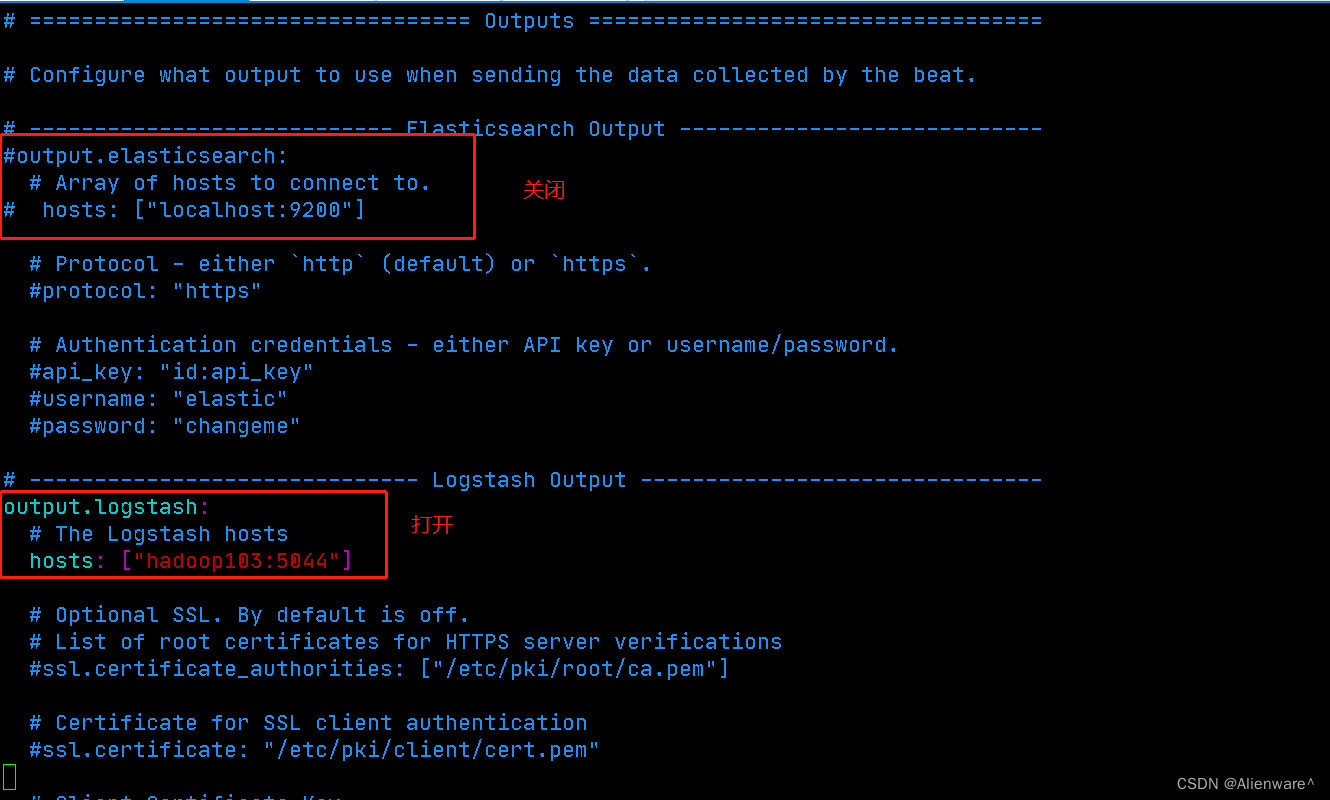
启动filebeat 与 logstash
[root@hadoop103 filebeat]$ ./filebeat -e
[root@hadoop103 logstash]$ bin/logstash -f job/filebeat_to_logstash.conf
进入log目录,创建日志文件,并导入如下数据:
[root@hadoop103 logstash]$ cd /opt/module/log
[root@hadoop103 log]$ vim app.log
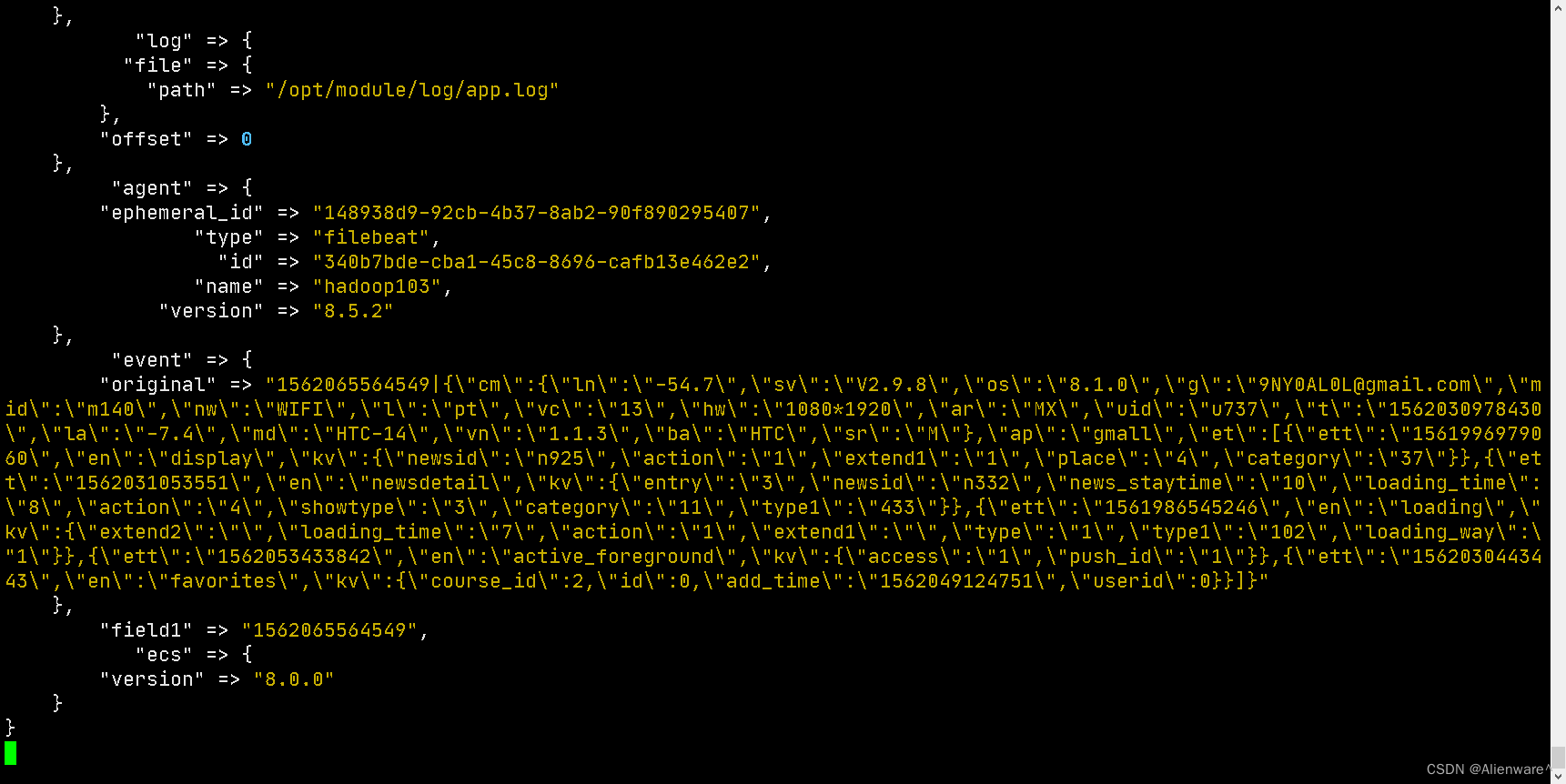
1562065564549|{"cm":{"ln":"-54.7","sv":"V2.9.8","os":"8.1.0","g":"9NY0AL0L@gmail.com","mid":"m140","nw":"WIFI","l":"pt","vc":"13","hw":"1080*1920","ar":"MX","uid":"u737","t":"1562030978430","la":"-7.4","md":"HTC-14","vn":"1.1.3","ba":"HTC","sr":"M"},"ap":"gmall","et":[{"ett":"1561996979060","en":"display","kv":{"newsid":"n925","action":"1","extend1":"1","place":"4","category":"37"}},{"ett":"1562031053551","en":"newsdetail","kv":{"entry":"3","newsid":"n332","news_staytime":"10","loading_time":"8","action":"4","showtype":"3","category":"11","type1":"433"}},{"ett":"1561986545246","en":"loading","kv":{"extend2":"","loading_time":"7","action":"1","extend1":"","type":"1","type1":"102","loading_way":"1"}},{"ett":"1562053433842","en":"active_foreground","kv":{"access":"1","push_id":"1"}},{"ett":"1562030443443","en":"favorites","kv":{"course_id":2,"id":0,"add_time":"1562049124751","userid":0}}]}
查看结果
Logstash控制台结果如下:
Filebeat模块使用(配置Kafka)
1)官方提供了封装完整的框架日志监控,拿kafka为例,使用对应的module可以直接实现对kafka日志的监控
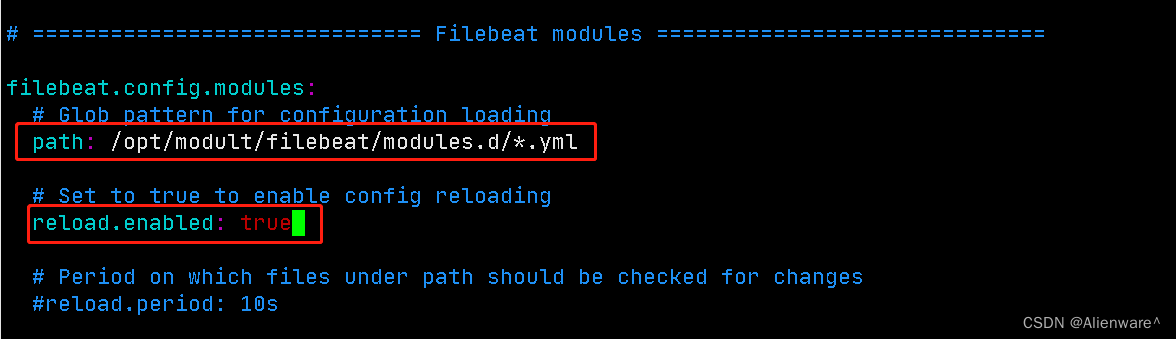
2)修改Filebeat配置文件filebeat.yml
[root@hadoop103 filebeat]$ vim filebeat.yml
按照图片方式设置好
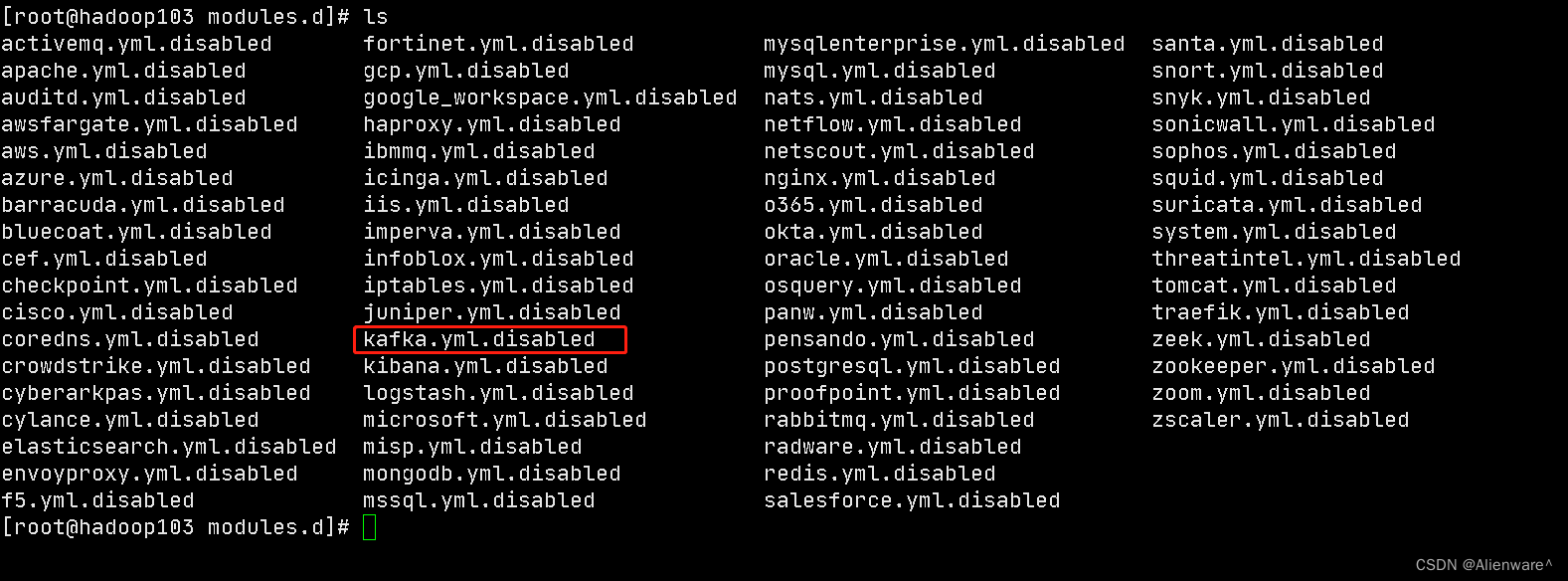
进入modules.d 目录
[root@hadoop103 filebeat]$ cd modules.d
后缀disabled均为不可用状态。
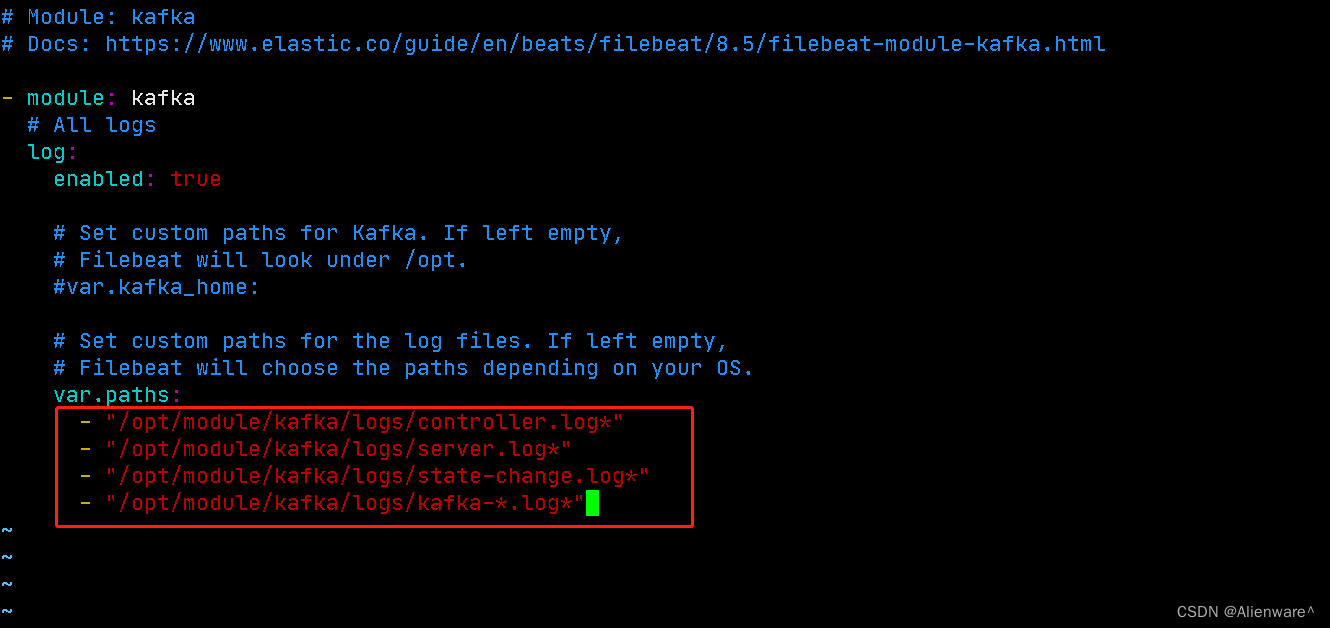
3)修改kafka对应的module配置文件
[root@hadoop103 modules.d]# cp kafka.yml.disabled kafka.yml
[root@hadoop103 modules.d]# vim kafka.yml
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-module-kafka.html
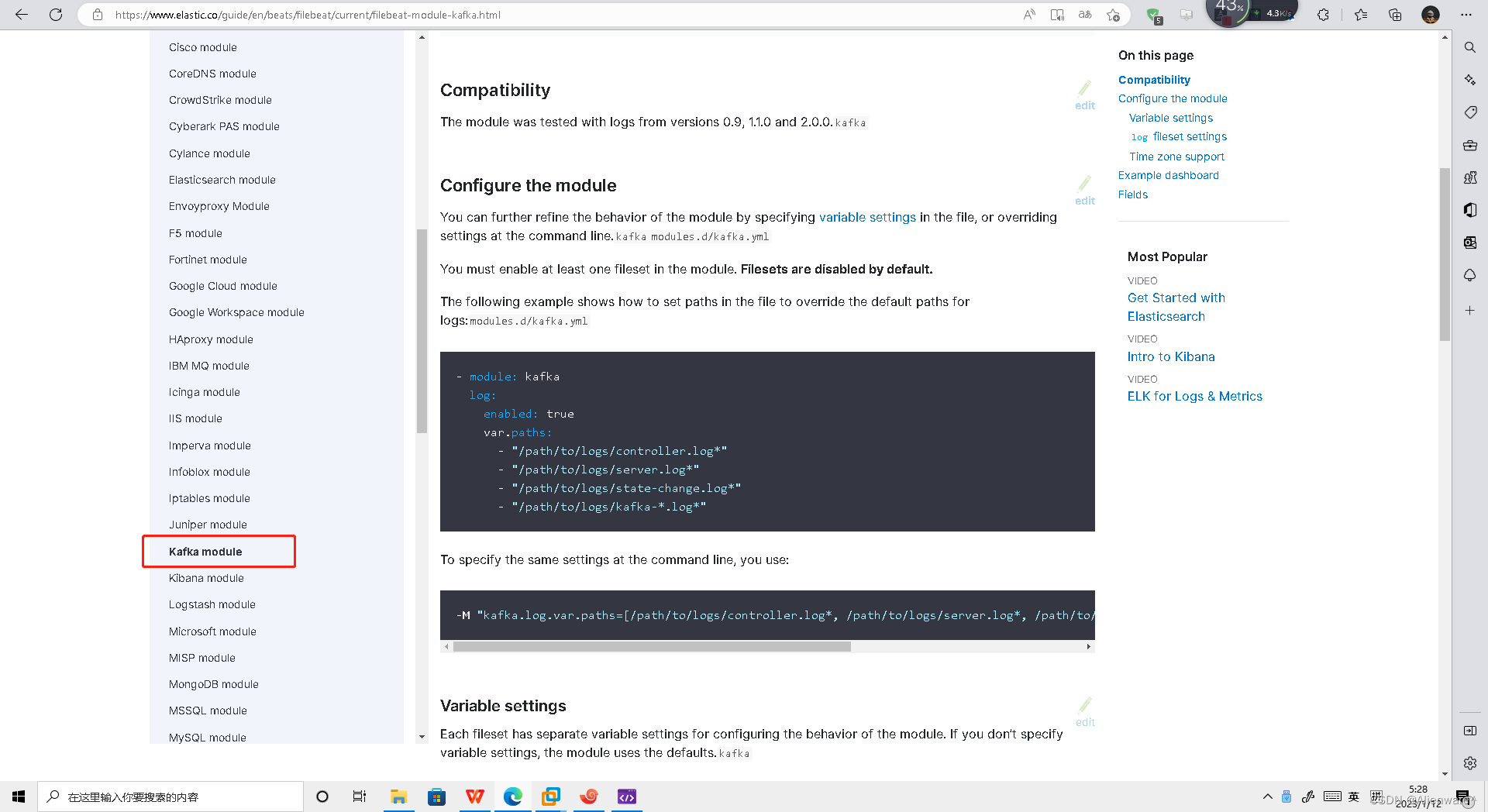
配置文件直接从官方文档获取即可。
注意,官网的path/to是kafka的路径,具体路径要看自己的服务器上kafka的路径。记得修改!
对接ES案例展示
安装ES:https://blog.csdn.net/weixin_45417821/article/details/117389204
这里安装单机版ES即可,只为测试专用
chown -R luanhao:luanhao /opt/module/es
除了单机配置之外,还需要再加入一个配置文件
ingest.geoip.downloader.enabled: false
#并将xpack.security.enabled设置为false,原因:是因为ES8默认开启了 ssl 认证。
xpack.security.enabled: false
官网:https://www.elastic.co/guide/en/beats/filebeat/current/elasticsearch-output.html
1)修改Filebeat配置文件
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["hadoop103:9200"]
#通过判断数据中包含的字符串 可以分流数据
# #通过语法%{}可以调用元数据信息和特殊信息
# #error-8.5.2-2022-12-02
indices:
- index: "warning"
when.contains:
message: "WARN"
- index: "error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
message: "ERR"
- index: "info"
when.contains:
message: "INFO"
清一色的error日志

对接Kafka案例展示
Filebeat也可以直接将数据发送到Kafka
官网相关文档如下:https://www.elastic.co/guide/en/beats/filebeat/current/kafka-output.html
1)修改Filebeat配置文件
[root@hadoop103 filebeat]$ vim filebeat.yml
添加如下内容

简单些就行
启动zk和kafka,安装目录:https://blog.csdn.net/weixin_45417821/article/details/
[root@hadoop104 ~]# kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic logs
之后拷贝一份log文件进去即可
[root@hadoop103 log]# cd /opt/module/log
[root@hadoop103 log]# cp app.log appbak.log
查看kafka消费者内容

总结
对于大数据从业者人员来讲,我们只需要关注,日志文件 -> Filebeat -> Kafka 这样的工程,其他的均可交给Spark ,Flink等计算框架计算即可。