目录
引言
结构形式
整体框架
插入删除接口实现
析构函数、拷贝构造、赋值重载
const迭代器实现
取得链表长度的方式
迭代器前置\后置operator++ -- 以及operator->
引言
list是非常常用的一个容器,数据结构是链表,数据空间是以链式结构存储的,物理空间上不一定是连续的,不像vector物理空间是连续的,可通过下标访问,在list中有可能排在后面的数据物理地址比在排在前面的数据小,所以它不方便通过下标访问,但它也具有它才有的特性,让我们来学习一下list的底层实现吧。
结构形式

库里实现的是带头双向循环链表,下面我们实现底层的时候也是实现该种链表。
每个节点有2个指针,一个next指向下一个节点,一个prev指向前一个节点,还有一个位置data存储对应数据。
整体框架
list 类中只需要一个成员变量,就是节点node的头指针_head,有_head就能指向其他节点。
而节点node需要将它作为一个自定义结构,里面的成员变量就是上面说的3个,_next,_prev和data
先将大框架构架出来:
namespace bc
{
template<class T>
struct list_node
{
list_node<T>* _next;
list_node<T>* _prev;
T _data;
list_node(const T& x)
:_next(nullptr)
, _prev(nullptr)
,_data(x)
{ }
};
template<class T>
class list
{
typedef list_node<T> node;
public:
list()
{
_head = new node(T());
_head->_next = _head;
_head->_prev = _head;
}
void push_back(const T& x)
{
node* newnode = new node(x);
node* tail = _head->_prev;
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
}
private:
node* _head;
};为防止和库里的list混,将我们实现的封在namespace bc中。
list创建对象时需要实例化,list<int> , list<double> .......因此在类前给上模板参数T,
构建节点自定义类型,并在里面完成节点的默认构造初始化。
节点包装完成后是class list类的实现,成员变量是node* _head,实现无参构造函数,初始的时候就是节点的头尾指针都指向自己形成循环:
插入删除接口实现
然后再实现一下push_back函数,插入数据也很简单,改变一下指针指向即可:
void push_back(const T& x)
{
node* newnode = new node(x);
node* tail = _head->_prev;
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
} 
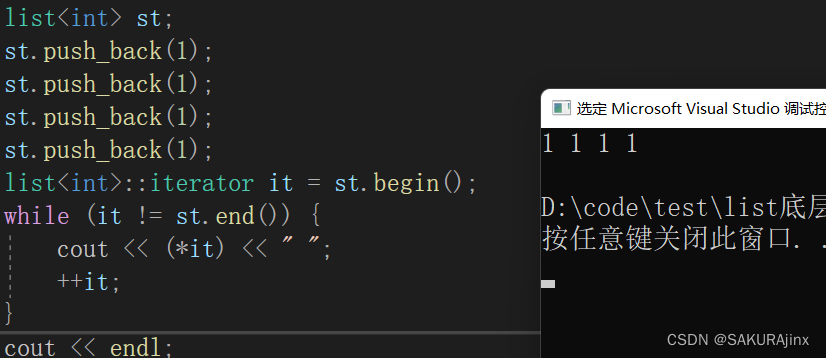
测试一下,因为没法用下标访问就想到通用的迭代器,先把测试用例写一下:
void Test1() {
list<int> st;
st.push_back(1);
st.push_back(1);
st.push_back(1);
st.push_back(1);
list<int>::iterator it = st.begin();
while (it != st.end()) {
cout << (*it) << " ";
++it;
}
cout << endl;
}
}然后实现迭代器,有了string和vector的经验,迭代器底层可用指针实现,那么list这里是不是也可以直接用指针指代迭代器呢?
————如果可以的话来看一下:typedef node* iterator;
用node* 指代迭代器是绝对不行的,之前说了链表的物理空间不是连续的,迭代器++ -- 的功能就是失效了,对此我们可以借鉴日期类(想比较两个日期或者++ -- 计算日期不可以,封装成类对操作符++ -- 重载就可以实现),这里也是一个道理,将迭代器封装层一个类__list_iterator就解决了
namespace bc
{
template<class T>
struct list_node
{
list_node<T>* _next;
list_node<T>* _prev;
T _data;
list_node(const T& x)
:_next(nullptr)
, _prev(nullptr)
,_data(x)
{ }
};
template<class T>
struct __list_iterator
{
typedef list_node<T> node;
node* _pnode;
__list_iterator(node* p)
:_pnode(p)
{ }
T& operator*() {
return _pnode->_data;
}
__list_iterator<T>& operator++() {
_pnode = _pnode->_next;
return *this;
}
bool operator!=(const __list_iterator<T>& it) {
return _pnode != it._pnode;
}
};
template<class T>
class list
{
typedef list_node<T> node;
public:
typedef __list_iterator<T> iterator;
iterator begin() {
return iterator(_head->_next);
}
iterator end() {
return iterator(_head);
}
list()
{
_head = new node(T());
_head->_next = _head;
_head->_prev = _head;
}
void push_back(const T& x)
{
node* newnode = new node(x);
node* tail = _head->_prev;
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
}
private:
node* _head;
};
push_back还可以通过复用insert来实现,下面来实现一下insert
insert是在指定位置之前插入,位置pos还是迭代器类型。insert会导致迭代器失效吗?显然这里插入迭代器不会失效,因为空间没变还在那里,只是在pos位置链接上其他节点(vector那块会失效是因为挪动数据使得空间位置改变了,并且还有扩容的影响)
但库里的insert给了返回类型,我们保持一致也给一个iterator。
insert代码实现也很简单,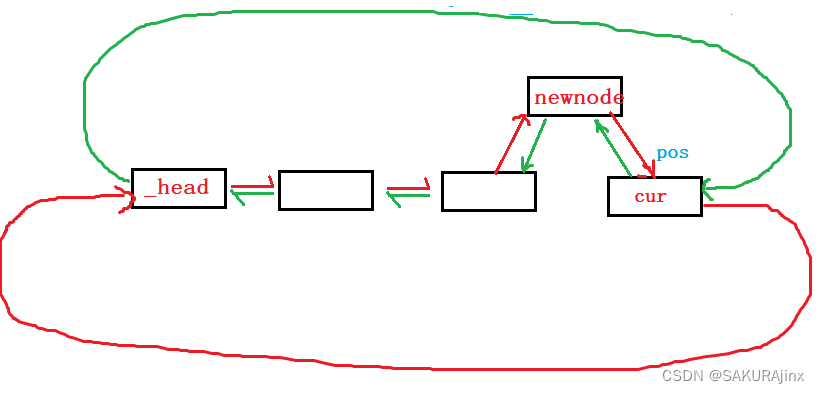
iterator insert(iterator pos, const T& x) {
node* newnode = new node(x);
node* cur = pos._pnode;
newnode->_prev = cur->_prev;
newnode->_next = cur;
cur->_prev->_next = newnode;
cur->_prev = newnode;
return iterator(newnode);
}push_back,push_front 都可以复用insert:
void push_back(const T& x)
{
insert(end(), x);
}
void push_front(const T& x) {
insert(begin(), x);
}
erase和insert一样,也是根据迭代器位置删除。它需要返回值,返回删除位置的下一个位置的迭代器。很明显删除操作会使迭代器失效,因为删除会直接删掉节点,空间没了迭代器自然失效。
代码如下:
iterator erase(iterator pos) {
assert(pos != end());
node* prev = pos._pnode->_prev;
node* next = pos._pnode->_next;
prev->_next = next;
next->_prev = prev;
delete pos._pnode;
return iterator(next);
}同样,pop_back,pop_front 都可以复用 erase:
void pop_back() {
erase(--end());
}
void pop_front() {
erase(begin());
}
析构函数、拷贝构造、赋值重载
然后实现一下拷贝构造和析构函数,先写析构吧简单一点。
在析构之前可以先实现clear,析构函数再复用clear就好了。clear不清头结点,只删后面的节点,而析构函数会清除头结点,所以应该是析构调用clear,别搞反了。
clear()可以创建cur节点遍历删除,也可以复用刚刚实现的erase函数:
void clear() {
iterator it = begin();
while (it != end()) {
it = erase(it);
}
}用迭代器从头开始遍历删除,注意这里迭代器不能++(失效),可以用erase返回值,返回的是删除位置的下一个位置的迭代器,这样相当于迭代器自动往下走了。
析构函数:
~list() {
clear();
delete _head;
_head = nullptr;
}拷贝构造传统写法:
list(list<T>& st) {
_head = new node(T());
_head->_next = _head;
_head->_prev = _head;
for (auto& e : st) {
push_back(e);
}
}首先说一下,参数list<T>& st之前我没有加const,按理说可以加上毕竟st不改变,但是加了const会报错,因为范围for底层是迭代器,
list<int>::iterator it = st.begin();
while (it != st.end()) {
cout << (*it) << " ";
++it;
}&st是实参的别名,是迭代器对象,const list<int>& st 作为const对象只能调用const迭代器,而我们此时还没有实现const迭代器,所以先把const去掉保证编译通过。
函数内部原理就是拷贝之前要先创建对象,初始化一下,然后用范围for插入数据,相当于拷贝过去了。
注意auto&,这里不用&消耗很大。因为范围for是将*st 拷贝给e,也就是将容器里的数据拷贝给e,
如果list<T>的T是int等内置类型还好,拷贝消耗不大,如果T是string、map等具有大量数据的容器那么拷贝消耗会很大,所以用&可以减小拷贝带来的消耗。
我看了一下库里的实现,它将list初始化写成了一个函数empty_initialize,这样方便其他函数调用,我们也跟着保持一致吧:
void empty_initialize() {
_head = new node(T());
_head->_next = _head;
_head->_prev = _head;
}
list()
{
empty_initialize();
}
//st1(st)
list(list<T>& st) {
empty_initialize();
for (auto& e : st) {
push_back(e);
}
}赋值重载传统写法:
//st1 = st
list<T>& operator=(list<T>& st) {
if (this != &st);
clear();
for (auto& e : st) {
push_back(e);
}
return *this;
}和拷贝构造异曲同工,const和&两个问题也是一样。
注意不要自己给自己赋值。
拷贝构造和赋值重载除了传统写法还有现代写法,在实现之前先写一个迭代器构造函数接口方便操作。
迭代器构造函数

template <class InputIterator>
list(InputIterator first, InputIterator last) {
empty_initialize();
while (first != last) {
push_back(*first);
++first;
}
}这种构造函数就是通过迭代器区间来构造list<T>对象。
拷贝构造现代写法:
void swap(list<T>& st) {
std::swap(_head, st._head);
}
list(list<T>& st)
{
empty_initialize();
list<T>tmp(st.begin(), st.end());
swap(tmp);
}现代写法就是通过上面写的迭代器构造函数构造临时list<T>对象tmp,再通过swap函数交换tmp和st 对象的头指针,也就是交换指向的空间和数据。

这里要注意两点:
1、swap函数我们要自己实现一下,算法库提供的swap函数要进行两次深拷贝代价太大,我们借用算法库中的swap自己实现一个容器中使用的可大大降低消耗。
2、一定要在拷贝构造前先构造初始化对象st,否则st对象的_head指针就是指向一段随机空间,swap交换tmp就指向了这段随机空间,在出函数调用析构函数清除临时对象tmp时就会报错,当然也不能给st._head初始化为空,链表为空析构的时候要求至少有哨兵位的头结点,否则也会报错,所以要先构造初始化。
赋值重载现代写法:
list<T>& operator=(list<T> st) {
swap(st);
return *this;
}有了上面的基础, operator= 就很简单了。注意传参不能给引用,否则交换的时候会将st1 和 st 空间数据交换,那么外面st 就改变了,st 真是舍己为人了。
const迭代器实现
承接上面的问题,现在要实现一个const迭代器。有的人可能会说,const迭代器有什么难的,重载一下函数,在前面加一个const不就搞定了?——没那么简单,这样操作的不是所谓的const迭代器,因为const对象就不一样。

这是const迭代器吗?————显然不是!这里const修饰的是cit 对象本身,而不是它指向的值。
const int* a1 和 int* const a2是有区别的:前者const修饰的是指针指向的内容,而不是其本身,也就是它指向的值不能改变,但是a1本身可以改变,对于迭代器来说也就是迭代器指向的值不能修改,但迭代器可以++; 后者相反,迭代器本身不能修改不能++,但能改指向的值。
显然前者符合const迭代器的预期,而这里的写法是属于后者,因此不是我们要的const迭代器。
那么就到迭代器类的内部修改它的重载函数*,使得能用const对象调用该函数,看看这种方法是否可行。

重载一下解引用* 不同对象调用不同的重载函数,这样是解决了解引用访问的问题,但是++又如何呢?难道还能搞出个const ++?
于是想到既然重载函数不行,那么是否可以再构建一个类,一个const迭代器的类。我们不想着再从迭代器类中解决问题,而是换个角度再搞个类出来,一个const_iterator。
template<class T>
struct __list_const_iterator
{
typedef list_node<T> node;
node* _pnode;
__list_const_iterator(node* p)
:_pnode(p)
{ }
const T& operator*(){
return _pnode->_data;
}
__list_const_iterator<T>& operator++() {
_pnode = _pnode->_next;
return *this;
}
__list_const_iterator<T>& operator--() {
_pnode = _pnode->_prev;
return *this;
}
bool operator!=(const __list_const_iterator<T>& it) {
return _pnode != it._pnode;
}
};
整个类相对于iterator类也就是 const T& operator*()的区别,这样就可以通过不同类访问const迭代器和非const迭代器了。但要注意这是两个不同的类,绝不是相近类的概念,就像list<int>和list<double>是两个完全不同的类型一样。
然后在class list中重定义一下这个const类,增加const begin()和const end()
typedef __list_const_iterator<T> const_iterator;
const const_iterator begin()const {
return const_iterator(_head->_next);
}
const const_iterator end()const {
return const_iterator(_head);
}测试一下:
void Print(const list<int>& st) {
list<int>::const_iterator cit = st.begin();
while (cit != st.end()) {
cout << *cit << " ";
++cit;
}
}
void Test2() {
list<int> st;
st.push_back(1);
st.push_back(2);
Print(st);
}
const迭代器对象只能读不能写。
但是这样写有一个缺陷,就是代码冗余,创建 __list_const_iterator类确实能解决,可只有一行不一样显得太过多余,对此库里的实现是用模板解决冗余问题。
template<class T,class Ref>
struct __list_iterator
{
typedef list_node<T> node;
node* _pnode;
__list_iterator(node* p)
:_pnode(p)
{ }
Ref& operator*() {
return _pnode->_data;
}
__list_iterator<T,Ref>& operator++() {
_pnode = _pnode->_next;
return *this;
}
__list_iterator<T, Ref >& operator--() {
_pnode = _pnode->_prev;
return *this;
}
bool operator!=(const __list_iterator<T, Ref>& it) {
return _pnode != it._pnode;
}
};
template<class T>
class list
{
public:
typedef list_node<T> node;
typedef __list_iterator<T,T&> iterator;
typedef __list_iterator<T, const T&> const_iterator;
既然两个类的区别只在operator*函数的返回值,那么就再给iterator类一个模板参数Ref,去标识这个返回值是T&还是const T&。 在class list类中重定义一下,模板参数是<T,T&>就对应非const迭代器,是<T,const T&>就对应const迭代器,这样就解决了代码冗余的问题。
非const迭代器实现好了,拷贝构造和operator = 函数就可以调用非const迭代器了。
PS:因为下面还要加一个模板参数,所以为了书写方便,在这里typedef一下__list_iterator<T,Ref>
template<class T,class Ref>
struct __list_iterator
{
typedef list_node<T> node;
typedef __list_iterator<T, Ref> Self;
node* _pnode;
__list_iterator(node* p)
:_pnode(p)
{ }
Ref& operator*() {
return _pnode->_data;
}
Self& operator++() {
_pnode = _pnode->_next;
return *this;
}
Self& operator--() {
_pnode = _pnode->_prev;
return *this;
}
bool operator!=(const Self& it) {
return _pnode != it._pnode;
}
};取得链表长度的方式
首先想到的是实现一个size接口,遍历链表得到长度,但是这样的接口开销很大,试想每一次得到长度都要遍历一次链表肯定不好。
我们可以采取空间换时间的思想,再加一个成员变量_size。
class list
{
public:
size_t size(){
return _size;
}
private:
size_t _size;那么在构造、增删等函数中都要再修改一下_size,尤其是swap,不然拷贝构造和赋值的对象调用size就不对了。
void swap(list<T>& st) {
std::swap(_head, st._head);
std::swap(_size, st._size);
}
迭代器前置\后置operator++ -- 以及operator->
Self& operator++() {
_pnode = _pnode->_next;
return *this;
}
Self& operator++(int) {
Self tmp(*this);
_pnode = _pnode->_next;
return tmp;
}
Self& operator--() {
_pnode = _pnode->_prev;
return *this;
}
Self& operator--(int) {
Self tmp(*this);
_pnode = _pnode->_prev;
return tmp;
}前置与后置对于内置类型没有什么区别,但对于自定义类型还是有很大差异的,从代码角度就可以看出后置要多两次拷贝,所以还是尽量使用前置。(为区别前置与后置++ --,规定参数部分使用int区分 )
operator->的使用方式很怪,它返回的是节点数据的地址:
T* operator->() {
return &_pnode->_data;
}通过一个场景来理解一下:
struct Pos
{
int _row;
int _col;
Pos(int row = 0, int col = 0)
:_row(row)
, _col(col)
{}
};
void Test3() {
list<Pos>st;
st.push_back(Pos(1, 1));
st.push_back(Pos(2, 2));
list<Pos>::iterator it = st.begin();
while (it != st.end()) {
cout << it->_row <<":"<< it->_col << endl;
++it;
}
}
list的实例化模板给了一个自定义类型Pos,通过迭代器访问打印,it->_row调用了重载函数operator-> 这里相当于是it.operator->(),返回值是数据的地址T*,也就是Pos*。 不对呀,Pos*怎么能打印出数据呢?————其实这里是调用了两次-> 只是没有显示写出来,其实是 it->->_row,因为Pos*->_row就可以打印出数据了,两次->在使用的角度不方便理解(运算符重载的意义就是方便使用理解),所以编译器处理成了一个->的形式。
再看如下一段代码:
void Print(const list<Pos>& st) {
list<Pos>::const_iterator cit = st.begin();
while (cit != st.end()) {
cout << cit->_row++;
cout << cit->_row << ":" << cit->_col << endl;
++cit;
}
}
void Test3() {
list<Pos>st;
st.push_back(Pos(1, 1));
st.push_back(Pos(2, 2));
list<Pos>::iterator it = st.begin();
while (it != st.end()) {
cout << it->_row <<":"<< it->_col << endl;
++it;
}
Print(st);
}在Print函数中,for循环const迭代器指向内容居然能++,cit->_row++并且编译器编译通过了,不是说const迭代器指向内容不能修改吗?
————因为operator-> 返回值都是T*,T*->可以修改指向内容。这里不论是const对象还是非const返回的都是T*,要区分const与非const对象还是用到之前的方法——模板。
template<class T, class Ref,class Ptr>
struct __list_iterator
{
typedef list_node<T> node;
typedef __list_iterator<T, Ref, Ptr> Self;
node* _pnode;
__list_iterator(node* p)
:_pnode(p)
{ }
Ref& operator*() {
return _pnode->_data;
}
Ptr operator->() {
return &_pnode->_data;
}
template<class T>
class list
{
public:
typedef list_node<T> node;
typedef __list_iterator<T, T&,T*> iterator;
typedef __list_iterator<T, const T&,const T*> const_iterator;上面说的第3个模板参数就是用在这里,实际上和第2个本质上是一样的。
以上就是list的底层实现,因为本人浅薄的理解可能讲的不到位,仅仅只是对自己学习的一个总结,感谢浏览!