目录
🚕第一组:一维数组
🚌第二组:字符数组
🚐字符数组1.0
🚎字符数组1.1
🚑字符数组2
🚚字符数组3
🚜第三组:二维数组
🚗在上次的博客之中我们初步介绍了主要有哪些指针,在本次的博客当中我们通过多组示例来了解指针的深度解析,相信大家在阅读完这篇博客之后一定可以有不一样的收获。
🚕第一组:一维数组
//一维数组
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a));
printf("%d\n",sizeof(a+0));
printf("%d\n",sizeof(*a));
printf("%d\n",sizeof(&a));
printf("%d\n",sizeof(*&a));
printf("%d\n",sizeof(&a+1));🚓我们先从简单的一维数组的解析开始入手,我们利用 sizeof 操作符探究一下相关数据在内存中所占的空间的大小:第一个是 sizeof(a); 我们从上面可以看到的是,a 是一个有四个元素的一维数组,我们的数组名在正常情况下表示的都是第一个元素的指针但是在两种情况下表示的是整个数组。
1.sizeof (数组名),数组名表示的是整个数组,sizeof 计算的是整个数组的大小,单位是字节。
2.&数组名。数字组名表示的是整个数组,取出的是整个数组的地址,这个我们在介绍数组指针的时候介绍过。
🚓在知道了上面两种数组名表示整个数组的两个情况之后,我们 sizeof ( a )的大小理解起来就简单多了。我们 sizeof (a) 求得的是整个数组的大小,也就是四个整形所占的字节数——16字节。
🚓下一个 sizeof (a+0)。当我们sizeof当中只有数组名的话数组名表示的就是整个数组,但是一旦多了其他东西,都表示的是第一个元素的地址。所以我们的sizeof(a+0)表示的就是第一个元素的地址,地址的大小在不同机器上的大小不同,在32位机器上的大小为4字节,在64位机器上的大小为8字节。所以我们sizeof(a+0)求得的大小就是4/8字节。
🚓sizeof(*a) 我们在上面说到了sizeof 只有在括号里只有数组名的时候表示的才是整个数组,但是这个括号里面还有一个 * ,所以 a 表示的是第一个元素的地址,所以我们的 *a 表示的就是第一个元素,一个整形所占内存的大小位四个字节,所以我们的 sizeof(*a) 求得的结果就是四个字节。
🚓sizeof(&a) : &a表示的是取出一个数组的地址,但是其真正意义表示的还是一个地址,之哟啊是地址,所以在内存中所占的大小就为4/8个字节。这个其实并不是重点,重点是下一个:sizeof(*&a)。在上面我们直到 &a 表示的是一个数组的地址,那么*&a表示的就是将这个数组指针解引用找到的就是这个数组,我们可以将 * 和 & 当作是一组互逆的符号,可以相互抵消,所以我们可以认为 * 和 & 符号抵消了,sizeof(*&a)也变成了sizeof(a),sizeof括号里面有一个数组名,表达的是整个数组,求得的就是我们整个数组的大小:16个字节。
🚓本组最后一个sizeof(&a+1):我们的&a表示的是一个数组的大小,所以我们 +1 之后会直接跳过一个数组的大小,指向后面一个内存大小和前面数组一样一个地址,但是也是一个指针,只要是指针在内存中所占的大小就是4/8个字节。上面的程序运行效果如下:

🚌第二组:字符数组
🚐字符数组1.0
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr+0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr+1));
printf("%d\n", sizeof(&arr[0]+1));
🚘在我们分析完一维数组之后我们就需要将我们的注意力转向我们的字符型数组了。我们都知道的是字符数组有两种表现形式,相对应的这两种不同的表现形式对应着不同的运行效果,我们就来一个一个进行分析。
🚘我们的arr是一个字符型数组,sizeof(arr) 还是像我们上面所说到的那样求得是一个数组所占内存空间的大小:也就是六个字节。
🚘sizeof(arr+0) 括号里并不只是有数组名所以表示的就是数组的首元素的地址,+0 得到的结果是第一个元素的地址,只要是指针那么所占内存的大小就是4/8个字节。
🚘sizeof(*arr) 括号中并不是只有数组名,所以表示的就是我们数组中第一个元素的地址,然后解引用得到的就是数组中的第一个元素,在内存中所占的大小也就是一个字节。
🚘 sizeof(&arr) :&arr 取出的是整个数组的地址,但是只要是地址在内存中所占的空间的大小就是4/8个字节。sizeof(&arr+1)我们&arr取出的显示一个数组的地址,然后再 +1 就跳过了一个数组的大小,所以我们的(&arr+1)表示的就是我们跳过一个数组之后的地址。一个地址在内存中所占的大小位4/8个字节。
🚘sizeof(&arr[0]+1) : 我们的数组名由于优先级先和 [ ] 相结合,表示下标为0的元素,然后&取出的是第一个元素的地址,之后再 +1 得到的就是数组中第二个元素的地址。地址所占内存的大小为4/8个字节。上面的程序的运行效果如下:

🚎字符数组1.1
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
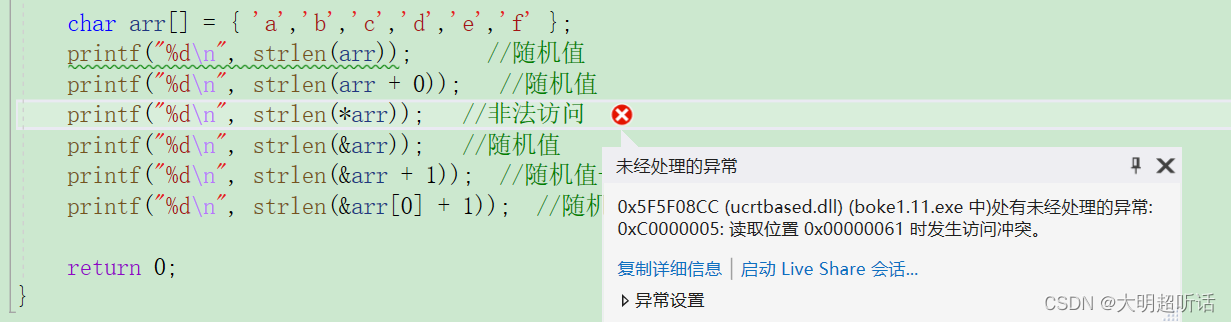
printf("%d\n", strlen(&arr[0]+1));🚔我们有的小伙伴们可能会想:这不是和上面的一样吗?NONONO,让我们仔细来分析分析。我们上面的 sizeof 求的是数据所占内存的大小,我们的strlen求的是 ‘\0’ 之前的字符的个数,所以我们需要记住的是 ‘\0’ 很重要。我们就带着这个去进行代码的分析:strlen(arr),求的是数组中的字符个数遇到 ‘\0’ 停止,但是我们的数组并没有 ‘\0’ 我们的字符串数组有两种书写形式,我们知道的是当我们使用单引号一个字符一个字符进行列举的时候我们数组中并不会附加上 ‘\0’ 所以我们的strlen库函数就会一直向后查找数组中的元素直到遇到 ‘\0’ 为止,(也就是0)但是我们数组一旦越界之后的值就是随机值了,什么遇到0我也不知道,所以我们strlen求出的就是一个随机值。
🚔strlen(arr+0) 在分析这个式子的时候我们先来补充一个知识:也就是strlen函数的基本原型。
🚔上面我们可以看到的是strlen函数的形参部分是一个char类型的指针,我们再向函数传输一个字符型指针之后就会向后进行查找之后遇见 ‘\0’为止。那么我们回过头来分析这个题目:strlen(arr+0)。arr+0表示的是首元素的地址,即一个char类型的指针,也就是说我们的strlen函数需要从数组中的第一个元素开始向后进行查找直到找到 ‘\0’ 为止。经过上一条分析之后我们可以知道的是strlen(arr+0)的到的值也是一个随机值。
🚔strlen(*arr) : 我们的*arr得到的是第一个元素也就是 ‘a’ 但是我们经过上面的函数原型可以知道的是strlen函数的形参为一个函数指针,而我们要是向函数中传一个字符作为参数的话那么就会出现错误,因为我们的字符 a 实质上就是一个ASCII码值,当我们将这个ASCII码值作为参数传给strlen时我们的程序就会将传入的ASCII码值当作一个地址读取,进而导致非法访问。进而系统报错。
🚔strlen(&arr) :我们的&arr表示的是整个数组的地址。但是这种作用形式只会再数组加一的时候体现出来,我们的&arr得到的值和我们的首元素的地址相等。虽然&arr的数据类型为char(*pa)[6]但是会发生隐式转换,只会有一个警告,系统就将我们的&arr的值转换成char*类型的数据了。所以我们得到的结果也是从数组首元素开始到 ‘\0’ 结束的长度。由于没有 ‘\0’ 所以就为随机值。
🚔strlen(&arr+1) 我们经过上面的分析之后可以知道的是&arr表示的是整个数组的大小 +1 之后会跳过整个数组的长度。之后经过隐式转化之后从数组的末尾开始查找 ‘\0’ 。我们得到的结果也是一个随机值,只不过这个随机值比上面的随机值小一个数组的长度。
🚔strlen(&arr[0]+1) 这个和我们上面的分析方法是相同的。arr先和我们的 [0] 相结合表示数组的第一个元素,之后再取地址表示第一个元素的地址,类型为 char* 之后 +1得到的是第二个元素的地址。与我们的strlen函数的参数刚好相符。所以我们的strlen函数求得就是从数组第二个元素开始查找直到 ‘\0’ 为止,答案是一个随机数且比strlen(arr)得到的结果小1。上面我们的代码的运行结果也就可以得出:
🚑字符数组2
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
printf("%d\n", strlen(&arr[0]+1));🛹当我们使用双引号直接引出一个字符串的时候我们得到的是我们给出的字符串+1。数组中会隐形的含有一个 ‘\0’ 用于表示字符串的结束。所以我们在使用sizeof 和strlen进行计算的时候就绪要格外地进行注意。就像是我们的sizeof(arr)表示的就是我们的整个数组的大小 ”abcdef“ 外加上 ‘\0’ 所以我们得到的结果就是7个字节。
🛹我们的strlen(arr)表示的是从数组首元素开始到 ‘\0’ 结束计算字符的个数。由于我们的数组之中带着一个隐性的 ‘\0’ 所以我们的结果为6。
🛹strlen(arr+0)表示的和我们的上面的strlen(arr)一样都是从首元素开始计算字符串的长度,所以大小也为6。
🛹strlen(*arr)表示的是我们数组的首元素,因为一个字符即一个ASCII直接进行传参会产生非法访问,所以我们的系统会报错。
🛹strlen(&arr) 和我们上面分析的一样,也是整个元素的指针进行隐式强转最终的到一个首元素的地址。唯一不同的就是我们在这里有 ‘\0’ 所以我们的答案不再是随机值而是我们字符串的长度6。
🛹strlen(&arr+1)这个式子的分析结果就和我们这组分析的结果大不相同了。我们先&arr得到整个数组的指针然后 +1 得到的是跳过整个数组的指针(跳过七个元素”abcdef“和'\0')然后我们再向后查找 ‘\0’ 由于我们数组后面的值并不确定所以得到的答案是一个随机值。
🛹strlen(&arr[0]+1)这个式子的分析过程就不像是我们上面的分析那么离谱了,就又变回了循规蹈矩的步骤:数组名先和 [0] 结合得到第一个元素然后再取地址得到第一个元素的地址,+1 之后得到第二个元素的地址。所以我们这个式子得到的结果就是从第二个元素开始一直到 ‘\0’ 为止的字符个数,也就是5。我们上面的程序演示结果如下:
🚚字符数组3
char *p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p+1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p[0]+1));
printf("%d\n", strlen(p));
printf("%d\n", strlen(p+1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p+1));
printf("%d\n", strlen(&p[0]+1));🚲假如我们将我们的字符串放到一个指针变量中再进行求值呢?会有什么不一样吗?我们继续来接着分析:
🚲 sizeof(p) 一个指针的大小都为4/8个字节。
🚲sizeof(p+1)表示的是 第二个元素的指针也就是4/8个字节。
🚲sizeof(*p)得到的是一个字符型元素所占内存的大小也就是一个字节。
🚲sizeof(&p)我们的p表示的是一个指针然后再重新进行&操作得到的就是一个二级指针。二级指针同样是一个指针,所以我们得到的结果同样是4/8个字节。
🚲最后一个式子sizeof(&p[0]+1)我们p[0]表示第一个元素怒然后&得到第一个元素的地址+1得到第二个元素的地址,地址的大小再内存中都占4/8个字节。
🚲之后就到我们的strlen组的分析了。strlen(p)由于p代表的是字符串首个字符的地址,所以我们的strlen可以正常接收得到的结果是6。
🚲strlen(p+1)向后跳过一个字节的大小得到第二个元素的指针最终得到的结果是5。
🚲strlen(*p)我们*p将指针p解引用得到第一个元素,会产生非法访问,系统会报错。
🚲strlen(&p)我们&p得到的是一个二级指针。我们strlen库函数实质上会在函数中进行一次类似于解引用的操作得到字符,但是我们的二级指针经过一次解引用之后得到的结果依旧是一个指针(地址),所以我们的库函数会将我们解引用之后得到的地址认为是一个字符和我们的 ‘\0’ 进行比较。如果相等就表示字符串结束这里由于是系统随机分配地址所以我们的到的答案依旧是随机值。
🚲strlen(&p[0]+1)我们的数组名会先和 [0] 结合表示数组的第一个元素。然后&表示第一个元素的地址,之后+1得到的就是第二个元素的地址,strlen函数会从第二个元素开始进行查找,结果是5。我们上面的程序运行效果如下图所示:
🚜第三组:二维数组
//二维数组
int a[3][4] = {0};
printf("%d\n",sizeof(a));
printf("%d\n",sizeof(a[0][0]));
printf("%d\n",sizeof(a[0]));
printf("%d\n",sizeof(a[0]+1));
printf("%d\n",sizeof(*(a[0]+1)));
printf("%d\n",sizeof(a+1));
printf("%d\n",sizeof(*(a+1)));
printf("%d\n",sizeof(&a[0]+1));
printf("%d\n",sizeof(*(&a[0]+1)));
printf("%d\n",sizeof(*a));
printf("%d\n",sizeof(a[3]));🛵接下来我们就来到了我们最重要的一部分:二维数组的内存指针相关解析。废话少说我们直接来看例题:sizeof(a)我们的数组名依然表示的是整个数组,我们的二维数组当中一共有12个元素,给个元素的类型都是 int 所以我们的到的结果就是48。
🛵sizeof(a[0][0])表示的就是第一个元素,也就是sizeof(int)我们得到的结果自然也就是4。
🛵注意我们的难点来了:sizeof(arr[0]),我们可以将我们的二维数组看成一个由数组组成的新的数组,如a[3][4]={0}={ {0,0,0,0} , {0,0,0,0} ,{0,0,0,0} };所以说我们的a[0]相当于我们的第一个数组元素也就是{0,0,0,0},同时我们的a[0]也可以理解成一个新的数组名即a1,那么我们的sizeof(a[0])的大小就是16。
🛵sizeof(a[0]+1)就像是上面我们所说的那样我们的a[0]可以理解成为一个新的数组名,那么要是有其他部分的话表示的就是首元素的地址,即第一行第一个元素的地址,之后再+1得到的第一行第二个元素的地址,地址的内存大小为4/8个字节。
🛵sizeof(*(a[0]+1))我们的a[0]+1表示的是第一行第二个元素的地址那么解引用得到的就是第一行第二个元素。所以结果就是4个字节。
🛵sizeof(a+1)同样的道理我们的二维数组也可以利用上面的规律,数组名单独出现的话就表示的是整个数组,只要有其他部分表示的就是第一个元素的地址,所以我们的a+1表示的就是我们的第二”元素“(第二行的数组)的指针。所以我们的答案是4/8个字节。
🛵sizeof(*(a+1))我们上面说到了a+1得到的是我们第二行的数组的地址,所以我们再解引用得到的就是第二行的数组。答案也就是16个字节。
🛵sizeof(&a[0]+1)根据我们的规律变量名先和[0]结合得到数组的第一行第一个元素的地址,然后再取地址得到的就是第一行数组的地址然后+1得到的就是第二行的数组的地址。地址在内存中所占的大小为4/8个字节。
🛵sizeof(*(&a[0]+1))我们在上面的基础之上继续分析得到:第二行数组的地址进行解引用得到的就是第二行的数组的大小,所以我们的答案就是16个字节。
🛵sizeof(*a)我们很容易地就能够发现数组名a并没有单独存在所以我们的a就理解为第一个元素即第一行的数组然后进行解引用得到的就是第一行的数组的大小。答案为16个字节。
🛵sizeof(a[3])(注意:数组的下标的范围!)很多小伙伴们看到这里肯定会感到很好奇,这不是已经数组越界了吗?其实不然。我们在这里再进行扩充一个知识点:sizeof实质上是针对数据类型进行判断的,并不会对括号里面的式子进行运算。这是因为我们的sizeof操作符再编译的阶段就已经计算完毕了,但是我们等式的计算是在运行阶段才进行计算的。运行阶段在编译阶段之后。所以我们可以得到一个道理:sizeof不用考虑数组越界问题,他不会真的对数组进行检查,只会对数组的类型进行判断,换句话来说我们也可以将sizeof(a[3])写成sizeof(*(int(*)[4]))我们得到的结果依旧是一个元素个数为4的数组,因此我们的答案就是16个字节。我们以上程序的运行效果如下: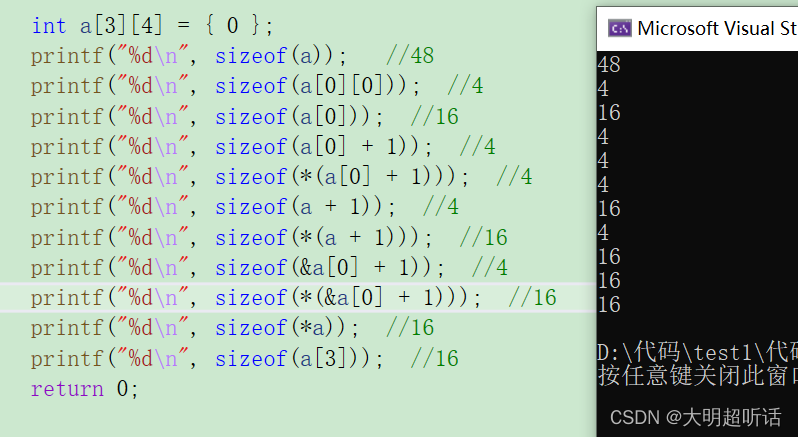
🏍那么我们本次的博客也就正式宣告结束了,希望可以帮到大家,感谢大家的观看,祝大家天天开心。