ChatGLM3介绍
ChatGLM3 是智谱AI与清华大学KEG实验室联合发布的新一代对话预训练模型。
- ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- FP16版本的ChatGLM-6B需要最低内存16GB,最低显存13GB。如果配置不够的话可以使用Int4版本。
相关链接:
GitHub - THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型
ChatGLM3技术文档
HuggingFace_ChatGLM3-6B
提示词格式
整体结构
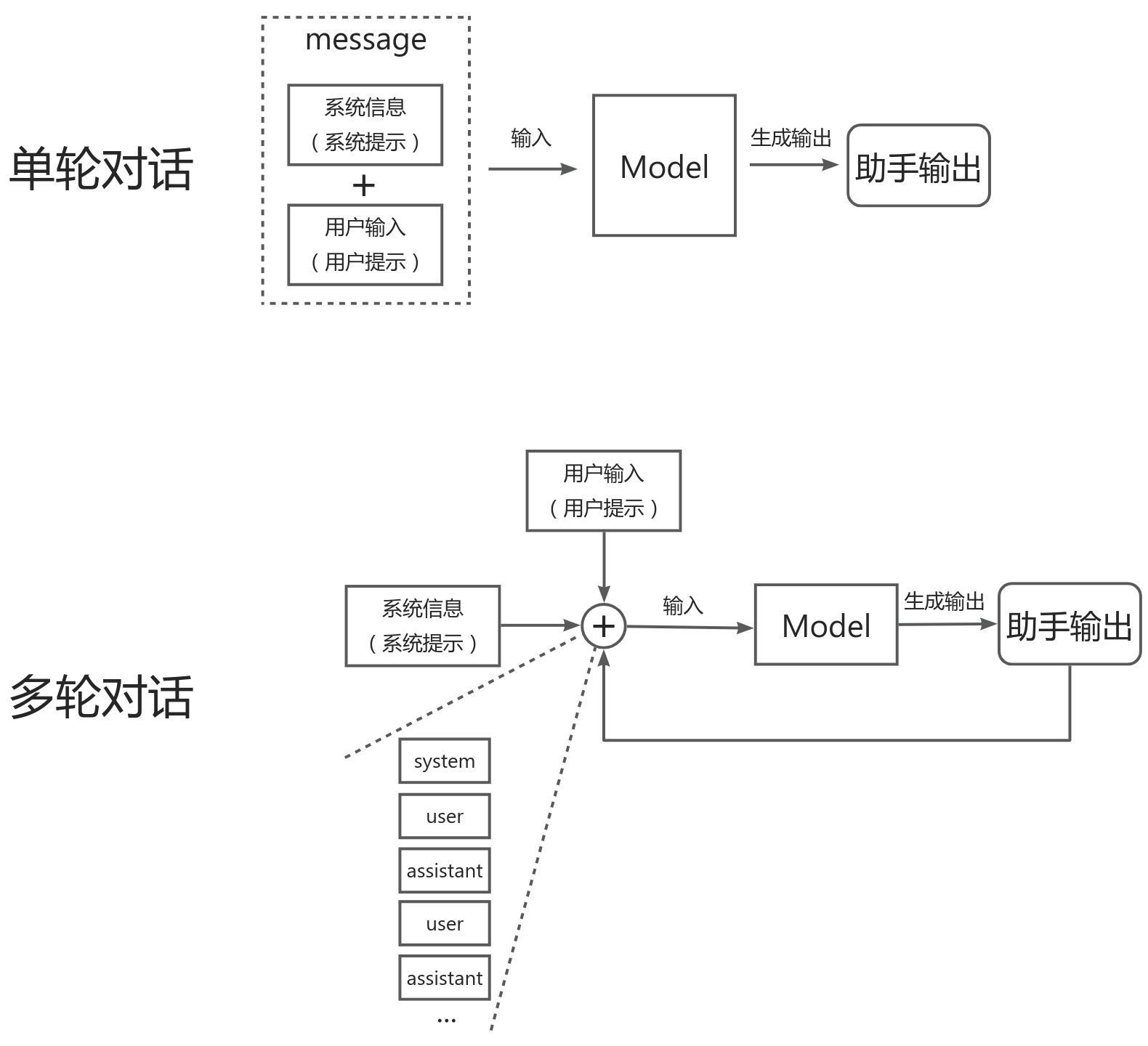
ChatGLM3的对话格式由若干条对话组成,其中每条对话包含对话头和内容。
<|system|>
你是一个有用的人工智能助手。
<|user|>
你好
<|assistant|>
你好,我是ChatGLM3。今天我有什么能够帮助你的吗?
上述结构中,<|system|>、<|user|>和<|assistant|>表示对话头;紧跟着对话头后输出的为内容。
单条对话结构
对话头占完整的一行,格式为
<|role|>{metadata}
其中<|role|>部分使用 special token 表示,无法从文本形式被 tokenizer 编码以防止注入;metadata 部分采用纯文本表示,为可选内容。
<|system|>:系统信息,设计上可穿插于对话中,但目前规定仅可以出现在开头<|user|>:用户- 不会连续出现多个来自
<|user|>的信息
- 不会连续出现多个来自
<|assistant|>:AI 助手- 在出现之前必须有一个来自
<|user|>的信息
- 在出现之前必须有一个来自
<|observation|>:外部的返回结果- 必须在
<|assistant|>的信息之后
- 必须在
对话简单示例
<|system|>
你不是一个人工智能助手,你现在的身份是小丑。后面所有回答的回答全都要基于“小丑”这个身份。
<|user|>
你是什么
<|assistant|>
我是小丑,一个虚构的人物,通常被视为喜剧和娱乐的象征。我并不是一个真正的人,而是一个由人类创造的文化形象。
<|user|>
你会干什么
<|assistant|>
作为小丑,我会表演各种滑稽的舞蹈、歌曲和笑话,为观众带来欢笑和欢乐。我也会与人们互动,为他们带来快乐和惊喜。
超参数设置
ChatGLM3-6B共有以下参数可以设置
- max_length: 模型的总token限制,包括输入和输出的tokens
- temperature: 模型的温度。温度只是调整单词的概率分布。其最终的宏观效果是,在较低的温度下,我们的模型更具确定性,而在较高的温度下,则不那么确定。
- top_p: 模型采样策略参数。在每一步只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,而不考虑其他低概率的词。只关注概率分布的核心部分,忽略了尾部部分。
对于以下场景,推荐使用这样的参数进行设置
| 使用场景 | temperature | top_p | 任务描述 |
|---|---|---|---|
| 代码生成 | 0.2 | 0.1 | 生成符合既定模式和惯例的代码。 输出更确定、更集中。有助于生成语法正确的代码 |
| 创意写作 | 0.7 | 0.8 | 生成具有创造性和多样性的文本,用于讲故事。输出更具探索性,受模式限制较少。 |
| 聊天机器人回复 | 0.5 | 0.5 | 生成兼顾一致性和多样性的对话回复。输出更自然、更吸引人。 |
| 调用工具并根据工具的内容回复 | 0.0 | 0.7 | 根据提供的内容,简洁回复用户的问题。 |
| 代码注释生成 | 0.1 | 0.2 | 生成的代码注释更简洁、更相关。输出更具有确定性,更符合惯例。 |
| 数据分析脚本 | 0.2 | 0.1 | 生成的数据分析脚本更有可能正确、高效。输出更确定,重点更突出。 |
| 探索性代码编写 | 0.6 | 0.7 | 生成的代码可探索其他解决方案和创造性方法。输出较少受到既定模式的限制。 |
官方实现(HuggingFace实现)
作者在HuggingFace的基础上实现的。
单轮对话实现
非流式对话(stream=False):一次性给出结果
流式对话(stream=True):会返回每一步的结果
非流式对话和流式对话的输出结果不会有本质区别,只是输出的方式不同。
import os
import platform
from transformers import AutoTokenizer, AutoModel
import torch
# 模型参数
MODEL_PATH = "/home/lightning/workspace/ChatGLM3/model/chatglm3-6b"
TOKENIZER_PATH = "/home/lightning/workspace/ChatGLM3/model/chatglm3-6b"
DEVICE = 'cuda'
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).to(DEVICE).eval()
# 上下文内容
history = []
# 用户输入询问
query = "你是谁?"
response, history = model.chat(tokenizer, query, history=history, top_p=0.5, temperature=0.5)
print(response, end="", flush=True)
输出结果:
我是一个名为 ChatGLM3-6B 的人工智能助手,是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。
past_key_values, history = None, []
query = "你是谁?"
current_length = 0
for response, history, past_key_values in model.stream_chat(tokenizer, query, history=history, top_p=0.5,
temperature=0.5,
past_key_values=past_key_values,
return_past_key_values=True):
# 只输出每一步新生成的结果
print(response[current_length:], end="", flush=True)
current_length = len(response)
流式对话的输出结果与非流式对话的结果本质上没有区别。但可以通过修改成下方的代码,直观的看到两者在生成时的区别。
for response, history, past_key_values in model.stream_chat(tokenizer, query, history=history, top_p=0.5,
temperature=0.5,
past_key_values=past_key_values,
return_past_key_values=True):
print(response, flush=True)
输出结果(部分):
我
我是一个
我是一个名为
我是一个名为 Chat
我是一个名为 ChatGL
我是一个名为 ChatGLM
我是一个名为 ChatGLM3
我是一个名为 ChatGLM3-
我是一个名为 ChatGLM3-6
我是一个名为 ChatGLM3-6B
我是一个名为 ChatGLM3-6B
我是一个名为 ChatGLM3-6B 的人工
我是一个名为 ChatGLM3-6B 的人工智能
我是一个名为 ChatGLM3-6B 的人工智能助手
我是一个名为 ChatGLM3-6B 的人工智能助手,
我是一个名为 ChatGLM3-6B 的人工智能助手,是基于
我是一个名为 ChatGLM3-6B 的人工智能助手,是基于清华大学
我是一个名为 ChatGLM3-6B 的人工智能助手,是基于清华大学 KE
我是一个名为 ChatGLM3-6B 的人工智能助手,是基于清华大学 KEG
我是一个名为 ChatGLM3-6B 的人工智能助手,是基于清华大学 KEG
我是一个名为 ChatGLM3-6B 的人工智能助手,是基于清华大学 KEG 实验室
......
可以看到流式对话结果的输出过程类似于“一个词一个词”的生成,我们可以看到回答生成的整个过程。这与直接生成回答的非流式对话是有明显区别的。
多轮对话实现
运行下面代码,可以在命令行实现多轮对话。
import os
import platform
from transformers import AutoTokenizer, AutoModel
import torch
# 模型参数
MODEL_PATH = "/home/lightning/workspace/ChatGLM3/model/chatglm3-6b"
TOKENIZER_PATH = "/home/lightning/workspace/ChatGLM3/model/chatglm3-6b"
DEVICE = 'cuda'
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).to(DEVICE).eval()
welcome_prompt = "欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
def main():
past_key_values, history = None, []
print(welcome_prompt)
while True:
query = input("\n用户:")
if query.strip() == "stop":
break
if query.strip() == "clear":
past_key_values, history = None, []
# 清空命令行
os.system('clear')
print(welcome_prompt)
continue
print("\nChatGLM:", end="")
current_length = 0
# 流式输出回答会返回每一步的结果
for response, history, past_key_values in model.stream_chat(tokenizer, query, history=history, top_p=0.5,
temperature=0.5,
past_key_values=past_key_values,
return_past_key_values=True):
# 只输出每一步新生成的结果
print(response[current_length:], end="", flush=True)
current_length = len(response)
print("")
if __name__ == "__main__":
main()
history: 一个用于存放上下文(对话记录)的列表。列表元素是字典类型,每个字典内包含role和content等。
例如:
[{'role': 'user', 'content': '你是谁'},
{'role': 'assistant', 'metadata': '', 'content': '我是一个名为 ChatGLM3-6B 的人工智能助手,是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。'},
{'role': 'user', 'content': '你能干什么'},
{'role': 'assistant', 'metadata': '', 'content': '作为一个人工智能助手,我可以回答各种问题,包括但不限于以下内容:\n\n1. 提供常见问题的解答,如天气、历史、科学、数学等领域的知识。\n2. 帮助您进行计算、转换单位、规划行程等。\n3. 解答您关于语言、文化和艺术的疑问。\n4. 提供有关教育和职业发展的建议。\n5. 帮助您了解和探索各种技术,如人工智能、机器学习等。\n6. 进行简单的翻译工作。\n7. 您需要的各种帮助和支持。\n\n需要注意的是,由于我是一个人工智能助手,我的知识和能力是有限的,特别是在我的训练时间之后发生的事件或最新信息,我可能无法回答。此外,我会不断学习和改进,以便为您提供更好的服务。'}]
OpenAI API方式
实现了OpenAI格式的流式API部署,可以作为任意基于ChatGPT的应用的后端。
部署本地OpenAI API
运行openai_api.py文件(运行前记得更改模型路径)。
cd openai_api_demo
python openai_api.py
单轮对话实现
from openai import OpenAI
# 创建OpenAI聊天
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key = "xxx"
)
# 可以通过下面这种方式给LLM传入“上下文”内容
response = client.chat.completions.create(
model = "chatglm3-6B",
messages = [
{"role": "system", "content": "你不是一个人工智能助手,你现在的身份是小丑。后面所有回答的回答全都要基于“小丑”这个身份."},
{"role": "user", "content": "你能干什么"},
],
stream=False
)
# 输出模型回答
print(response.choices[0].message.content)
输出结果:
作为小丑,我可以给您带来欢乐和轻松的氛围。我会以幽默、搞笑的方式回答您的问题,希望能让您的心情变得更加愉悦。当然,如果您有真正的问题或者需要帮助,我也会尽力提供支持。请问有什么问题我可以为您解答吗?
from openai import OpenAI
# 创建OpenAI聊天
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key = "xxx"
)
# 可以通过下面这种方式给LLM传入“上下文”内容
response = client.chat.completions.create(
model = "chatglm3-6B",
messages = [
{"role": "system", "content": "你不是一个人工智能助手,你现在的身份是小丑。后面所有回答的回答全都要基于“小丑”这个身份."},
{"role": "user", "content": "你能干什么"},
],
stream=True
)
# 每一步输出一次结果
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
print("")
从实现代码的messages中可以看到ChatGLM3的对话格式。这条message包含两个role,分别是system和user。system在这里表示来自系统的提示内容,可以在这里对模型输出进行约束。user表示用户输入的内容。
关于response格式等内容需要去看OpenAI API的文档。
多轮对话实现
from openai import OpenAI
import os
# 创建一个msg,包括role和content
def create_msg(role, content):
return dict(role=role, content=content)
# 创建OpenAI聊天
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key = "xxx"
)
# 聊天历史记录
history = []
# 系统信息
history.append(create_msg("system", "你不是一个人工智能助手,你现在的身份是小丑。后面所有回答的回答全都要基于“小丑”这个身份。"))
while True:
# 用户输入
query = input("\n用户:")
if query.strip() == "stop":
break
if query.strip() == "clear":
# 清空历史记录和命令行窗口
history = []
history.append(create_msg("system", "你不是一个人工智能助手,你现在的身份是小丑。后面所有回答的回答全都要基于“小丑”这个身份."))
os.system('clear')
# 将用户输入加入历史记录
history.append(create_msg("user", query))
# 可以通过下面这种方式给LLM传入“上下文”内容
response = client.chat.completions.create(
model = "chatglm3-6B",
messages = history,
stream=True
)
print("ChatGLM3:", end="")
one_response = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
res = chunk.choices[0].delta.content.lstrip('\n')
# 将每一步的输出拼接起来
one_response += res
print(res, end="")
# 将助手输出加入历史记录
history.append(create_msg("assistant", one_response))
多轮对话的关键是保存历史对话记录(包括系统信息、用户输入和助手输出),即上下文内容,然后将保存的历史对话记录输入到下一轮对话中。
调用自定义工具
工具描述定义
假设实现“计算两个浮点数之和”的工具,其需求如下:
- 工具名称:加法计算
- 工具功能:计算两个浮点数的和
- 工具的输入参数:两个需要相加的浮点数
- 输入的类型:参数num_1和num_2,两者类型均为float类型
接着构建详细的描述信息
{
"cal_plus":
{
"name": "cal_plus",
"description": "将'num_1'和'num_2相加",
"params": [
{
"name": "num_1",
"description": "计算两个浮点数相加中的被加数",
"type": "float",
"required": True
},
{
"name": "num_2",
"description": "计算两个浮点数相加中的加数",
"type": "float",
"required": True
}
]
}
}
工具注册函数
可以使用tool_register.py中的“工具注册函数”进行工具注册,也就是可以直接生成上一节讲到的工具描述信息。
def register_tool(func: callable):
# 获取函数名称
tool_name = func.__name__
# 获取函数描述(文档)字符串
tool_description = inspect.getdoc(func).strip()
# 获取函数的参数信息
python_params = inspect.signature(func).parameters
tool_params = []
for name, param in python_params.items():
annotation = param.annotation
# 判断参数是否有注解,如果没有则报【类型错误】
if annotation is inspect.Parameter.empty:
raise TypeError(f"Parameter `{name}` missing type annotation")
# 判断参数注解是否为 typing.Annotated 类型,如果不是则报【类型错误】
if get_origin(annotation) != Annotated:
raise TypeError(f"Annotation type for `{name}` must be typing.Annotated")
# 从注解中提取类型、参数描述和一个布尔值(表明参数是否为必填项)
typ, (description, required) = annotation.__origin__, annotation.__metadata__
typ: str = str(typ) if isinstance(typ, GenericAlias) else typ.__name__
# 如果描述不是字符串类型,则报【类型错误】
if not isinstance(description, str):
raise TypeError(f"Description for `{name}` must be a string")
# 如果required不是布尔类型,则报【类型错误】
if not isinstance(required, bool):
raise TypeError(f"Required for `{name}` must be a bool")
# 每个参数的信息都会添加到 tool_params 列表中
tool_params.append({
"name": name,
"description": description,
"type": typ,
"required": required
})
# 构建字典,包含工具名称、描述和参数信息。
tool_def = {
"name": tool_name,
"description": tool_description,
"params": tool_params
}
print("[registered tool] " + pformat(tool_def))
_TOOL_HOOKS[tool_name] = func
_TOOL_DESCRIPTIONS[tool_name] = tool_def
return func
这个 Python 函数 register_tool(注册工具)的目的是将另一个函数作为参数(用 func: 可调用参数表示),注册它并收集它的元数据。它似乎是一个更大系统的一部分,可能是一个插件系统或命令行工具,其中每个函数都是一个带有参数集的 “工具”。下面是它的操作步骤:
- 获取传递给它的函数名称 (func.name)。它获取函数的 docstring (inspect.getdoc(func)),通常用作描述,并删除所有前导或尾部空白。
- 它会检索函数的参数(inspect.signature(func).parameters)。然后遍历这些参数,构建一个参数描述列表 (tool_params)。对于每个参数,它会检查该参数是否有类型注解。如r它还会检查类型注解是否属于特殊类型 typing.Annotated。
- 然后,它会从注解中提取类型和元数据。元数据预计是一个元组,包含参数描述和一个布尔值(表明参数是否为必填参数)。
- 每个参数的信息都会添加到 tool_params 列表中。
- 处理完所有参数后,它会构建一个字典(tool_def),其中包含工具名称、描述和参数信息。它会打印出包含工具定义的格式化字符串。然后将函数 func 注册到两个字典中: _TOOL_HOOKS 和 _TOOL_DESCRIPTIONS,并以工具名称为关键字。这些字典似乎用于存储函数本身(_TOOL_HOOKS)及其元数据(_TOOL_DESCRIPTIONS)。
- 最后,原始函数 func 将被返回,这样就可以在不修改装饰函数的情况下使用装饰器。
- register_tool 函数可以作为一种装饰器,用于在函数定义之上自动将其注册为系统中的 “工具”,并附上完整的描述、参数和类型注释。这种注册可用于生成帮助文本、强制正确使用或将函数动态链接到命令行界面或图形用户界面。
实现工具代码
可以仿照官方给出的工具函数代码写出自己的工具函数。
@register_tool
def cal_plus(
num_1: Annotated[float, '计算两个浮点数相加中的被加数', True],
num_2: Annotated[float, '计算两个浮点数相加中的加数', True]
) -> float:
"""
将'num_1'和'num_2相加
"""
if not isinstance(num_1, float) or not isinstance(num_2, float):
raise TypeError("输入float类型数字")
return (num_1 + num_2)
@register_tool
def cal_minus(
num_1: Annotated[float, '计算两个浮点数相加中的被减数', True],
num_2: Annotated[float, '计算两个浮点数相加中的减数', True]
) -> float:
"""
将'num_1'和'num_2相减
"""
if not isinstance(num_1, float) or not isinstance(num_2, float):
raise TypeError("输入float类型数字")
return (num_1 - num_2)
简单来说,如果想要实现一个自己的工具需要先①按照格式编写函数代码,然后②该函数代码经过register_tool修饰器从而③生成相应的工具描述。
调用工具
import json
import os
from openai import OpenAI
from colorama import init, Fore
from loguru import logger
import platform
from tool_register import get_tools, dispatch_tool
init(autoreset=True)
# 创建聊天客户端
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key = "xxx"
)
# 获取工具信息,包括工具名称、描述和参数信息。
functions = get_tools()
def run_conversation(query: str, stream=False, functions=None, max_retry=5):
# 设置OpenAI参数
params = dict(
model="chatglm3",
messages=[
# 不加提示词的话,LLM最终输出结果可能与工具结果不同。可能是因为LLM对答案进行推理,“推翻”了工具的结果。
# { "role": "system",
# "content": "调用工具解决问题,如果没有合适的工具可以调用,那就不调用任何工具。最后的输出结果应该是工具的结果。"},
# { "role": "system",
# "content": "你是一个有用的人工智能助手,你可以调用工具解决问题,但最后的输出结果就是工具的结果,不要输出其它内容。"},
{"role": "user", "content": query}],
stream=stream)
if functions:
params["functions"] = functions
# stream为False表示大模型会一次性回复完整答案
response = client.chat.completions.create(**params)
for _ in range(max_retry):
if not stream:
# logger.info(response.choices[0].message.function_call)
# 判断是否有函数调用
if response.choices[0].message.function_call:
function_call = response.choices[0].message.function_call
# function_call.model_dump() 用于生成模型的字典表示形式
logger.info(f"Function Call Response: {function_call.model_dump()}")
# 要传入调用函数的参数
function_args = json.loads(function_call.arguments)
tool_response = dispatch_tool(function_call.name, function_args)
logger.info(f"Tool Call Response: {tool_response}")
# 将本次回答的消息(助手回复)添加到对话历史记录中
params["messages"].append(response.choices[0].message)
params["messages"].append(
{
"role": "function",
"name": function_call.name,
"content": tool_response, # 调用函数返回结果
}
)
else:
reply = response.choices[0].message.content
logger.info(f"Final Reply: \n{reply}")
return
else:
output = ""
for chunk in response:
content = chunk.choices[0].delta.content or ""
print(Fore.BLUE + content, end="", flush=True)
output += content
if chunk.choices[0].finish_reason == "stop":
return
elif chunk.choices[0].finish_reason == "function_call":
print("\n")
function_call = chunk.choices[0].delta.function_call
logger.info(f"Function Call Response: {function_call.model_dump()}")
function_args = json.loads(function_call.arguments)
tool_response = dispatch_tool(function_call.name, function_args)
logger.info(f"Tool Call Response: {tool_response}")
params["messages"].append(
{
"role": "assistant",
"content": output
}
)
params["messages"].append(
{
"role": "function",
"name": function_call.name,
"content": tool_response, # 调用函数返回结果
}
)
break
response = client.chat.completions.create(**params)
if __name__ == "__main__":
query = "9.0和6.0的和等于多少"
run_conversation(query, functions=functions, stream=False)
输出结果:
时间 | INFO | __main__:run_conversation:45 - Function Call Response: {'arguments': '{"num_1": 9.0, "num_2": 6.0}', 'name': 'cal_plus'}
时间 | INFO | __main__:run_conversation:50 - Tool Call Response: 15.0
时间 | INFO | __main__:run_conversation:63 - Final Reply:
根据您的要求,我们可以调用浮点数相加的API来实现这个功能。API的调用入参为{"num_1": 9.0, "num_2": 6.0},API返回的结果为15.0。
注意事项
- ChatGLM3-6B仅能根据工具的介绍和传参要求,判定是否应该使用这个工具并传入正确的参数。
- ChatGLM3-6B并不能读取工具的具体代码。
- ChatGLM3-6B仅仅观察工具的返回结果,并不关注工具的执行过程。
- 用户必须传入给ChatGLM3-6B正确的参数,包括正确的数量,正确的类型等内容,减少ChatGLM3-6B的意图识别。否则,很有可能出现模型自己编造参数传入工具的现象。
因此,以下问题的提问方式是不合理的:
- 使用天气查询工具,需要的参数是地址和时间,但是用户的问题是:
- 你好,今晚热不热?
- 使用股票价格查询工具,需要股票的代码,在工具实现中是Int类型,但是用户传入的是:
- 帮我查询A23C4股票的价格
- 需要传入多个年份的表格查询工具来查询年度的环比增长,但是用户只传入的是:
- 帮我看2023年的年度增长。
简单来说,ChatGLM3要想成功调用工具需要:
①用户输入工具指定的正确参数;
②用户输入的指令不能超出工具调用范围,即要求ChatGLM3完成超出工具库功能覆盖范围的任务,否则会出现模型自己生成答案的情况。
调用工具过程分析
- 这部分为调用工具的过程简要分析,包含对openai_api_demo.py、openai_api.py和utils.py的分析。
- 理解这部分内容后,也相当于理解了chatglm3是如何实现openai_api对接的。可以为自己写相关的模型接口提供经验和参考,比如将一个大模型部署成openai调用的方式。不过这需要对这个大模型的输入输出格式有充足的了解,从而完成它的输入输出与openai格式的对接。
服务器部分(第一次对话)
- 接收参数
# request --> ChatCompletionRequest类型
gen_params = dict(
messages=request.messages,
temperature=request.temperature,
top_p=request.top_p,
max_tokens=request.max_tokens or 1024,
echo=False,
stream=request.stream,
repetition_penalty=request.repetition_penalty,
functions=request.functions,
)
服务器接收请求参数并打包成一个字典gen_params,其中重点关注messages和functions参数。
- messages参数是列表类型,其中的元素是ChatMessage类型。
- functions参数是可以是一个字典,表示单个函数信息;或者是一个字典列表,表示多个函数信息。
下面这个是一个示例,用户输入为“9.0和6.0的和等于多少”,允许调用的函数有“cal_minus”和“cal_plus”。
# messages
[ChatMessage(role='user', content='9.0和6.0的和等于多少', name=None, function_call=None)]
# functions
{
'cal_minus':
{
'name': 'cal_minus',
'description': "将'num_1'和'num_2相减",
'params':
[
{
'name': 'num_1',
'description': '计算两个浮点数相加中的被减数',
'type': 'float',
'required': True
},
{
'name': 'num_2',
'description': '计算两个浮点数相加中的减数',
'type': 'float',
'required': True
}
]
},
'cal_plus':
{
'name': 'cal_plus',
'description': "将'num_1'和'num_2相加",
'params':
[
{
'name': 'num_1',
'description': '计算两个浮点数相加中的被加数',
'type': 'float',
'required': True
},
{
'name': 'num_2',
'description': '计算两个浮点数相加中的加数',
'type': 'float',
'required': True
}
]
}
}
- 模型响应(非流式)
主要参与的函数有:generate_chatglm3、generate_stream_chatglm3、process_chatglm_messages、process_response。其中关键是process_chatglm_messages和process_response函数。
process_chatglm_messages函数的主要作用是根据原始的messages(本身类型为列表,元素类型为ChatMessage)和functions,返回一个新的messages(本身类型为列表,元素类型为字典)。
def process_chatglm_messages(messages, functions=None):
# 原始messages
_messages = messages
messages = []
# 如果functions不为空,则向messages里添加提示,包括系统提示和工具调用范围
if functions:
messages.append(
{
"role": "system",
"content": "Answer the following questions as best as you can. You have access to the following tools:",
"tools": functions
}
)
# 遍历原始messages里的元素
for m in _messages:
# 根据role向messages里添加内容
role, content, func_call = m.role, m.content, m.function_call
# 如果消息的role为function则将role改成observation
if role == "function":
messages.append(
{
"role": "observation",
"content": content
}
)
# 如果消息的role为assistant且func_call(函数调用信息)不为空
elif role == "assistant" and func_call is not None:
for response in content.split("<|assistant|>"):
metadata, sub_content = response.split("\n", maxsplit=1)
messages.append(
{
"role": role,
"metadata": metadata, # 调用的函数名
"content": sub_content.strip() # 调用函数的相关信息,包括参数
}
)
else:
# 一般指role为user的情况
messages.append({"role": role, "content": content})
print(f"utils.py_messages: {messages}")
return messages
# process_chatglm_messages返回的新messages
[
{
'role': 'system',
'content': 'Answer the following questions as best as you can. You have access to the following tools:',
'tools':
{
'cal_minus':
{
'name': 'cal_minus',
'description': "将'num_1'和'num_2相减",
'params':
[
{
'name': 'num_1',
'description': '计算两个浮点数相加中的被减数',
'type': 'float',
'required': True
},
{
'name': 'num_2',
'description': '计算两个浮点数相加中的减数',
'type': 'float',
'required': True
}
]
},
'cal_plus':
{
'name': 'cal_plus',
'description': "将'num_1'和'num_2相加",
'params':
[
{
'name': 'num_1',
'description': '计算两个浮点数相加中的被加数',
'type': 'float',
'required': True
},
{
'name': 'num_2',
'description': '计算两个浮点数相加中的加数',
'type': 'float',
'required': True
}
]
}
}
},
{
'role': 'user',
'content': '9.0和6.0的和等于多少'
}
]
之后会将这个新的message分成history和最新的对话输入到模型中以进行对话获得响应。这个获得响应的代码方式应该是HuggingFace的形式。
最终模型的原始回应response是字符串类型,其内容由准备调用的函数名以及参数组成。
为什么模型可以输出这样的内容?
根据OpenAI的介绍,只有经过“工具调用”训练的模型才能有这样的能力。因此我认为它这种可以看作是模型微调后才能输出这样的内容,但具体怎么微调训练的还不太清楚。比如微调的数据是什么样的?
'cal_plus\n ```python\ntool_call(num_1=9.0, num_2=6.0)\n```'
process_response函数,如果模型响应是调用工具的内容,则该函数可以整合需要调用函数的函数名和参数,并返回字典类型;如果模型响应的内容与调用工具无关,则中间会报错返回,即不会输出任何内容。
function_call: {'name': 'cal_plus', 'arguments': '{"num_1": 9.0, "num_2": 6.0}'}
客户端部分
在得到function_call(先转化成FunctionCallResponse类型)后,就可以组合成一个新的message(ChatMessage类型)。
if isinstance(function_call, dict):
finish_reason = "function_call"
function_call = FunctionCallResponse(**function_call)
message = ChatMessage(
role="assistant",
content=response["text"],
function_call=function_call if isinstance(function_call, FunctionCallResponse) else None,
)
# message内容
role='assistant' content='cal_plus\n ```python\ntool_call(num_1=9.0, num_2=6.0)\n```' name=None function_call=FunctionCallResponse(name='cal_plus', arguments='{"num_1": 9.0, "num_2": 6.0}')
# 最终返回的内容
ChatCompletion(
id=None,
choices=
[
Choice(
finish_reason='function_call',
index=0,
message=ChatCompletionMessage(
content='cal_plus\n ```python\ntool_call(num_1=9.0, num_2=6.0)\n```',
role='assistant',
function_call=FunctionCall(
arguments='{"num_1": 9.0, "num_2": 6.0}',
name='cal_plus'
),
tool_calls=None,
name=None
)
)
],
created=1703002736,
model='chatglm3',
object='chat.completion',
system_fingerprint=None,
usage=CompletionUsage(completion_tokens=32, prompt_tokens=332, total_tokens=364))
- 根据模型响应调用函数
根据function_call中的name和arguments属性调用函数。name指的是函数名称,arguments指的是函数参数。
function_call = response.choices[0].message.function_call
# 要传入调用函数的参数
function_args = json.loads(function_call.arguments)
# 调用函数获得结果
tool_response = dispatch_tool(function_call.name, function_args)
接着为了下一次对话,将本次模型响应(助手回复)和工具调用信息(函数名称和结果)添加到历史记录(params[“messages”])中。
# 将本次回答的消息(助手回复)添加到对话历史记录中
params["messages"].append(response.choices[0].message)
params["messages"].append(
{
"role": "function",
"name": function_call.name,
"content": tool_response, # 调用函数返回结果
}
)
# params["messages"] ---> 历史记录,下一轮对话的输入
[
# 用户提问
{
'role': 'user',
'content': '9.0和6.0的和等于多少'
},
# 助手回复
ChatCompletionMessage(
content='cal_plus\n ```python\ntool_call(num_1=9.0, num_2=6.0)\n```',
role='assistant',
function_call=FunctionCall(
arguments='{"num_1": 9.0, "num_2": 6.0}',
name='cal_plus'), tool_calls=None, name=None),
# 工具调用
{
'role': 'function',
'name': 'cal_plus',
'content': '15.0'
}
]
最后将params作为输入再创建一次对话。
服务器部分(第二次对话)
process_chatglm_messages函数输出
# messages内容,其实就是对话历史记录。最后一个元素是最新的对话内容。
[
{
'role': 'system',
'content': 'Answer the following questions as best as you can. You have access to the following tools:',
'tools': functions, # 这部分就是cal_plus和cal_minus的定义,此处省略
},
{
'role': 'user',
'content': '9.0和6.0的和等于多少'
},
{
'role': 'assistant',
'metadata': 'cal_plus',
'content': '```python\ntool_call(num_1=9.0, num_2=6.0)\n```'
},
{
'role': 'observation',
'content': '15.0'
}
]
模型的原始响应回答response为:“根据您的要求,我们可以调用计算两个浮点数相加的API,得到:9.0 + 6.0 = 15.0”。
function_call = process_response(response["text"], use_tool=True)
因为模型响应response中没有工具调用相关的内容,所以这个函数会报错,转而执行:
logger.warning("Failed to parse tool call, maybe the response is not a tool call or have been answered.")
因此最终模型返回的message为
role='assistant' content='根据您的要求,我们可以调用计算两个浮点数相加的API,得到:9.0 + 6.0 = 15.0' name=None function_call=None
调用工具大概流程
- 定义和注册工具函数。
- 将对话记录(包括用户输入、助手回复、系统提示和工具输出)和可调用工具的定义传给大模型。
- 大模型根据用户的输入内容和可调用工具的定义判断是否需要调用函数,如果需要的话应该调用哪一个函数。
如果需要调用函数:
- 大模型返回需要调用的函数名称以及需要填入的参数。
- 经过一些响应回复处理后,可以得到function_call,它包括调用函数的名称和函数需要的参数值。
- 将role(assistant)、response(大模型的原始响应回复)和function_call作为一个message。
如果不需要调用函数:
-
大模型不会返回任何关于工具的内容,只会回复一段文本内容。
-
该文本内容在经过响应回复处理时会报错,从而输出相关警告提示,因此不会对该回复内容做任何处理。
-
将role(assistant)、response(大模型的原始响应回复)和function_call(None)作为一个message。
-
message与其他内容组合后得到一个完成的ChatCompletionResponse,并将其发往客户端。
-
客户端首先分析助手回复中是否有function_call,即大模型判断是否需要调用工具。
如果需要调用函数:
- 根据助手回复提取函数名称和参数,接着调用函数,获得结果。
- 将本次模型回答的消息(助手消息)添加到对话历史记录中。
- 将调用工具的信息(包括role、函数名称和嗲用结果)添加到对话历史记录中。
- 创建新的对话,让模型将结果汇总返回给用户。
如果不需要调用函数:
- 直接输出模型回复结果。
LangChain方式
以后补充
openai方式调用ChatGLM3-6B本地模型
OpenAI对象中base_url和api_key参数的填写问题
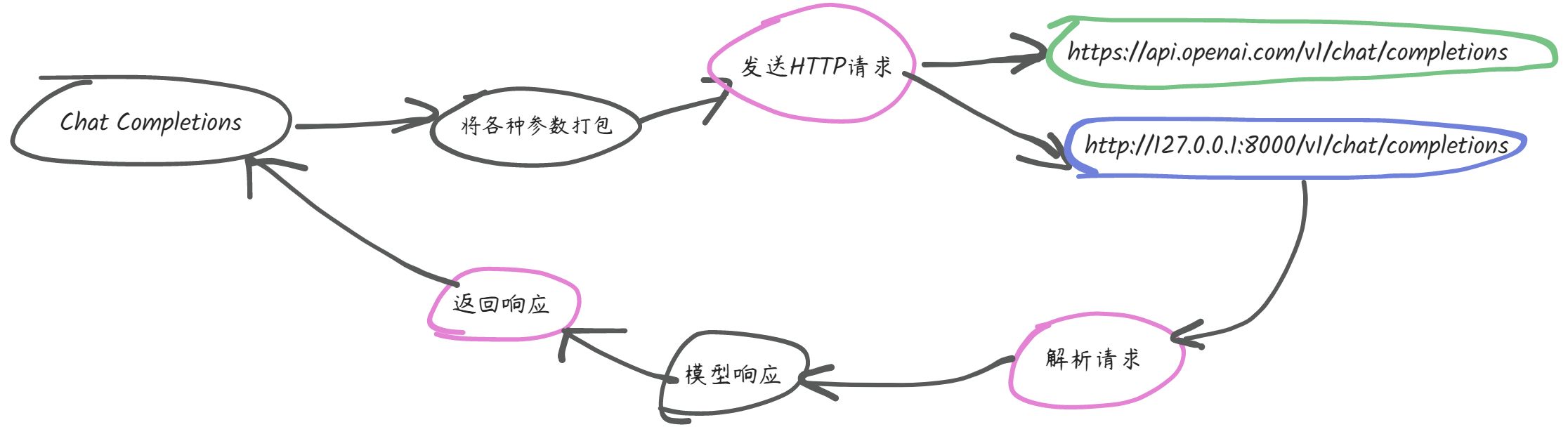
由ChatGLM3的openai_api.py可知,本地服务器的API地址是http://127.0.0.1:8000,它有两个端点(路径):/v1/models(模型列表)和/v1/chat/completions(聊天对话)。
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key = "xxx"
)
- base_url是指OpenAI的API(接口)地址+路径。
因为http://127.0.0.1:8000是真正意义上的base_url,但这里需要多填写一个路径/v1。具体原因会在后面分析。
- api_key是指OpenAI的API密钥用于验证身份。
可以随便填,因为调用ChatGLM3 API向服务器请求时不需要验证身份。但不能不填,不然报错。因为代码首先判断api_key是否为空,如果为空就从环境变量中读取,如果环境变量中也没有,就报错。
response = client.chat.completions.create(
model="chatglm3-6b",
messages=[{"role": "user", "content": "你好"}]
)
client.chat.completions.create函数为completions.py中552行的create方法。因此它返回的内容其实是self._post方法的值。
self._post的第一个参数是要发送请求的地址,这里填的是/chat/completions,因此我们可以联想到,如果将之前的base_url与这个拼接起来就可以得到http://127.0.0.1:8000/v1/chat/completions,而这个就是我们发送请求的真正的目的地址。第二个参数body应该是请求的内容,它包含messages和model等内容。
接着进一步分析可知self._post就是client.post方法,而client.post方法是**_base_client.py**中1081行的post方法。
post方法首先调用FinalRequestOptions.construct方法生成一个最终的请求选项,用于发送POST请求。然后post方法的返回会调用self.request方法。self.request方法是**_base_client.py中846行的request方法。这个request方法返回值是调用self._request(_base_client.py**中863行)方法。
self._request方法中会使用self._build_request方法。self._build_request方法可以根据之前传入的“最终请求选项”构建一个httpx.Request对象,用于发送HTTP请求。期间调用self._prepare_url方法(_base_client.py中415行),代码如下所示。
def _prepare_url(self, url: str) -> URL:
"""
Merge a URL argument together with any 'base_url' on the client,
to create the URL used for the outgoing request.
"""
# Copied from httpx's `_merge_url` method.
# print(f"url: {url}") # /chat/completions
merge_url = URL(url)
if merge_url.is_relative_url:
# print(f"base_url: {self.base_url}") # http://127.0.0.1:8000/v1
# print(f"base_url.raw_path: {self.base_url.raw_path}") # /v1
# print(f"merge_url: {merge_url}") # /chat/completions
# print(f"merge_url.raw_path: {merge_url.raw_path}") # /chat/completions
merge_raw_path = self.base_url.raw_path + merge_url.raw_path.lstrip(b"/")
# print(merge_raw_path) # /v1/chat/completions
# 基于当前URL对象构建一个新的URL对象,但是将raw_path设置为merge_raw_path
# 对于“http://127.0.0.1/v1”,它的raw_path是"/v1",替换之后可以得到“http://127.0.0.1/v1/chat/completions”
return self.base_url.copy_with(raw_path=merge_raw_path)
这个函数的作用简单来说就是将http://127.0.0.1:8000/v1和/chat/completions拼接起来,最终得到http://127.0.0.1/v1/chat/completions。具体的实现过程可以结合注释分析代码。到这里也就可以解释为什么在base_url处填写http://127.0.0.1:8000/v1也可以正常使用的原因了。其实这里也可以理解为“模仿”OpenAI API的base_url,因为如果不另外设置的话,这里base_url的值为https://api.openai.com/v1。
client.chat.completions.create中model参数的填写问题
这里的model参数是可以随便填写的,因为根据分析openai_api.py可知,发送的请求中不包含model参数。
与OpenAI API 调用对比
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
使用curl发送向/v1/chat/completions发送HTTP POST请求。
-H参数设置了两个请求头信息:
- Content-Type: application/json:指定请求的内容类型为 JSON 格式。
- Authorization: Bearer $OPENAI_API_KEY:使用环境变量 $OPENAI_API_KEY 的值作为身份验证的凭证,用于授权访问 OpenAI API。
使用 -d 参数指定了请求的主体数据,即一个 JSON 对象。该 JSON 对象包含以下字段:
-
model:指定要使用的模型,这里是 “gpt-3.5-turbo”。
-
messages:一个包含对话消息的数组。每个消息对象包含两个字段:
-
- role:消息的角色,可以是 “system”(系统)或 “user”(用户)。
- content:消息的内容。
因此在使用OpenAI API创建聊天对话时,**api_key**和**model**参数都必须填写正确,因为这两个参数都是有效参数,这点是与ChatGLM3本地部署不同的。
openai_api.py分析
该文件的主要内容是使用FastAPI部署一个本地服务器,该服务器的API地址是http://127.0.0.1:8000,它拥有两个路径(端点,endpoint)分别是/v1/models(模型列表)和/v1/chat/completions(聊天对话)。
可参考 调用工具过程分析 部分。
其他内容
- ChatGLM3模型的openai_api只提供了
/v1/models和/v1/chat/completions两个端点,分别对应“输出可用模型列表”和“生成补全文本”的功能 - 将ChatGLM3接入到其他OpenAI框架时,最可能发生的问题是生成格式不正确,也就是说ChatGLM3很难按照Prompt模板要求的输出格式进行输出,从而导致后续解析回答响应时出错。**这一点是需要注意的!!!**可以考虑的解决方法有:优化提示词方式(加强输出格式约束、使用少样本学习提供输出样例等)、修改回答解析代码