1.概述
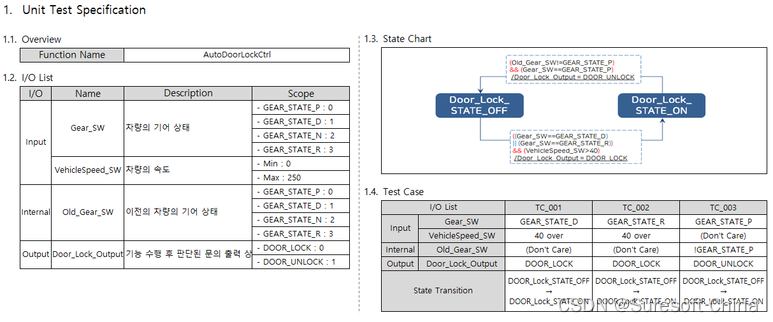
缓存穿透:
当查询的数据在缓存(redis)中没有时,一般业务上就会去查询数据存储(数据库),这种情况称为缓存穿透。穿透的数量太大会造成数据存储撑不住(数据库)而宕机。
解决思路:
用一个结构来记录哪些数据是存在于缓存中的。但这个结构不能太长,要是把所有缓存中的数据都 单独记一条在某个结构中,那就相当于又造了个缓存,完全失去意义。
目前常用的方案是布隆过滤器或者布谷鸟过滤器来解决缓存穿透问题。
2.布隆过滤器
2.1.概述
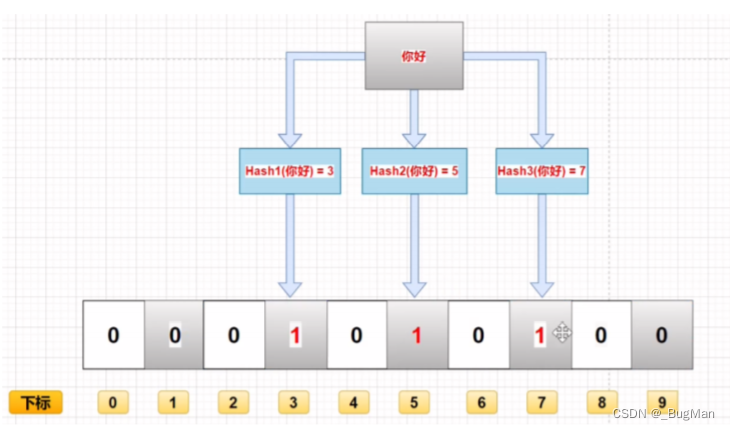
布隆过滤器,1970年由布隆提出,由一个很长的二进制向量来一系列散列函数组成。
2.2.数据操作
2.2.1插入数据
数据输入,通过一系列的散列运算,分别散列映射到到二进制向量的下标上去,在向量的该位置记 录,1表示存在,0表示不存在。
2.2.2查找数据
数据输入,通过一系列的散列运算,计算出下标,去下标对应位置确认,是否为1(数据是否存 在),所有位置均存在(均为1)则表示该数据存在,否则表示该数据不存在。 删除数据 布隆过滤器很难删除,删除的时候很容易造成误删。原因很简单,散列运算可能会造成散列冲突, 即不同的输入散列运算的结果是相同的,二进制向量中单个下标表示的不知一个数据,所以布隆过 滤器很难做到对数据的精准删除。
2.3.优缺点
查询速度快
查询操作的时间复杂度为O(n),n是散列函数的个数。
数据安全
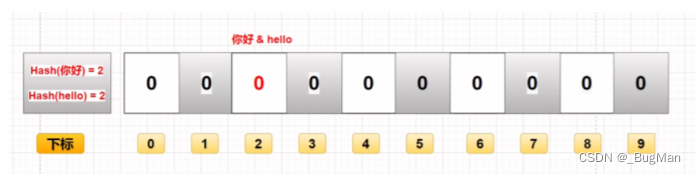
二进制向量中存放的只是判断标志位,一串01二进制数,不存放具体数据,所以数据安全。 存在误判 当数据量大了以后,二进制向量中存在多位1,那么散列运算很可能会完全冲撞,即不存在的数据 进行存在性判断时,也会因为运算出来的下标位上全是1,被误判为存在。误判问题是布隆过滤器 的核心问题,此问题不可解决,只能尽量优化,减少误判。
优化误判的方法:
- 二进制向量的长度与误判率负相关
- 散列函数的数量与误判率负相关
3.布谷鸟过滤器
布谷鸟过滤器是基于布隆过滤器的优化,目的是降低误判。布谷鸟过滤器是基于布隆过滤器的优化,目的是降低误判。
布谷鸟过滤器和布隆过滤器一样,由一个一维数组和一系列hash函数组成,只是其在处理散列冲突时增加了特殊机制,保证了每一位记录的只会是一个数据的存在性标志,规避掉了散列冲突。
例如,输入data1,经过hash1和hash2运算后得到下标为1和2,data1会选择两者中的一个作为自己存在性的标志位。如果后来的数据与data1产生了散列冲突,并且也算选择了要放入下标为1的位置,那么就 会“鸠占鹊巢”,将data1挤走,但是data1不会被丢掉,会跑到自己其它hash函数运算出来的位置,将该 位置作为自己存在性的标志位。如果该位置之前存在数据,同样会“纠缠雀巢”,将原来的数据挤走,被 挤走的数据又继续上面的步骤,以此类推。
3.1.挤兑循环
布谷鸟过滤器存在挤兑循环的问题,即当被挤走的数据一直死循环的执行“鸠占鹊巢”的过程。 例如: data1散列结果为1、2,选择了1 data2散列结果为1、2,选择了2 data3散列结果为1、2,选择了1 data1被挤走,重写选择,自己的hash位,挤走2上面的data2,data2又挤走data3,data3又挤走 data1,陷入死循环.... 挤兑循环出现的概率很低,一般出现在散列函数不佳,算出来的结果大量冲突的情况下。
3.2.扩容机制
当数据多了以后,数组中空位很少时,新数据“鸠占鹊巢”时,会引起一连串的多次的“鸠占鹊巢”,耗时会 指数级别的增加。为了应对这种性能跌落情况,布谷鸟过滤器存在扩容机制,即当单词新数据进入而引 发的全局“鸠占鹊巢”的次数达到阈值后,会触发扩容,扩容后所有老数据会进行rehash,重新找位置。 当然处理散列冲突的最佳机制,其实一直都是hashMap采用的那套思路,在每个hash桶内尽量多的存放 内容。只是布谷鸟过滤器始终只是个数据存在性的记录结构,不可能像hashmap这种真正的数据存储结构一样无限制的在hash桶内增加位置,内存撑不住,而且这约等于记录结构其实就变成了缓存本身。所以布谷鸟过滤器在数组每个位置准备了4个“小座位”,允许4个散列冲突的数据存在一个下标下。