第二部分:函数作为对象
第七章:函数作为一等对象
我从未认为 Python 受到函数式语言的重大影响,无论人们说什么或想什么。我更熟悉命令式语言,如 C 和 Algol 68,尽管我将函数作为一等对象,但我并不认为 Python 是一种函数式编程语言。
Guido van Rossum,Python BDFL¹
Python 中的函数是一等对象。编程语言研究人员将“一等对象”定义为一个程序实体,可以:
-
在运行时创建
-
赋值给变量或数据结构中的元素
-
作为参数传递给函数
-
作为函数的结果返回
在 Python 中,整数、字符串和字典是函数的一等对象的其他示例——这里没有什么花哨的东西。将函数作为一等对象是函数式语言(如 Clojure、Elixir 和 Haskell)的一个重要特性。然而,一等函数非常有用,以至于它们被流行的语言(如 JavaScript、Go 和 Java(自 JDK 8 起))采用,这些语言都不声称自己是“函数式语言”。
本章和第三部分的大部分内容探讨了将函数视为对象的实际应用。
提示
术语“一等函数”被广泛用作“函数作为一等对象”的简称。这并不理想,因为它暗示了函数中的“精英”。在 Python 中,所有函数都是一等对象。
本章的新内容
部分“可调用对象的九种类型”在本书第一版中标题为“可调用对象的七种类型”。新的可调用对象是原生协程和异步生成器,分别在 Python 3.5 和 3.6 中引入。它们都在第二十一章中介绍,但为了完整起见,它们与其他可调用对象一起提及在这里。
“仅位置参数” 是一个新的部分,涵盖了 Python 3.8 中添加的一个特性。
我将运行时访问函数注解的讨论移到了“在运行时读取类型提示”。在我写第一版时,PEP 484—类型提示 仍在考虑中,人们以不同的方式使用注解。自 Python 3.5 起,注解应符合 PEP 484。因此,在讨论类型提示时,最好的地方是在这里。
注意
本书的第一版有关函数对象内省的部分过于低级,分散了本章的主题。我将这些部分合并到了一个名为“函数参数内省”在 fluentpython.com的帖子中。
现在让我们看看为什么 Python 函数是完整的对象。
将函数视为对象
示例 7-1 中的控制台会话显示了 Python 函数是对象。在这里,我们创建一个函数,调用它,读取其 __doc__ 属性,并检查函数对象本身是否是 function 类的一个实例。
示例 7-1。创建和测试一个函数,然后读取其 __doc__ 并检查其类型
>>> def factorial(n): # ①
... """returns n!"""
... return 1 if n < 2 else n * factorial(n - 1)
...
>>> factorial(42)
1405006117752879898543142606244511569936384000000000 >>> factorial.__doc__ # ②
'returns n!' >>> type(factorial) # ③
<class 'function'>
①
这是一个控制台会话,所以我们在“运行时”创建一个函数。
②
__doc__ 是函数对象的几个属性之一。
③
factorial 是 function 类的一个实例。
__doc__ 属性用于生成对象的帮助文本。在 Python 控制台中,命令 help(factorial) 将显示类似于 图 7-1 的屏幕。
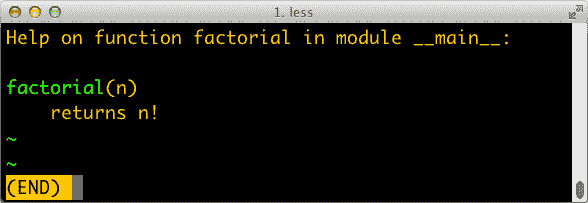
图 7-1。factorial 的帮助屏幕;文本是从函数的 __doc__ 属性构建的。
示例 7-2 展示了函数对象的“第一类”特性。我们可以将其赋值给变量fact,并通过该名称调用它。我们还可以将factorial作为参数传递给map函数。调用map(function, iterable)会返回一个可迭代对象,其中每个项目都是调用第一个参数(一个函数)对第二个参数(一个可迭代对象)中的连续元素的结果,本例中为range(10)。
示例 7-2. 通过不同名称使用factorial,并将factorial作为参数传递
>>> fact = factorial
>>> fact
<function factorial at 0x...>
>>> fact(5)
120
>>> map(factorial, range(11))
<map object at 0x...>
>>> list(map(factorial, range(11)))
[1, 1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800]
拥有头等函数使得以函数式风格编程成为可能。函数式编程的一个特点是使用高阶函数,我们的下一个主题。
高阶函数
一个将函数作为参数或返回函数作为结果的函数是高阶函数。一个例子是map,如示例 7-2 所示。另一个是内置函数sorted:可选的key参数允许您提供一个要应用于每个项目以进行排序的函数,正如我们在“list.sort 与 sorted 内置函数”中看到的。例如,要按长度对单词列表进行排序,可以将len函数作为key传递,如示例 7-3 所示。
示例 7-3. 按长度对单词列表进行排序
>>> fruits = ['strawberry', 'fig', 'apple', 'cherry', 'raspberry', 'banana']
>>> sorted(fruits, key=len)
['fig', 'apple', 'cherry', 'banana', 'raspberry', 'strawberry']
>>>
任何一个参数为一个参数的函数都可以用作键。例如,为了创建一个韵典,将每个单词倒着拼写可能很有用。在示例 7-4 中,请注意列表中的单词根本没有改变;只有它们的反向拼写被用作排序标准,以便浆果出现在一起。
示例 7-4. 按单词的反向拼写对单词列表进行排序
>>> def reverse(word):
... return word[::-1]
>>> reverse('testing')
'gnitset'
>>> sorted(fruits, key=reverse)
['banana', 'apple', 'fig', 'raspberry', 'strawberry', 'cherry']
>>>
在函数式编程范式中,一些最著名的高阶函数包括map、filter、reduce和apply。apply函数在 Python 2.3 中已被弃用,并在 Python 3 中移除,因为它不再必要。如果需要使用动态参数集调用函数,可以编写fn(*args, **kwargs),而不是apply(fn, args, kwargs)。
map、filter和reduce高阶函数仍然存在,但对于它们的大多数用例,都有更好的替代方案,如下一节所示。
map、filter 和 reduce 的现代替代品
函数式语言通常提供map、filter和reduce高阶函数(有时使用不同的名称)。map和filter函数在 Python 3 中仍然是内置函数,但自列表推导式和生成器表达式引入以来,它们变得不再那么重要。列表推导式或生成器表达式可以完成map和filter的工作,但更易读。考虑示例 7-5。
示例 7-5. 使用map和filter生成的阶乘列表与编码为列表推导式的替代方案进行比较
>>> list(map(factorial, range(6))) # ①
[1, 1, 2, 6, 24, 120] >>> [factorial(n) for n in range(6)] # ②
[1, 1, 2, 6, 24, 120] >>> list(map(factorial, filter(lambda n: n % 2, range(6)))) # ③
[1, 6, 120] >>> [factorial(n) for n in range(6) if n % 2] # ④
[1, 6, 120] >>>
①
从 0!到 5!构建一个阶乘列表。
②
使用列表推导式进行相同的操作。
③
列出了奇数阶乘数的列表,直到 5!,同时使用map和filter。
④
列表推导式可以完成相同的工作,取代map和filter,使得lambda变得不再必要。
在 Python 3 中,map和filter返回生成器——一种迭代器形式,因此它们的直接替代品现在是生成器表达式(在 Python 2 中,这些函数返回列表,因此它们最接近的替代品是列表推导式)。
reduce函数从 Python 2 中的内置函数降级为 Python 3 中的functools模块。它最常见的用例,求和,更适合使用自 2003 年发布 Python 2.3 以来可用的sum内置函数。这在可读性和性能方面是一个巨大的胜利(参见示例 7-6)。
示例 7-6. 使用 reduce 和 sum 对整数求和,直到 99
>>> from functools import reduce # ①
>>> from operator import add # ②
>>> reduce(add, range(100)) # ③
4950 >>> sum(range(100)) # ④
4950 >>>
①
从 Python 3.0 开始,reduce 不再是内置函数。
②
导入 add 来避免创建一个仅用于添加两个数字的函数。
③
对整数求和,直到 99。
④
使用 sum 完成相同的任务—无需导入和调用 reduce 和 add。
注意
sum 和 reduce 的共同思想是对系列中的连续项目应用某种操作,累积先前的结果,从而将一系列值减少为单个值。
其他减少内置函数是 all 和 any:
all(iterable)
如果可迭代对象中没有假值元素,则返回 True;all([]) 返回 True。
any(iterable)
如果可迭代对象中有任何元素为真,则返回 True;any([]) 返回 False。
我在 “向量取 #4:哈希和更快的 ==” 中对 reduce 进行了更详细的解释,在那里,一个持续的示例为使用这个函数提供了有意义的上下文。在本书后面的部分,当重点放在可迭代对象上时,将总结减少函数,见 “可迭代对象减少函数”。
为了使用高阶函数,有时创建一个小的、一次性的函数是很方便的。这就是匿名函数存在的原因。我们将在下面介绍它们。
匿名函数
lambda 关键字在 Python 表达式中创建一个匿名函数。
然而,Python 的简单语法限制了 lambda 函数的主体必须是纯表达式。换句话说,主体不能包含其他 Python 语句,如 while、try 等。赋值语句 = 也是一个语句,因此不能出现在 lambda 中。可以使用新的赋值表达式语法 :=,但如果你需要它,你的 lambda 可能太复杂和难以阅读,应该重构为使用 def 的常规函数。
匿名函数的最佳用法是在作为高阶函数的参数列表的上下文中。例如,示例 7-7 是从 示例 7-4 重写的韵脚索引示例,使用 lambda,而不定义一个 reverse 函数。
示例 7-7. 使用 lambda 按照它们的反向拼写对单词列表进行排序
>>> fruits = ['strawberry', 'fig', 'apple', 'cherry', 'raspberry', 'banana']
>>> sorted(fruits, key=lambda word: word[::-1])
['banana', 'apple', 'fig', 'raspberry', 'strawberry', 'cherry']
>>>
在高阶函数的参数的有限上下文之外,匿名函数在 Python 中很少有用。语法限制往往使得非平凡的 lambda 要么难以阅读,要么无法工作。如果一个 lambda 难以阅读,我强烈建议您遵循 Fredrik Lundh 的重构建议。
lambda 语法只是一种语法糖:lambda 表达式创建一个函数对象,就像 def 语句一样。这只是 Python 中几种可调用对象中的一种。下一节将回顾所有这些对象。
可调用对象的九种类型
调用运算符 () 可以应用于除函数以外的其他对象。要确定对象是否可调用,请使用内置函数 callable()。截至 Python 3.9,数据模型文档 列出了九种可调用类型:
用户定义的函数
使用 def 语句或 lambda 表达式创建。
内置函数
在 C 中实现的函数(对于 CPython),如 len 或 time.strftime。
内置方法
在 C 中实现的方法,比如 dict.get。
方法
在类的主体中定义的函数。
类
当调用一个类时,它运行其 __new__ 方法来创建一个实例,然后运行 __init__ 来初始化它,最后将实例返回给调用者。因为 Python 中没有 new 运算符,调用一个类就像调用一个函数一样。²
类实例
如果一个类定义了 __call__ 方法,那么它的实例可以被调用为函数—这是下一节的主题。
生成器函数
在其主体中使用yield关键字的函数或方法。调用时,它们返回一个生成器对象。
本机协程函数
使用async def定义的函数或方法。调用时,它们返回一个协程对象。在 Python 3.5 中添加。
异步生成器函数
使用async def定义的函数或方法,在其主体中有yield。调用时,它们返回一个用于与async for一起使用的异步生成器。在 Python 3.6 中添加。
生成器、本机协程和异步生成器函数与其他可调用对象不同,它们的返回值永远不是应用程序数据,而是需要进一步处理以产生应用程序数据或执行有用工作的对象。生成器函数返回迭代器。这两者在第十七章中有所涉及。本机协程函数和异步生成器函数返回的对象只能在异步编程框架(如asyncio)的帮助下使用。它们是第二十一章的主题。
提示
鉴于 Python 中存在各种可调用类型,确定对象是否可调用的最安全方法是使用callable()内置函数:
>>> abs, str, 'Ni!'
(<built-in function abs>, <class 'str'>, 'Ni!')
>>> [callable(obj) for obj in (abs, str, 'Ni!')]
[True, True, False]
我们现在开始构建作为可调用对象的类实例。
用户定义的可调用类型
Python 函数不仅是真实对象,而且任意 Python 对象也可以被制作成类似函数的行为。实现__call__实例方法就是全部所需。
示例 7-8 实现了一个BingoCage类。可以从任何可迭代对象构建一个实例,并且以随机顺序存储内部项目的list。调用实例会弹出一个项目。³
示例 7-8. bingocall.py:BingoCage只做一件事:从一个打乱顺序的列表中挑选项目
import random
class BingoCage:
def __init__(self, items):
self._items = list(items) # ①
random.shuffle(self._items) # ②
def pick(self): # ③
try:
return self._items.pop()
except IndexError:
raise LookupError('pick from empty BingoCage') # ④
def __call__(self): # ⑤
return self.pick()
①
__init__接受任何可迭代对象;构建本地副本可防止对作为参数传递的任何list产生意外副作用。
②
shuffle能够正常工作,因为self._items是一个list。
③
主要方法。
④
如果self._items为空,则使用自定义消息引发异常。
⑤
bingo.pick()的快捷方式:bingo()。
这里是示例 7-8 的简单演示。请注意bingo实例如何被调用为函数,并且callable()内置函数将其识别为可调用对象:
>>> bingo = BingoCage(range(3))
>>> bingo.pick()
1
>>> bingo()
0
>>> callable(bingo)
True
实现__call__的类是创建类似函数的对象的简单方法,这些对象具有必须在调用之间保持的一些内部状态,例如BingoCage中剩余项目的情况。__call__的另一个很好的用例是实现装饰器。装饰器必须是可调用的,有时方便在装饰器的调用之间“记住”一些东西(例如,用于记忆化的缓存昂贵计算的结果以供以后使用)或将复杂实现拆分为单独的方法。
使用闭包是创建具有内部状态的函数的功能方法。闭包以及装饰器是第九章的主题。
现在让我们探索 Python 提供的强大语法,用于声明函数参数并将参数传递给它们。
从位置参数到仅关键字参数
Python 函数最好的特性之一是极其灵活的参数处理机制。与之密切相关的是在调用函数时使用*和**将可迭代对象和映射解包为单独的参数。要查看这些功能的实际应用,请参见示例 7-9 的代码以及在示例 7-10 中展示其用法的测试。
示例 7-9。tag生成 HTML 元素;一个关键字参数class_用于传递class属性,因为class是 Python 中的关键字
def tag(name, *content, class_=None, **attrs):
"""Generate one or more HTML tags"""
if class_ is not None:
attrs['class'] = class_
attr_pairs = (f' {attr}="{value}"' for attr, value
in sorted(attrs.items()))
attr_str = ''.join(attr_pairs)
if content:
elements = (f'<{name}{attr_str}>{c}</{name}>'
for c in content)
return '\n'.join(elements)
else:
return f'<{name}{attr_str} />'
tag函数可以以许多方式调用,就像示例 7-10 所示。
示例 7-10。从示例 7-9 调用tag函数的许多方法
>>> tag('br') # ①
'<br />'
>>> tag('p', 'hello') # ②
'<p>hello</p>'
>>> print(tag('p', 'hello', 'world'))
<p>hello</p>
<p>world</p>
>>> tag('p', 'hello', id=33) # ③
'<p id="33">hello</p>'
>>> print(tag('p', 'hello', 'world', class_='sidebar')) # ④
<p class="sidebar">hello</p>
<p class="sidebar">world</p>
>>> tag(content='testing', name="img") # ⑤
'<img content="testing" />'
>>> my_tag = {'name': 'img', 'title': 'Sunset Boulevard',
... 'src': 'sunset.jpg', 'class': 'framed'}
>>> tag(**my_tag) # ⑥
'<img class="framed" src="sunset.jpg" title="Sunset Boulevard" />'
①
单个位置参数会生成一个具有该名称的空tag。
②
第一个参数之后的任意数量的参数将被*content捕获为一个tuple。
③
在tag签名中未明确命名的关键字参数将被**attrs捕获为一个dict。
④
class_参数只能作为关键字参数传递。
⑤
第一个位置参数也可以作为关键字传递。
⑥
使用**前缀my_tag dict将其所有项作为单独的参数传递,然后绑定到命名参数,其余参数由**attrs捕获。在这种情况下,我们可以在参数dict中有一个'class'键,因为它是一个字符串,不会与 Python 中的class保留字冲突。
关键字参数是 Python 3 的一个特性。在示例 7-9 中,class_参数只能作为关键字参数给出,永远不会捕获未命名的位置参数。要在定义函数时指定关键字参数,请在参数前加上*命名它们。如果您不想支持可变位置参数但仍想要关键字参数,请在签名中放置一个单独的*,就像这样:
>>> def f(a, *, b):
... return a, b
...
>>> f(1, b=2)
(1, 2)
>>> f(1, 2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() takes 1 positional argument but 2 were given
请注意,关键字参数不需要具有默认值:它们可以是强制性的,就像前面示例中的b一样。
仅限位置参数
自 Python 3.8 以来,用户定义的函数签名可以指定位置参数。这个特性在内置函数中一直存在,比如divmod(a, b),它只能使用位置参数调用,而不能像divmod(a=10, b=4)那样调用。
要定义一个需要位置参数的函数,请在参数列表中使用/。
这个来自“Python 3.8 有什么新特性”的示例展示了如何模拟divmod内置函数:
def divmod(a, b, /):
return (a // b, a % b)
/左侧的所有参数都是仅限位置的。在/之后,您可以指定其他参数,它们的工作方式与通常一样。
警告
参数列表中的/在 Python 3.7 或更早版本中是语法错误。
例如,考虑来自示例 7-9 的tag函数。如果我们希望name参数是仅限位置的,我们可以在函数签名中的它后面添加/,就像这样:
def tag(name, /, *content, class_=None, **attrs):
...
您可以在“Python 3.8 有什么新特性”和PEP 570中找到其他仅限位置参数的示例。
在深入研究 Python 灵活的参数声明功能后,本章的其余部分将介绍标准库中用于以函数式风格编程的最有用的包。
函数式编程包
尽管 Guido 明确表示他并没有设计 Python 成为一个函数式编程语言,但由于头等函数、模式匹配以及像operator和functools这样的包的支持,函数式编码风格可以被很好地使用,我们将在接下来的两节中介绍它们。
运算符模块
在函数式编程中,使用算术运算符作为函数很方便。例如,假设您想要乘以一系列数字以计算阶乘而不使用递归。要执行求和,您可以使用 sum,但没有相应的乘法函数。您可以使用 reduce——正如我们在 “map、filter 和 reduce 的现代替代品” 中看到的那样——但这需要一个函数来将序列的两个项相乘。示例 7-11 展示了如何使用 lambda 解决这个问题。
示例 7-11. 使用 reduce 和匿名函数实现阶乘
from functools import reduce
def factorial(n):
return reduce(lambda a, b: a*b, range(1, n+1))
operator 模块提供了几十个运算符的函数等效版本,因此您不必编写像 lambda a, b: a*b 这样的琐碎函数。有了它,我们可以将 示例 7-11 重写为 示例 7-12。
示例 7-12. 使用 reduce 和 operator.mul 实现阶乘
from functools import reduce
from operator import mul
def factorial(n):
return reduce(mul, range(1, n+1))
operator 替换的另一组单一用途的 lambda 是用于从序列中选择项或从对象中读取属性的函数:itemgetter 和 attrgetter 是构建自定义函数的工厂来执行这些操作。
示例 7-13 展示了 itemgetter 的一个常见用法:按一个字段的值对元组列表进行排序。在示例中,城市按国家代码(字段 1)排序打印。本质上,itemgetter(1) 创建一个函数,给定一个集合,返回索引 1 处的项。这比编写和阅读 lambda fields: fields[1] 更容易,后者执行相同的操作。
示例 7-13. 使用 itemgetter 对元组列表进行排序(数据来自 示例 2-8)
>>> metro_data = [
... ('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
... ('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
... ('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
... ('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
... ('São Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
... ]
>>>
>>> from operator import itemgetter
>>> for city in sorted(metro_data, key=itemgetter(1)):
... print(city)
...
('São Paulo', 'BR', 19.649, (-23.547778, -46.635833))
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889))
('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
('Mexico City', 'MX', 20.142, (19.433333, -99.133333))
('New York-Newark', 'US', 20.104, (40.808611, -74.020386))
如果将多个索引参数传递给 itemgetter,则它构建的函数将返回提取的值的元组,这对于按多个键排序很有用:
>>> cc_name = itemgetter(1, 0)
>>> for city in metro_data:
... print(cc_name(city))
...
('JP', 'Tokyo')
('IN', 'Delhi NCR')
('MX', 'Mexico City')
('US', 'New York-Newark')
('BR', 'São Paulo')
>>>
因为 itemgetter 使用 [] 运算符,它不仅支持序列,还支持映射和任何实现 __getitem__ 的类。
itemgetter 的姐妹是 attrgetter,它通过名称创建提取对象属性的函数。如果将多个属性名称作为参数传递给 attrgetter,它还会返回一个值元组。此外,如果任何参数名称包含 .(点),attrgetter 将浏览嵌套对象以检索属性。这些行为在 示例 7-14 中展示。这不是最短的控制台会话,因为我们需要构建一个嵌套结构来展示 attrgetter 处理带点属性的方式。
示例 7-14. 使用 attrgetter 处理先前定义的 namedtuple 列表 metro_data(与 示例 7-13 中出现的相同列表)
>>> from collections import namedtuple
>>> LatLon = namedtuple('LatLon', 'lat lon') # ①
>>> Metropolis = namedtuple('Metropolis', 'name cc pop coord') # ②
>>> metro_areas = Metropolis(name, cc, pop, LatLon(lat, lon)) ![3
... for name, cc, pop, (lat, lon) in metro_data]
>>> metro_areas[0]
Metropolis(name='Tokyo', cc='JP', pop=36.933, coord=LatLon(lat=35.689722, lon=139.691667)) >>> metro_areas[0].coord.lat # ④
35.689722 >>> from operator import attrgetter
>>> name_lat = attrgetter('name', 'coord.lat') # ⑤
>>> >>> for city in sorted(metro_areas, key=attrgetter('coord.lat')): # ⑥
... print(name_lat(city)) # ⑦
...
('São Paulo', -23.547778) ('Mexico City', 19.433333) ('Delhi NCR', 28.613889) ('Tokyo', 35.689722) ('New York-Newark', 40.808611)
①
使用 namedtuple 定义 LatLon。
②
还要定义 Metropolis。
③
使用 Metropolis 实例构建 metro_areas 列表;注意嵌套元组解包以提取 (lat, lon) 并将其用于构建 Metropolis 的 coord 属性的 LatLon。
④
访问元素 metro_areas[0] 以获取其纬度。
⑤
定义一个 attrgetter 来检索 name 和 coord.lat 嵌套属性。
⑥
再次使用 attrgetter 按纬度对城市列表进行排序。
⑦
使用 ⑤ 中定义的 attrgetter 仅显示城市名称和纬度。
这是在 operator 中定义的函数的部分列表(以 _ 开头的名称被省略,因为它们主要是实现细节):
>>> [name for name in dir(operator) if not name.startswith('_')]
['abs', 'add', 'and_', 'attrgetter', 'concat', 'contains',
'countOf', 'delitem', 'eq', 'floordiv', 'ge', 'getitem', 'gt',
'iadd', 'iand', 'iconcat', 'ifloordiv', 'ilshift', 'imatmul',
'imod', 'imul', 'index', 'indexOf', 'inv', 'invert', 'ior',
'ipow', 'irshift', 'is_', 'is_not', 'isub', 'itemgetter',
'itruediv', 'ixor', 'le', 'length_hint', 'lshift', 'lt', 'matmul',
'methodcaller', 'mod', 'mul', 'ne', 'neg', 'not_', 'or_', 'pos',
'pow', 'rshift', 'setitem', 'sub', 'truediv', 'truth', 'xor']
列出的 54 个名称中大多数都是不言自明的。以i为前缀的名称组和另一个运算符的名称,例如iadd、iand等,对应于增强赋值运算符,例如+=、&=等。如果第一个参数是可变的,这些会在原地更改第一个参数;如果不是,该函数的工作方式类似于没有i前缀的函数:它只是返回操作的结果。
在剩余的operator函数中,methodcaller是我们将要介绍的最后一个。它在某种程度上类似于attrgetter和itemgetter,因为它会即时创建一个函数。它创建的函数会按名称在给定的对象上调用一个方法,就像示例 7-15 中所示的那样。
示例 7-15。methodcaller的演示:第二个测试显示了额外参数的绑定
>>> from operator import methodcaller
>>> s = 'The time has come'
>>> upcase = methodcaller('upper')
>>> upcase(s)
'THE TIME HAS COME'
>>> hyphenate = methodcaller('replace', ' ', '-')
>>> hyphenate(s)
'The-time-has-come'
示例 7-15 中的第一个测试只是为了展示methodcaller的工作原理,但如果您需要将str.upper作为一个函数使用,您可以直接在str类上调用它,并传递一个字符串作为参数,就像这样:
>>> str.upper(s)
'THE TIME HAS COME'
示例 7-15 中的第二个测试表明,methodcaller也可以进行部分应用,冻结一些参数,就像functools.partial函数一样。这是我们下一个主题。Bold Textopmod07
使用functools.partial冻结参数
functools模块提供了几个高阶函数。我们在“map、filter 和 reduce 的现代替代品”中看到了reduce。另一个是partial:给定一个可调用对象,它会生成一个新的可调用对象,其中原始可调用对象的一些参数绑定为预定值。这对于将接受一个或多个参数的函数适应需要较少参数的回调函数的 API 很有用。示例 7-16 是一个微不足道的演示。
示例 7-16。使用partial在需要一个参数可调用对象的地方使用两个参数函数
>>> from operator import mul
>>> from functools import partial
>>> triple = partial(mul, 3) # ①
>>> triple(7) # ②
21 >>> list(map(triple, range(1, 10))) # ③
[3, 6, 9, 12, 15, 18, 21, 24, 27]
①
从mul创建新的triple函数,将第一个位置参数绑定为3。
②
测试它。
③
使用triple与map;在这个例子中,mul无法与map一起使用。
一个更有用的示例涉及到我们在“为可靠比较标准化 Unicode”中看到的unicode.normalize函数。如果您使用来自许多语言的文本,您可能希望在比较或存储之前对任何字符串s应用unicode.normalize('NFC', s)。如果您经常这样做,最好有一个nfc函数来执行,就像示例 7-17 中那样。
示例 7-17。使用partial构建一个方便的 Unicode 标准化函数
>>> import unicodedata, functools
>>> nfc = functools.partial(unicodedata.normalize, 'NFC')
>>> s1 = 'café'
>>> s2 = 'cafe\u0301'
>>> s1, s2
('café', 'café')
>>> s1 == s2
False
>>> nfc(s1) == nfc(s2)
True
partial以可调用对象作为第一个参数,后跟要绑定的任意数量的位置参数和关键字参数。
示例 7-18 展示了partial与示例 7-9 中的tag函数一起使用,冻结一个位置参数和一个关键字参数。
示例 7-18。演示partial应用于示例 7-9 中的tag函数
>>> from tagger import tag
>>> tag
<function tag at 0x10206d1e0> # ①
>>> from functools import partial
>>> picture = partial(tag, 'img', class_='pic-frame') # ②
>>> picture(src='wumpus.jpeg')
'<img class="pic-frame" src="wumpus.jpeg" />' # ③
>>> picture
functools.partial(<function tag at 0x10206d1e0>, 'img', class_='pic-frame') # ④
>>> picture.func # ⑤
<function tag at 0x10206d1e0> >>> picture.args
('img',) >>> picture.keywords
{'class_': 'pic-frame'}
①
从示例 7-9 导入tag并显示其 ID。
②
通过使用tag从tag创建picture函数,通过使用'img'固定第一个位置参数和'pic-frame'关键字参数。
③
picture按预期工作。
④
partial()返回一个functools.partial对象。⁴
⑤
一个functools.partial对象具有提供对原始函数和固定参数的访问的属性。
functools.partialmethod 函数与 partial 执行相同的工作,但设计用于与方法一起使用。
functools 模块还包括设计用作函数装饰器的高阶函数,例如 cache 和 singledispatch 等。这些函数在第九章中有介绍,该章还解释了如何实现自定义装饰器。
章节总结
本章的目标是探索 Python 中函数的头等性质。主要思想是你可以将函数分配给变量,将它们传递给其他函数,将它们存储在数据结构中,并访问函数属性,从而使框架和工具能够根据这些信息进行操作。
高阶函数,作为函数式编程的基本要素,在 Python 中很常见。sorted、min 和 max 内置函数,以及 functools.partial 都是该语言中常用的高阶函数的例子。使用 map、filter 和 reduce 不再像以前那样常见,这要归功于列表推导式(以及类似的生成器表达式)以及新增的归约内置函数如 sum、all 和 any。
自 Python 3.6 起,可调用对象有九种不同的类型,从使用 lambda 创建的简单函数到实现 __call__ 的类实例。生成器和协程也是可调用的,尽管它们的行为与其他可调用对象非常不同。所有可调用对象都可以通过内置函数 callable() 进行检测。可调用对象提供了丰富的语法来声明形式参数,包括仅限关键字参数、仅限位置参数和注释。
最后,我们介绍了 operator 模块和 functools.partial 中的一些函数,通过最小化对功能受限的 lambda 语法的需求,促进了函数式编程。
进一步阅读
接下来的章节将继续探讨使用函数对象进行编程。第八章专注于函数参数和返回值中的类型提示。第九章深入探讨了函数装饰器——一种特殊的高阶函数,以及使其工作的闭包机制。第十章展示了头等函数如何简化一些经典的面向对象设计模式。
在Python 语言参考中,“3.2. 标准类型层次结构”介绍了九种可调用类型,以及所有其他内置类型。
Python Cookbook 第 3 版(O’Reilly)的第七章,由 David Beazley 和 Brian K. Jones 撰写,是对当前章节以及本书的第九章的极好补充,主要涵盖了相同概念但采用不同方法。
如果你对关键字参数的原理和用例感兴趣,请参阅PEP 3102—关键字参数。
了解 Python 中函数式编程的绝佳入门是 A. M. Kuchling 的“Python 函数式编程 HOWTO”。然而,该文本的主要焦点是迭代器和生成器的使用,这是第十七章的主题。
StackOverflow 上的问题“Python: 为什么 functools.partial 是必要的?”有一篇由经典著作Python in a Nutshell(O’Reilly)的合著者 Alex Martelli 所撰写的高度信息化(且有趣)的回答。
思考问题“Python 是一种函数式语言吗?”,我创作了我最喜欢的演讲之一,“超越范式”,我在 PyCaribbean、PyBay 和 PyConDE 上做过演讲。请查看我在柏林演讲中遇到本书两位技术审阅者 Miroslav Šedivý 和 Jürgen Gmach 的幻灯片和视频。
¹ 来自 Guido 的Python 的起源博客的“Python‘函数式’特性的起源”。
² 调用一个类通常会创建该类的一个实例,但通过重写__new__可以实现其他行为。我们将在“使用 new 实现灵活的对象创建”中看到一个例子。
³ 既然我们已经有了random.choice,为什么要构建一个BingoCage?choice函数可能多次返回相同的项,因为选定的项未从给定的集合中移除。调用BingoCage永远不会返回重复的结果——只要实例填充了唯一的值。
⁴ functools.py的源代码显示,functools.partial是用 C 实现的,并且默认情况下使用。 如果不可用,自 Python 3.4 起提供了partial的纯 Python 实现。
⁵ 在将代码粘贴到网络论坛时,还存在缩进丢失的问题,但我岔开了话题。
第八章:函数中的类型提示
还应强调Python 将保持动态类型语言,并且作者从未希望通过约定使类型提示成为强制要求。
Guido van Rossum,Jukka Lehtosalo 和Łukasz Langa,PEP 484—类型提示¹
类型提示是自 2001 年发布的 Python 2.2 中的类型和类的统一以来 Python 历史上最大的变化。然而,并非所有 Python 用户都同等受益于类型提示。这就是为什么它们应该始终是可选的。
PEP 484—类型提示引入了函数参数、返回值和变量的显式类型声明的语法和语义。其目标是通过静态分析帮助开发人员工具在不实际运行代码测试的情况下发现 Python 代码库中的错误。
主要受益者是使用 IDE(集成开发环境)和 CI(持续集成)的专业软件工程师。使类型提示对该群体具有吸引力的成本效益分析并不适用于所有 Python 用户。
Python 的用户群比这个宽广得多。它包括科学家、交易员、记者、艺术家、制造商、分析师和许多领域的学生等。对于他们中的大多数人来说,学习类型提示的成本可能更高——除非他们已经了解具有静态类型、子类型和泛型的语言。对于许多这些用户来说,由于他们与 Python 的交互方式以及他们的代码库和团队的规模较小——通常是“一个人的团队”,因此收益会较低。Python 的默认动态类型在编写用于探索数据和想法的代码时更简单、更具表现力,比如数据科学、创意计算和学习,
本章重点介绍 Python 函数签名中的类型提示。第十五章探讨了类的上下文中的类型提示,以及其他typing模块功能。
本章的主要主题包括:
-
一个关于使用 Mypy 逐渐类型化的实践介绍
-
鸭子类型和名义类型的互补视角
-
注解中可能出现的主要类型类别概述——这大约占了本章的 60%
-
类型提示可变参数(
*args,**kwargs) -
类型提示和静态类型化的限制和缺点
本章的新内容
本章是全新的。类型提示出现在我完成第一版流畅的 Python之后的 Python 3.5 中。
鉴于静态类型系统的局限性,PEP 484 的最佳想法是引入逐渐类型系统。让我们从定义这个概念开始。
关于逐渐类型化
PEP 484 向 Python 引入了逐渐类型系统。其他具有逐渐类型系统的语言包括微软的 TypeScript、Dart(由 Google 创建的 Flutter SDK 的语言)和 Hack(Facebook 的 HHVM 虚拟机支持的 PHP 方言)。Mypy 类型检查器本身起初是一种语言:一种逐渐类型化的 Python 方言,带有自己的解释器。Guido van Rossum 说服了 Mypy 的创造者 Jukka Lehtosalo,使其成为检查带注释的 Python 代码的工具。
逐渐类型系统:
是可选的
默认情况下,类型检查器不应对没有类型提示的代码发出警告。相反,当无法确定对象类型时,类型检查器会假定Any类型。Any类型被认为与所有其他类型兼容。
不会在运行时捕获类型错误
静态类型检查器、linter 和 IDE 使用类型提示来发出警告。它们不能阻止在运行时将不一致的值传递给函数或分配给变量。
不会增强性能
类型注释提供的数据理论上可以允许在生成的字节码中进行优化,但截至 2021 年 7 月,我所知道的任何 Python 运行时都没有实现这样的优化。²
逐步类型化最好的可用性特性是注释始终是可选的。
使用静态类型系统,大多数类型约束很容易表达,许多很繁琐,一些很困难,而一些则是不可能的。³ 你很可能会写出一段优秀的 Python 代码,具有良好的测试覆盖率和通过的测试,但仍然无法添加满足类型检查器的类型提示。没关系;只需省略有问题的类型提示并发布!
类型提示在所有级别都是可选的:你可以有完全没有类型提示的整个包,当你将其中一个这样的包导入到使用类型提示的模块时,你可以让类型检查器保持沉默,并且你可以添加特殊注释来让类型检查器忽略代码中特定的行。
提示
寻求 100% 的类型提示覆盖可能会刺激没有经过适当思考的类型提示,只是为了满足指标。这也会阻止团队充分利用 Python 的强大和灵活性。当注释会使 API 不够用户友好,或者不必要地复杂化其实现时,应该自然地接受没有类型提示的代码。
实践中的逐步类型化
让我们看看逐步类型化在实践中是如何工作的,从一个简单的函数开始,逐渐添加类型提示,由 Mypy 指导。
注意
有几个与 PEP 484 兼容的 Python 类型检查器,包括 Google 的 pytype、Microsoft 的 Pyright、Facebook 的 Pyre—以及嵌入在 IDE 中的类型检查器,如 PyCharm。我选择了 Mypy 作为示例,因为它是最知名的。然而,其他类型检查器可能更适合某些项目或团队。例如,Pytype 设计用于处理没有类型提示的代码库,并仍然提供有用的建议。它比 Mypy 更宽松,还可以为您的代码生成注释。
我们将为一个返回带有计数和单数或复数词的字符串的 show_count 函数添加注释:
>>> show_count(99, 'bird')
'99 birds'
>>> show_count(1, 'bird')
'1 bird'
>>> show_count(0, 'bird')
'no birds'
示例 8-1 展示了show_count的源代码,没有注释。
示例 8-1. messages.py 中没有类型提示的 show_count
def show_count(count, word):
if count == 1:
return f'1 {word}'
count_str = str(count) if count else 'no'
return f'{count_str} {word}s'
从 Mypy 开始
要开始类型检查,我在 messages.py 模块上运行 mypy 命令:
…/no_hints/ $ pip install mypy
[lots of messages omitted...]
…/no_hints/ $ mypy messages.py
Success: no issues found in 1 source file
使用默认设置的 Mypy 在 示例 8-1 中没有发现任何问题。
警告
我正在使用 Mypy 0.910,在我审阅这篇文章时是最新版本(2021 年 7 月)。Mypy 的 “介绍” 警告说它“正式是测试版软件。偶尔会有破坏向后兼容性的更改。” Mypy 给我至少一个与我在 2020 年 4 月写这一章时不同的报告。当你阅读这篇文章时,你可能会得到与这里显示的不同的结果。
如果函数签名没有注释,Mypy 默认会忽略它—除非另有配置。
对于 示例 8-2,我还有 pytest 单元测试。这是 messages_test.py 中的代码。
示例 8-2. messages_test.py 中没有类型提示
from pytest import mark
from messages import show_count
@mark.parametrize('qty, expected', [
(1, '1 part'),
(2, '2 parts'),
])
def test_show_count(qty, expected):
got = show_count(qty, 'part')
assert got == expected
def test_show_count_zero():
got = show_count(0, 'part')
assert got == 'no parts'
现在让我们根据 Mypy 添加类型提示。
使 Mypy 更严格
命令行选项 --disallow-untyped-defs 会使 Mypy 标记任何没有为所有参数和返回值添加类型提示的函数定义。
在测试文件上使用 --disallow-untyped-defs 会产生三个错误和一个注意:
…/no_hints/ $ mypy --disallow-untyped-defs messages_test.py
messages.py:14: error: Function is missing a type annotation
messages_test.py:10: error: Function is missing a type annotation
messages_test.py:15: error: Function is missing a return type annotation
messages_test.py:15: note: Use "-> None" if function does not return a value
Found 3 errors in 2 files (checked 1 source file)
对于逐步类型化的第一步,我更喜欢使用另一个选项:--disallow-incomplete-defs。最初,它对我毫无意义:
…/no_hints/ $ mypy --disallow-incomplete-defs messages_test.py
Success: no issues found in 1 source file
现在我可以只为 messages.py 中的 show_count 添加返回类型:
def show_count(count, word) -> str:
这已经足够让 Mypy 查看它。使用与之前相同的命令行检查 messages_test.py 将导致 Mypy 再次查看 messages.py:
…/no_hints/ $ mypy --disallow-incomplete-defs messages_test.py
messages.py:14: error: Function is missing a type annotation
for one or more arguments
Found 1 error in 1 file (checked 1 source file)
现在我可以逐步为每个函数添加类型提示,而不会收到关于我没有注释的函数的警告。这是一个完全注释的签名,满足了 Mypy:
def show_count(count: int, word: str) -> str:
提示
与其像--disallow-incomplete-defs这样输入命令行选项,你可以按照Mypy 配置文件文档中描述的方式保存你喜欢的选项。你可以有全局设置和每个模块的设置。以下是一个简单的mypy.ini示例:
[mypy]
python_version = 3.9
warn_unused_configs = True
disallow_incomplete_defs = True
默认参数值
示例 8-1 中的show_count函数只适用于常规名词。如果复数不能通过添加's'来拼写,我们应该让用户提供复数形式,就像这样:
>>> show_count(3, 'mouse', 'mice')
'3 mice'
让我们进行一点“类型驱动的开发”。首先我们添加一个使用第三个参数的测试。不要忘记为测试函数添加返回类型提示,否则 Mypy 将不会检查它。
def test_irregular() -> None:
got = show_count(2, 'child', 'children')
assert got == '2 children'
Mypy 检测到了错误:
…/hints_2/ $ mypy messages_test.py
messages_test.py:22: error: Too many arguments for "show_count"
Found 1 error in 1 file (checked 1 source file)
现在我编辑show_count,在示例 8-3 中添加了可选的plural参数。
示例 8-3. hints_2/messages.py中带有可选参数的showcount
def show_count(count: int, singular: str, plural: str = '') -> str:
if count == 1:
return f'1 {singular}'
count_str = str(count) if count else 'no'
if not plural:
plural = singular + 's'
return f'{count_str} {plural}'
现在 Mypy 报告“成功”。
警告
这里有一个 Python 无法捕捉的类型错误。你能发现吗?
def hex2rgb(color=str) -> tuple[int, int, int]:
Mypy 的错误报告并不是很有帮助:
colors.py:24: error: Function is missing a type
annotation for one or more arguments
color参数的类型提示应为color: str。我写成了color=str,这不是一个注释:它将color的默认值设置为str。
根据我的经验,这是一个常见的错误,很容易忽视,特别是在复杂的类型提示中。
以下细节被认为是类型提示的良好风格:
-
参数名和
:之间没有空格;:后有一个空格 -
在默认参数值之前的
=两侧留有空格
另一方面,PEP 8 表示如果对于特定参数没有类型提示,则=周围不应有空格。
使用None作为默认值
在示例 8-3 中,参数plural被注释为str,默认值为'',因此没有类型冲突。
我喜欢那个解决方案,但在其他情况下,None是更好的默认值。如果可选参数期望一个可变类型,那么None是唯一明智的默认值——正如我们在“可变类型作为参数默认值:不好的主意”中看到的。
要将None作为plural参数的默认值,签名将如下所示:
from typing import Optional
def show_count(count: int, singular: str, plural: Optional[str] = None) -> str:
让我们解开这个问题:
-
Optional[str]表示plural可以是str或None。 -
你必须明确提供默认值
= None。
如果你没有为plural分配默认值,Python 运行时将把它视为必需参数。记住:在运行时,类型提示会被忽略。
请注意,我们需要从typing模块导入Optional。在导入类型时,使用语法from typing import X是一个好习惯,可以缩短函数签名的长度。
警告
Optional不是一个很好的名称,因为该注释并不使参数变为可选的。使其可选的是为参数分配默认值。Optional[str]只是表示:该参数的类型可以是str或NoneType。在 Haskell 和 Elm 语言中,类似的类型被命名为Maybe。
现在我们已经初步了解了渐进类型,让我们考虑在实践中“类型”这个概念意味着什么。
类型由支持的操作定义
文献中对类型概念有许多定义。在这里,我们假设类型是一组值和一组可以应用于这些值的函数。
PEP 483—类型提示的理论
在实践中,将支持的操作集合视为类型的定义特征更有用。⁴
例如,从适用操作的角度来看,在以下函数中x的有效类型是什么?
def double(x):
return x * 2
x参数类型可以是数值型(int、complex、Fraction、numpy.uint32等),但也可以是序列(str、tuple、list、array)、N 维numpy.array,或者任何实现或继承接受int参数的__mul__方法的其他类型。
然而,请考虑这个带注释的 double。现在请忽略缺失的返回类型,让我们专注于参数类型:
from collections import abc
def double(x: abc.Sequence):
return x * 2
类型检查器将拒绝该代码。如果告诉 Mypy x 的类型是 abc.Sequence,它将标记 x * 2 为错误,因为 Sequence ABC 没有实现或继承 __mul__ 方法。在运行时,该代码将与具体序列(如 str、tuple、list、array 等)以及数字一起工作,因为在运行时会忽略类型提示。但类型检查器只关心显式声明的内容,abc.Sequence 没有 __mul__。
这就是为什么这一节的标题是“类型由支持的操作定义”。Python 运行时接受任何对象作为 x 参数传递给 double 函数的两个版本。计算 x * 2 可能有效,也可能会引发 TypeError,如果 x 不支持该操作。相比之下,Mypy 在分析带注释的 double 源代码时会声明 x * 2 为错误,因为它对于声明的类型 x: abc.Sequence 是不支持的操作。
在渐进式类型系统中,我们有两种不同类型观点的相互作用:
鸭子类型
Smalltalk——开创性的面向对象语言——以及 Python、JavaScript 和 Ruby 采用的视角。对象具有类型,但变量(包括参数)是无类型的。实际上,对象的声明类型是什么并不重要,只有它实际支持的操作才重要。如果我可以调用 birdie.quack(),那么在这个上下文中 birdie 就是一只鸭子。根据定义,鸭子类型只在运行时强制执行,当尝试对对象进行操作时。这比名义类型更灵活,但会在运行时允许更多的错误。⁵
名义类型
C++、Java 和 C# 采用的视角,由带注释的 Python 支持。对象和变量具有类型。但对象只在运行时存在,类型检查器只关心在变量(包括参数)被注释为类型提示的源代码中。如果 Duck 是 Bird 的一个子类,你可以将一个 Duck 实例分配给一个被注释为 birdie: Bird 的参数。但在函数体内,类型检查器认为调用 birdie.quack() 是非法的,因为 birdie 名义上是一个 Bird,而该类不提供 .quack() 方法。在运行时实际参数是 Duck 也无关紧要,因为名义类型是静态强制的。类型检查器不运行程序的任何部分,它只读取源代码。这比鸭子类型更严格,优点是在构建流水线中更早地捕获一些错误,甚至在代码在 IDE 中输入时。
Example 8-4 是一个愚蠢的例子,对比了鸭子类型和名义类型,以及静态类型检查和运行时行为。⁶
示例 8-4. birds.py
class Bird:
pass
class Duck(Bird): # ①
def quack(self):
print('Quack!')
def alert(birdie): # ②
birdie.quack()
def alert_duck(birdie: Duck) -> None: # ③
birdie.quack()
def alert_bird(birdie: Bird) -> None: # ④
birdie.quack()
①
Duck 是 Bird 的一个子类。
②
alert 没有类型提示,因此类型检查器会忽略它。
③
alert_duck 接受一个 Duck 类型的参数。
④
alert_bird 接受一个 Bird 类型的参数。
使用 Mypy 对 birds.py 进行类型检查,我们发现了一个问题:
…/birds/ $ mypy birds.py
birds.py:16: error: "Bird" has no attribute "quack"
Found 1 error in 1 file (checked 1 source file)
通过分析源代码,Mypy 发现 alert_bird 是有问题的:类型提示声明了 birdie 参数的类型为 Bird,但函数体调用了 birdie.quack(),而 Bird 类没有这样的方法。
现在让我们尝试在 daffy.py 中使用 birds 模块,参见 Example 8-5。
示例 8-5. daffy.py
from birds import *
daffy = Duck()
alert(daffy) # ①
alert_duck(daffy) # ②
alert_bird(daffy) # ③
①
这是有效的调用,因为 alert 没有类型提示。
②
这是有效的调用,因为 alert_duck 接受一个 Duck 参数,而 daffy 是一个 Duck。
③
有效的调用,因为alert_bird接受一个Bird参数,而daffy也是一个Bird——Duck的超类。
在daffy.py上运行 Mypy 会引发与在birds.py中定义的alert_bird函数中的quack调用相同的错误:
…/birds/ $ mypy daffy.py
birds.py:16: error: "Bird" has no attribute "quack"
Found 1 error in 1 file (checked 1 source file)
但是 Mypy 对daffy.py本身没有任何问题:这三个函数调用都是正确的。
现在,如果你运行daffy.py,你会得到以下结果:
…/birds/ $ python3 daffy.py
Quack!
Quack!
Quack!
一切正常!鸭子类型万岁!
在运行时,Python 不关心声明的类型。它只使用鸭子类型。Mypy 在alert_bird中标记了一个错误,但在运行时使用daffy调用它是没有问题的。这可能会让许多 Python 爱好者感到惊讶:静态类型检查器有时会发现我们知道会执行的程序中的错误。
然而,如果几个月后你被要求扩展这个愚蠢的鸟类示例,你可能会感激 Mypy。考虑一下woody.py模块,它也使用了birds,在示例 8-6 中。
示例 8-6. woody.py
from birds import *
woody = Bird()
alert(woody)
alert_duck(woody)
alert_bird(woody)
Mypy 在检查woody.py时发现了两个错误:
…/birds/ $ mypy woody.py
birds.py:16: error: "Bird" has no attribute "quack"
woody.py:5: error: Argument 1 to "alert_duck" has incompatible type "Bird";
expected "Duck"
Found 2 errors in 2 files (checked 1 source file)
第一个错误在birds.py中:在alert_bird中的birdie.quack()调用,我们之前已经看过了。第二个错误在woody.py中:woody是Bird的一个实例,所以调用alert_duck(woody)是无效的,因为该函数需要一个Duck。每个Duck都是一个Bird,但并非每个Bird都是一个Duck。
在运行时,woody.py中的所有调用都失败了。这些失败的连续性在示例 8-7 中的控制台会话中最好地说明。
示例 8-7. 运行时错误以及 Mypy 如何帮助
>>> from birds import *
>>> woody = Bird()
>>> alert(woody) # ①
Traceback (most recent call last):
...
AttributeError: 'Bird' object has no attribute 'quack'
>>>
>>> alert_duck(woody) # ②
Traceback (most recent call last):
...
AttributeError: 'Bird' object has no attribute 'quack'
>>>
>>> alert_bird(woody) # ③
Traceback (most recent call last):
...
AttributeError: 'Bird' object has no attribute 'quack'
①
Mypy 无法检测到这个错误,因为alert中没有类型提示。
②
Mypy 报告了问题:“alert_duck"的第 1 个参数类型不兼容:“Bird”;预期是"Duck”。
③
自从示例 8-4 以来,Mypy 一直在告诉我们alert_bird函数的主体是错误的:“Bird"没有属性"quack”。
这个小实验表明,鸭子类型更容易上手,更加灵活,但允许不支持的操作在运行时引发错误。名义类型在运行前检测错误,但有时可能会拒绝实际运行的代码,比如在示例 8-5 中的调用alert_bird(daffy)。即使有时候能够运行,alert_bird函数的命名是错误的:它的主体确实需要支持.quack()方法的对象,而Bird没有这个方法。
在这个愚蠢的例子中,函数只有一行。但在实际代码中,它们可能会更长;它们可能会将birdie参数传递给更多函数,并且birdie参数的来源可能相距多个函数调用,这使得很难准确定位运行时错误的原因。类型检查器可以防止许多这样的错误在运行时发生。
注意
类型提示在适合放在书中的小例子中的价值是有争议的。随着代码库规模的增长,其好处也会增加。这就是为什么拥有数百万行 Python 代码的公司——如 Dropbox、Google 和 Facebook——投资于团队和工具,支持公司范围内采用类型提示,并在 CI 管道中检查其 Python 代码库的重要部分。
在本节中,我们探讨了鸭子类型和名义类型中类型和操作的关系,从简单的double()函数开始——我们没有为其添加适当的类型提示。当我们到达“静态协议”时,我们将看到如何为double()添加类型提示。但在那之前,还有更基本的类型需要了解。
可用于注释的类型
几乎任何 Python 类型都可以用作类型提示,但存在限制和建议。此外,typing模块引入了有时令人惊讶的语义的特殊构造。
本节涵盖了您可以在注释中使用的所有主要类型:
-
typing.Any -
简单类型和类
-
typing.Optional和typing.Union -
泛型集合,包括元组和映射
-
抽象基类
-
通用可迭代对象
-
参数化泛型和
TypeVar -
typing.Protocols—静态鸭子类型的关键 -
typing.Callable -
typing.NoReturn—一个结束这个列表的好方法
我们将依次介绍每一个,从一个奇怪的、显然无用但至关重要的类型开始。
任意类型
任何渐进式类型系统的基石是Any类型,也称为动态类型。当类型检查器看到这样一个未标记的函数时:
def double(x):
return x * 2
它假设这个:
def double(x: Any) -> Any:
return x * 2
这意味着x参数和返回值可以是任何类型,包括不同的类型。假定Any支持每种可能的操作。
将Any与object进行对比。考虑这个签名:
def double(x: object) -> object:
这个函数也接受每种类型的参数,因为每种类型都是object的子类型。
然而,类型检查器将拒绝这个函数:
def double(x: object) -> object:
return x * 2
问题在于object不支持__mul__操作。这就是 Mypy 报告的内容:
…/birds/ $ mypy double_object.py
double_object.py:2: error: Unsupported operand types for * ("object" and "int")
Found 1 error in 1 file (checked 1 source file)
更一般的类型具有更窄的接口,即它们支持更少的操作。object类实现的操作比abc.Sequence少,abc.Sequence实现的操作比abc.MutableSequence少,abc.MutableSequence实现的操作比list少。
但Any是一个神奇的类型,它同时位于类型层次结构的顶部和底部。它同时是最一般的类型—所以一个参数n: Any接受每种类型的值—和最专门的类型,支持每种可能的操作。至少,这就是类型检查器如何理解Any。
当然,没有任何类型可以支持每种可能的操作,因此使用Any可以防止类型检查器实现其核心任务:在程序因运行时异常而崩溃之前检测潜在的非法操作。
子类型与一致性
传统的面向对象的名义类型系统依赖于子类型关系。给定一个类T1和一个子类T2,那么T2是T1的子类型。
考虑这段代码:
class T1:
...
class T2(T1):
...
def f1(p: T1) -> None:
...
o2 = T2()
f1(o2) # OK
调用f1(o2)是对 Liskov 替换原则—LSP 的应用。Barbara Liskov⁷实际上是根据支持的操作定义是子类型:如果类型T2的对象替代类型T1的对象并且程序仍然正确运行,那么T2就是T1的子类型。
继续上述代码,这显示了 LSP 的违反:
def f2(p: T2) -> None:
...
o1 = T1()
f2(o1) # type error
从支持的操作的角度来看,这是完全合理的:作为一个子类,T2继承并且必须支持T1支持的所有操作。因此,T2的实例可以在期望T1的实例的任何地方使用。但反之不一定成立:T2可能实现额外的方法,因此T1的实例可能无法在期望T2的实例的任何地方使用。这种对支持的操作的关注体现在名称行为子类型化中,也用于指代 LSP。
在渐进式类型系统中,还有另一种关系:与一致,它适用于子类型适用的地方,对于类型Any有特殊规定。
与一致的规则是:
-
给定
T1和子类型T2,那么T2是与T1一致的(Liskov 替换)。 -
每种类型都与一致
Any:你可以将每种类型的对象传递给声明为Any类型的参数。 -
Any是与每种类型一致的:你总是可以在需要另一种类型的参数时传递一个Any类型的对象。
考虑前面定义的对象o1和o2,这里是有效代码的示例,说明规则#2 和#3:
def f3(p: Any) -> None:
...
o0 = object()
o1 = T1()
o2 = T2()
f3(o0) #
f3(o1) # all OK: rule #2
f3(o2) #
def f4(): # implicit return type: `Any`
...
o4 = f4() # inferred type: `Any`
f1(o4) #
f2(o4) # all OK: rule #3
f3(o4) #
每个渐进类型系统都需要像Any这样的通配类型。
提示
动词“推断”是“猜测”的花哨同义词,在类型分析的背景下使用。Python 和其他语言中的现代类型检查器并不要求在每个地方都有类型注释,因为它们可以推断出许多表达式的类型。例如,如果我写x = len(s) * 10,类型检查器不需要一个显式的本地声明来知道x是一个int,只要它能找到len内置函数的类型提示即可。
现在我们可以探索注解中使用的其余类型。
简单类型和类
像int、float、str和bytes这样的简单类型可以直接在类型提示中使用。标准库、外部包或用户定义的具体类——FrenchDeck、Vector2d和Duck——也可以在类型提示中使用。
抽象基类在类型提示中也很有用。当我们研究集合类型时,我们将回到它们,并在“抽象基类”中看到它们。
在类之间,一致的定义类似于子类型:子类与其所有超类一致。
然而,“实用性胜过纯粹性”,因此有一个重要的例外情况,我将在下面的提示中讨论。
int 与复杂一致
内置类型int、float和complex之间没有名义子类型关系:它们是object的直接子类。但 PEP 484声明 int与float一致,float与complex一致。在实践中是有道理的:int实现了float的所有操作,而且int还实现了额外的操作——位运算如&、|、<<等。最终结果是:int与complex一致。对于i = 3,i.real是3,i.imag是0。
可选和联合类型
我们在“使用 None 作为默认值”中看到了Optional特殊类型。它解决了将None作为默认值的问题,就像这个部分中的示例一样:
from typing import Optional
def show_count(count: int, singular: str, plural: Optional[str] = None) -> str:
构造Optional[str]实际上是Union[str, None]的快捷方式,这意味着plural的类型可以是str或None。
Python 3.10 中更好的可选和联合语法
自 Python 3.10 起,我们可以写str | bytes而不是Union[str, bytes]。这样打字更少,而且不需要从typing导入Optional或Union。对比show_count的plural参数的类型提示的旧语法和新语法:
plural: Optional[str] = None # before
plural: str | None = None # after
|运算符也适用于isinstance和issubclass来构建第二个参数:isinstance(x, int | str)。更多信息,请参阅PEP 604—Union[]的补充语法。
ord内置函数的签名是Union的一个简单示例——它接受str或bytes,并返回一个int:⁸
def ord(c: Union[str, bytes]) -> int: ...
这是一个接受str但可能返回str或float的函数示例:
from typing import Union
def parse_token(token: str) -> Union[str, float]:
try:
return float(token)
except ValueError:
return token
如果可能的话,尽量避免创建返回Union类型的函数,因为这会给用户增加额外的负担——迫使他们在运行时检查返回值的类型以知道如何处理它。但在前面代码中的parse_token是一个简单表达式求值器上下文中合理的用例。
提示
在“双模式 str 和 bytes API”中,我们看到接受str或bytes参数的函数,但如果参数是str则返回str,如果参数是bytes则返回bytes。在这些情况下,返回类型由输入类型确定,因此Union不是一个准确的解决方案。为了正确注释这样的函数,我们需要一个类型变量—在“参数化泛型和 TypeVar”中介绍—或重载,我们将在“重载签名”中看到。
Union[]需要至少两种类型。嵌套的Union类型与扁平化的Union具有相同的效果。因此,这种类型提示:
Union[A, B, Union[C, D, E]]
与以下相同:
Union[A, B, C, D, E]
Union 对于彼此不一致的类型更有用。例如:Union[int, float] 是多余的,因为 int 与 float 是一致的。如果只使用 float 来注释参数,它也将接受 int 值。
泛型集合
大多数 Python 集合是异构的。例如,你可以在 list 中放入任何不同类型的混合物。然而,在实践中,这并不是非常有用:如果将对象放入集合中,你可能希望以后对它们进行操作,通常这意味着它们必须至少共享一个公共方法。⁹
可以声明带有类型参数的泛型类型,以指定它们可以处理的项目的类型。
例如,一个 list 可以被参数化以限制其中元素的类型,就像你在 示例 8-8 中看到的那样。
示例 8-8. tokenize 中的 Python ≥ 3.9 类型提示
def tokenize(text: str) -> list[str]:
return text.upper().split()
在 Python ≥ 3.9 中,这意味着 tokenize 返回一个每个项目都是 str 类型的 list。
注释 stuff: list 和 stuff: list[Any] 意味着相同的事情:stuff 是任意类型对象的列表。
提示
如果你使用的是 Python 3.8 或更早版本,概念是相同的,但你需要更多的代码来使其工作,如可选框中所解释的 “遗留支持和已弃用的集合类型”。
PEP 585—标准集合中的泛型类型提示 列出了接受泛型类型提示的标准库集合。以下列表仅显示那些使用最简单形式的泛型类型提示 container[item] 的集合:
list collections.deque abc.Sequence abc.MutableSequence
set abc.Container abc.Set abc.MutableSet
frozenset abc.Collection
tuple 和映射类型支持更复杂的类型提示,我们将在各自的部分中看到。
截至 Python 3.10,目前还没有很好的方法来注释 array.array,考虑到 typecode 构造参数,该参数确定数组中存储的是整数还是浮点数。更难的问题是如何对整数范围进行类型检查,以防止在向数组添加元素时在运行时出现 OverflowError。例如,具有 typecode='B' 的 array 只能容纳从 0 到 255 的 int 值。目前,Python 的静态类型系统还无法应对这一挑战。
现在让我们看看如何注释泛型元组。
元组类型
有三种注释元组类型的方法:
-
元组作为记录
-
具有命名字段的元组作为记录
-
元组作为不可变序列
元组作为记录
如果将 tuple 用作记录,则使用内置的 tuple 并在 [] 中声明字段的类型。
例如,类型提示将是 tuple[str, float, str],以接受包含城市名称、人口和国家的元组:('上海', 24.28, '中国')。
考虑一个接受一对地理坐标并返回 Geohash 的函数,用法如下:
>>> shanghai = 31.2304, 121.4737
>>> geohash(shanghai)
'wtw3sjq6q'
示例 8-11 展示了如何定义 geohash,使用了来自 PyPI 的 geolib 包。
示例 8-11. coordinates.py 中的 geohash 函数
from geolib import geohash as gh # type: ignore # ①
PRECISION = 9
def geohash(lat_lon: tuple[float, float]) -> str: # ②
return gh.encode(*lat_lon, PRECISION)
①
此注释阻止 Mypy 报告 geolib 包没有类型提示。
②
lat_lon 参数注释为具有两个 float 字段的 tuple。
提示
对于 Python < 3.9,导入并在类型提示中使用 typing.Tuple。它已被弃用,但至少会保留在标准库中直到 2024 年。
具有命名字段的元组作为记录
要为具有许多字段的元组或代码中多处使用的特定类型的元组添加注释,我强烈建议使用 typing.NamedTuple,如 第五章 中所示。示例 8-12 展示了使用 NamedTuple 对 示例 8-11 进行变体的情况。
示例 8-12. coordinates_named.py 中的 NamedTuple Coordinates 和 geohash 函数
from typing import NamedTuple
from geolib import geohash as gh # type: ignore
PRECISION = 9
class Coordinate(NamedTuple):
lat: float
lon: float
def geohash(lat_lon: Coordinate) -> str:
return gh.encode(*lat_lon, PRECISION)
如“数据类构建器概述”中所解释的,typing.NamedTuple是tuple子类的工厂,因此Coordinate与tuple[float, float]是一致的,但反之则不成立——毕竟,Coordinate具有NamedTuple添加的额外方法,如._asdict(),还可以有用户定义的方法。
在实践中,这意味着将Coordinate实例传递给以下定义的display函数是类型安全的:
def display(lat_lon: tuple[float, float]) -> str:
lat, lon = lat_lon
ns = 'N' if lat >= 0 else 'S'
ew = 'E' if lon >= 0 else 'W'
return f'{abs(lat):0.1f}°{ns}, {abs(lon):0.1f}°{ew}'
元组作为不可变序列
要注释用作不可变列表的未指定长度元组,必须指定一个类型,后跟逗号和...(这是 Python 的省略号标记,由三个句点组成,而不是 Unicode U+2026—水平省略号)。
例如,tuple[int, ...]是一个具有int项的元组。
省略号表示接受任意数量的元素>= 1。无法指定任意长度元组的不同类型字段。
注释stuff: tuple[Any, ...]和stuff: tuple意思相同:stuff是一个未指定长度的包含任何类型对象的元组。
这里是一个columnize函数,它将一个序列转换为行和单元格的表格,形式为未指定长度的元组列表。这对于以列形式显示项目很有用,就像这样:
>>> animals = 'drake fawn heron ibex koala lynx tahr xerus yak zapus'.split()
>>> table = columnize(animals)
>>> table
[('drake', 'koala', 'yak'), ('fawn', 'lynx', 'zapus'), ('heron', 'tahr'),
('ibex', 'xerus')]
>>> for row in table:
... print(''.join(f'{word:10}' for word in row))
...
drake koala yak
fawn lynx zapus
heron tahr
ibex xerus
示例 8-13 展示了columnize的实现。注意返回类型:
list[tuple[str, ...]]
示例 8-13. columnize.py返回一个字符串元组列表
from collections.abc import Sequence
def columnize(
sequence: Sequence[str], num_columns: int = 0
) -> list[tuple[str, ...]]:
if num_columns == 0:
num_columns = round(len(sequence) ** 0.5)
num_rows, reminder = divmod(len(sequence), num_columns)
num_rows += bool(reminder)
return [tuple(sequence[i::num_rows]) for i in range(num_rows)]
通用映射
通用映射类型被注释为MappingType[KeyType, ValueType]。内置的dict和collections以及collections.abc中的映射类型在 Python ≥ 3.9 中接受该表示法。对于早期版本,必须使用typing.Dict和typing模块中的其他映射类型,如“遗留支持和已弃用的集合类型”中所述。
示例 8-14 展示了一个函数返回倒排索引以通过名称搜索 Unicode 字符的实际用途——这是示例 4-21 的一个变体,更适合我们将在第二十一章中学习的服务器端代码。
给定起始和结束的 Unicode 字符代码,name_index返回一个dict[str, set[str]],这是一个将每个单词映射到具有该单词在其名称中的字符集的倒排索引。例如,在对 ASCII 字符从 32 到 64 进行索引后,这里是映射到单词'SIGN'和'DIGIT'的字符集,以及如何找到名为'DIGIT EIGHT'的字符:
>>> index = name_index(32, 65)
>>> index['SIGN']
{'$', '>', '=', '+', '<', '%', '#'}
>>> index['DIGIT']
{'8', '5', '6', '2', '3', '0', '1', '4', '7', '9'}
>>> index['DIGIT'] & index['EIGHT']
{'8'}
示例 8-14 展示了带有name_index函数的charindex.py源代码。除了dict[]类型提示外,这个示例还有三个本书中首次出现的特性。
示例 8-14. charindex.py
import sys
import re
import unicodedata
from collections.abc import Iterator
RE_WORD = re.compile(r'\w+')
STOP_CODE = sys.maxunicode + 1
def tokenize(text: str) -> Iterator[str]: # ①
"""return iterable of uppercased words"""
for match in RE_WORD.finditer(text):
yield match.group().upper()
def name_index(start: int = 32, end: int = STOP_CODE) -> dict[str, set[str]]:
index: dict[str, set[str]] = {} # ②
for char in (chr(i) for i in range(start, end)):
if name := unicodedata.name(char, ''): # ③
for word in tokenize(name):
index.setdefault(word, set()).add(char)
return index
①
tokenize是一个生成器函数。第十七章是关于生成器的。
②
局部变量index已经被注释。没有提示,Mypy 会说:需要为'index'注释类型(提示:“index: dict[<type>, <type>] = ...”)。
③
我在if条件中使用了海象操作符:=。它将unicodedata.name()调用的结果赋给name,整个表达式的值就是该结果。当结果为''时,为假值,index不会被更新。¹¹
注意
当将dict用作记录时,通常所有键都是str类型,具体取决于键的不同类型的值。这在“TypedDict”中有所涵盖。
抽象基类
在发送内容时要保守,在接收内容时要开放。
波斯特尔法则,又称韧性原则
表 8-1 列出了几个来自 collections.abc 的抽象类。理想情况下,一个函数应该接受这些抽象类型的参数,或者在 Python 3.9 之前使用它们的 typing 等效类型,而不是具体类型。这样可以给调用者更多的灵活性。
考虑这个函数签名:
from collections.abc import Mapping
def name2hex(name: str, color_map: Mapping[str, int]) -> str:
使用 abc.Mapping 允许调用者提供 dict、defaultdict、ChainMap、UserDict 子类或任何其他是 Mapping 的子类型的类型的实例。
相比之下,考虑这个签名:
def name2hex(name: str, color_map: dict[str, int]) -> str:
现在 color_map 必须是一个 dict 或其子类型之一,比如 defaultDict 或 OrderedDict。特别是,collections.UserDict 的子类不会通过 color_map 的类型检查,尽管这是创建用户定义映射的推荐方式,正如我们在 “子类化 UserDict 而不是 dict” 中看到的那样。Mypy 会拒绝 UserDict 或从它派生的类的实例,因为 UserDict 不是 dict 的子类;它们是同级。两者都是 abc.MutableMapping 的子类。¹²
因此,一般来说最好在参数类型提示中使用 abc.Mapping 或 abc.MutableMapping,而不是 dict(或在旧代码中使用 typing.Dict)。如果 name2hex 函数不需要改变给定的 color_map,那么 color_map 的最准确的类型提示是 abc.Mapping。这样,调用者不需要提供实现 setdefault、pop 和 update 等方法的对象,这些方法是 MutableMapping 接口的一部分,但不是 Mapping 的一部分。这与 Postel 法则的第二部分有关:“在接受输入时要宽容。”
Postel 法则还告诉我们在发送内容时要保守。函数的返回值始终是一个具体对象,因此返回类型提示应该是一个具体类型,就像来自 “通用集合” 的示例一样—使用 list[str]:
def tokenize(text: str) -> list[str]:
return text.upper().split()
在 typing.List 的条目中,Python 文档中写道:
list的泛型版本。用于注释返回类型。为了注释参数,最好使用抽象集合类型,如Sequence或Iterable。
在 typing.Dict 和 typing.Set 的条目中也有类似的评论。
请记住,collections.abc 中的大多数 ABCs 和其他具体类,以及内置集合,都支持类似 collections.deque[str] 的泛型类型提示符号,从 Python 3.9 开始。相应的 typing 集合仅需要支持在 Python 3.8 或更早版本中编写的代码。变成泛型的类的完整列表出现在 “实现” 部分的 PEP 585—标准集合中的类型提示泛型 中。
结束我们关于类型提示中 ABCs 的讨论,我们需要谈一谈 numbers ABCs。
数字塔的崩塌
numbers 包定义了在 PEP 3141—为数字定义的类型层次结构 中描述的所谓数字塔。该塔是一种线性的 ABC 层次结构,顶部是 Number:
-
Number -
Complex -
Real -
Rational -
Integral
这些 ABCs 对于运行时类型检查非常有效,但不支持静态类型检查。PEP 484 的 “数字塔” 部分拒绝了 numbers ABCs,并规定内置类型 complex、float 和 int 应被视为特殊情况,如 “int 与 complex 一致” 中所解释的那样。
我们将在 “numbers ABCs 和数字协议” 中回到这个问题,在 第十三章 中,该章节专门对比协议和 ABCs。
实际上,如果您想要为静态类型检查注释数字参数,您有几个选择:
-
使用
int、float或complex中的一个具体类型—正如 PEP 488 建议的那样。 -
声明一个联合类型,如
Union[float, Decimal, Fraction]。 -
如果想避免硬编码具体类型,请使用像
SupportsFloat这样的数值协议,详见“运行时可检查的静态协议”。
即将到来的章节“静态协议”是理解数值协议的先决条件。
与此同时,让我们来看看对于类型提示最有用的 ABC 之一:Iterable。
可迭代对象
我刚引用的 typing.List 文档建议在函数参数类型提示中使用 Sequence 和 Iterable。
Iterable 参数的一个示例出现在标准库中的 math.fsum 函数中:
def fsum(__seq: Iterable[float]) -> float:
存根文件和 Typeshed 项目
截至 Python 3.10,标准库没有注释,但 Mypy、PyCharm 等可以在 Typeshed 项目中找到必要的类型提示,形式为存根文件:特殊的带有 .pyi 扩展名的源文件,具有带注释的函数和方法签名,但没有实现——类似于 C 中的头文件。
math.fsum 的签名在 /stdlib/2and3/math.pyi 中。__seq 中的前导下划线是 PEP 484 中关于仅限位置参数的约定,解释在“注释仅限位置参数和可变参数”中。
示例 8-15 是另一个使用 Iterable 参数的示例,产生的项目是 tuple[str, str]。以下是函数的使用方式:
>>> l33t = [('a', '4'), ('e', '3'), ('i', '1'), ('o', '0')]
>>> text = 'mad skilled noob powned leet'
>>> from replacer import zip_replace
>>> zip_replace(text, l33t)
'm4d sk1ll3d n00b p0wn3d l33t'
示例 8-15 展示了它的实现方式。
示例 8-15. replacer.py
from collections.abc import Iterable
FromTo = tuple[str, str] # ①
def zip_replace(text: str, changes: Iterable[FromTo]) -> str: # ②
for from_, to in changes:
text = text.replace(from_, to)
return text
①
FromTo 是一个类型别名:我将 tuple[str, str] 赋给 FromTo,以使 zip_replace 的签名更易读。
②
changes 需要是一个 Iterable[FromTo];这与 Iterable[tuple[str, str]] 相同,但更短且更易读。
Python 3.10 中的显式 TypeAlias
PEP 613—显式类型别名引入了一个特殊类型,TypeAlias,用于使创建类型别名的赋值更加可见和易于类型检查。从 Python 3.10 开始,这是创建类型别名的首选方式:
from typing import TypeAlias
FromTo: TypeAlias = tuple[str, str]
abc.Iterable 与 abc.Sequence
math.fsum 和 replacer.zip_replace 都必须遍历整个 Iterable 参数才能返回结果。如果给定一个无限迭代器,比如 itertools.cycle 生成器作为输入,这些函数将消耗所有内存并导致 Python 进程崩溃。尽管存在潜在的危险,但在现代 Python 中,提供接受 Iterable 输入的函数即使必须完全处理它才能返回结果是相当常见的。这样一来,调用者可以选择将输入数据提供为生成器,而不是预先构建的序列,如果输入项的数量很大,可能会节省大量内存。
另一方面,来自示例 8-13 的 columnize 函数需要一个 Sequence 参数,而不是 Iterable,因为它必须获取输入的 len() 来提前计算行数。
与 Sequence 类似,Iterable 最适合用作参数类型。作为返回类型太模糊了。函数应该更加精确地说明返回的具体类型。
与 Iterable 密切相关的是 Iterator 类型,在 示例 8-14 中用作返回类型。我们将在第十七章中回到这个话题,讨论生成器和经典迭代器。
参数化泛型和 TypeVar
参数化泛型是一种泛型类型,写作 list[T],其中 T 是一个类型变量,将在每次使用时绑定到特定类型。这允许参数类型反映在结果类型上。
示例 8-16 定义了sample,一个接受两个参数的函数:类型为T的元素的Sequence和一个int。它从第一个参数中随机选择的相同类型T的元素的list。
示例 8-16 展示了实现。
示例 8-16。sample.py
from collections.abc import Sequence
from random import shuffle
from typing import TypeVar
T = TypeVar('T')
def sample(population: Sequence[T], size: int) -> list[T]:
if size < 1:
raise ValueError('size must be >= 1')
result = list(population)
shuffle(result)
return result[:size]
这里有两个例子说明我在sample中使用了一个类型变量:
-
如果使用类型为
tuple[int, ...]的元组——这与Sequence[int]一致——那么类型参数是int,因此返回类型是list[int]。 -
如果使用
str——这与Sequence[str]一致——那么类型参数是str,因此返回类型是list[str]。
为什么需要 TypeVar?
PEP 484 的作者希望通过添加typing模块引入类型提示,而不改变语言的其他任何内容。通过巧妙的元编程,他们可以使[]运算符在类似Sequence[T]的类上起作用。但括号内的T变量名称必须在某处定义,否则 Python 解释器需要进行深层更改才能支持通用类型符号作为[]的特殊用途。这就是为什么需要typing.TypeVar构造函数:引入当前命名空间中的变量名称。像 Java、C#和 TypeScript 这样的语言不需要事先声明类型变量的名称,因此它们没有 Python 的TypeVar类的等价物。
另一个例子是标准库中的statistics.mode函数,它返回系列中最常见的数据点。
这里是来自文档的一个使用示例:
>>> mode([1, 1, 2, 3, 3, 3, 3, 4])
3
如果不使用TypeVar,mode可能具有示例 8-17 中显示的签名。
示例 8-17。mode_float.py:对float和子类型进行操作的mode¹³
from collections import Counter
from collections.abc import Iterable
def mode(data: Iterable[float]) -> float:
pairs = Counter(data).most_common(1)
if len(pairs) == 0:
raise ValueError('no mode for empty data')
return pairs[0][0]
许多mode的用法涉及int或float值,但 Python 还有其他数值类型,希望返回类型遵循给定Iterable的元素类型。我们可以使用TypeVar来改进该签名。让我们从一个简单但错误的参数化签名开始:
from collections.abc import Iterable
from typing import TypeVar
T = TypeVar('T')
def mode(data: Iterable[T]) -> T:
当类型参数T首次出现在签名中时,它可以是任何类型。第二次出现时,它将意味着与第一次相同的类型。
因此,每个可迭代对象都与Iterable[T]一致,包括collections.Counter无法处理的不可哈希类型的可迭代对象。我们需要限制分配给T的可能类型。我们将在接下来的两节中看到两种方法。
限制的 TypeVar
TypeVar接受额外的位置参数来限制类型参数。我们可以改进mode的签名,接受特定的数字类型,就像这样:
from collections.abc import Iterable
from decimal import Decimal
from fractions import Fraction
from typing import TypeVar
NumberT = TypeVar('NumberT', float, Decimal, Fraction)
def mode(data: Iterable[NumberT]) -> NumberT:
这比以前好,这是 2020 年 5 月 25 日typeshed上statistics.pyi存根文件中mode的签名。
然而,statistics.mode文档中包含了这个例子:
>>> mode(["red", "blue", "blue", "red", "green", "red", "red"])
'red'
匆忙之间,我们可以将str添加到NumberT的定义中:
NumberT = TypeVar('NumberT', float, Decimal, Fraction, str)
当然,这样做是有效的,但如果它接受str,那么NumberT的命名就非常不合适。更重要的是,我们不能永远列出类型,因为我们意识到mode可以处理它们。我们可以通过TypeVar的另一个特性做得更好,接下来介绍。
有界的 TypeVar
查看示例 8-17 中mode的主体,我们看到Counter类用于排名。Counter 基于dict,因此data可迭代对象的元素类型必须是可哈希的。
起初,这个签名似乎可以工作:
from collections.abc import Iterable, Hashable
def mode(data: Iterable[Hashable]) -> Hashable:
现在的问题是返回项的类型是Hashable:一个只实现__hash__方法的 ABC。因此,类型检查器不会让我们对返回值做任何事情,除了调用hash()。并不是很有用。
解决方案是TypeVar的另一个可选参数:bound关键字参数。它为可接受的类型设置了一个上限。在示例 8-18 中,我们有bound=Hashable,这意味着类型参数可以是Hashable或其任何子类型。¹⁴
示例 8-18。mode_hashable.py:与示例 8-17 相同,但具有更灵活的签名
from collections import Counter
from collections.abc import Iterable, Hashable
from typing import TypeVar
HashableT = TypeVar('HashableT', bound=Hashable)
def mode(data: Iterable[HashableT]) -> HashableT:
pairs = Counter(data).most_common(1)
if len(pairs) == 0:
raise ValueError('no mode for empty data')
return pairs[0][0]
总结一下:
-
限制类型变量将被设置为
TypeVar声明中命名的类型之一。 -
有界类型变量将被设置为表达式的推断类型——只要推断类型与
TypeVar的bound=关键字参数中声明的边界一致即可。
注意
不幸的是,声明有界TypeVar的关键字参数被命名为bound=,因为动词“绑定”通常用于表示设置变量的值,在 Python 的引用语义中最好描述为将名称绑定到值。如果关键字参数被命名为boundary=会更少令人困惑。
typing.TypeVar构造函数还有其他可选参数——covariant和contravariant——我们将在第十五章中介绍,“Variance”中涵盖。
让我们用AnyStr结束对TypeVar的介绍。
预定义的 AnyStr 类型变量
typing模块包括一个预定义的TypeVar,名为AnyStr。它的定义如下:
AnyStr = TypeVar('AnyStr', bytes, str)
AnyStr在许多接受bytes或str的函数中使用,并返回给定类型的值。
现在,让我们来看看typing.Protocol,这是 Python 3.8 的一个新特性,可以支持更具 Python 风格的类型提示的使用。
静态协议
注意
在面向对象编程中,“协议”概念作为一种非正式接口的概念早在 Smalltalk 中就存在,并且从一开始就是 Python 的一个基本部分。然而,在类型提示的背景下,协议是一个typing.Protocol子类,定义了一个类型检查器可以验证的接口。这两种类型的协议在第十三章中都有涉及。这只是在函数注释的背景下的简要介绍。
如PEP 544—Protocols: Structural subtyping (static duck typing)中所述,Protocol类型类似于 Go 中的接口:通过指定一个或多个方法来定义协议类型,并且类型检查器验证在需要该协议类型的地方这些方法是否被实现。
在 Python 中,协议定义被写作typing.Protocol子类。然而,实现协议的类不需要继承、注册或声明与定义协议的类的任何关系。这取决于类型检查器找到可用的协议类型并强制执行它们的使用。
这是一个可以借助Protocol和TypeVar解决的问题。假设您想创建一个函数top(it, n),返回可迭代对象it中最大的n个元素:
>>> top([4, 1, 5, 2, 6, 7, 3], 3)
[7, 6, 5]
>>> l = 'mango pear apple kiwi banana'.split()
>>> top(l, 3)
['pear', 'mango', 'kiwi']
>>>
>>> l2 = [(len(s), s) for s in l]
>>> l2
[(5, 'mango'), (4, 'pear'), (5, 'apple'), (4, 'kiwi'), (6, 'banana')]
>>> top(l2, 3)
[(6, 'banana'), (5, 'mango'), (5, 'apple')]
一个参数化的泛型top看起来像示例 8-19 中所示的样子。
示例 8-19。带有未定义T类型参数的top函数
def top(series: Iterable[T], length: int) -> list[T]:
ordered = sorted(series, reverse=True)
return ordered[:length]
问题是如何约束T?它不能是Any或object,因为series必须与sorted一起工作。sorted内置实际上接受Iterable[Any],但这是因为可选参数key接受一个函数,该函数从每个元素计算任意排序键。如果您给sorted一个普通对象列表但不提供key参数会发生什么?让我们试试:
>>> l = [object() for _ in range(4)]
>>> l
[<object object at 0x10fc2fca0>, <object object at 0x10fc2fbb0>,
<object object at 0x10fc2fbc0>, <object object at 0x10fc2fbd0>]
>>> sorted(l)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'object' and 'object'
错误消息显示sorted在可迭代对象的元素上使用<运算符。这就是全部吗?让我们做另一个快速实验:¹⁵
>>> class Spam:
... def __init__(self, n): self.n = n
... def __lt__(self, other): return self.n < other.n
... def __repr__(self): return f'Spam({self.n})'
...
>>> l = [Spam(n) for n in range(5, 0, -1)]
>>> l
[Spam(5), Spam(4), Spam(3), Spam(2), Spam(1)]
>>> sorted(l)
[Spam(1), Spam(2), Spam(3), Spam(4), Spam(5)]
那证实了:我可以对Spam列表进行sort,因为Spam实现了__lt__——支持<运算符的特殊方法。
因此,示例 8-19 中的 T 类型参数应该限制为实现 __lt__ 的类型。在 示例 8-18 中,我们需要一个实现 __hash__ 的类型参数,因此我们可以使用 typing.Hashable 作为类型参数的上界。但是现在在 typing 或 abc 中没有适合的类型,因此我们需要创建它。
示例 8-20 展示了新的 SupportsLessThan 类型,一个 Protocol。
示例 8-20. comparable.py: SupportsLessThan Protocol 类型的定义
from typing import Protocol, Any
class SupportsLessThan(Protocol): # ①
def __lt__(self, other: Any) -> bool: ... # ②
①
协议是 typing.Protocol 的子类。
②
协议的主体有一个或多个方法定义,方法体中有 ...。
如果类型 T 实现了 P 中定义的所有方法,并且类型签名匹配,则类型 T 与协议 P 一致。
有了 SupportsLessThan,我们现在可以在 示例 8-21 中定义这个可工作的 top 版本。
示例 8-21. top.py: 使用 TypeVar 和 bound=SupportsLessThan 定义 top 函数
from collections.abc import Iterable
from typing import TypeVar
from comparable import SupportsLessThan
LT = TypeVar('LT', bound=SupportsLessThan)
def top(series: Iterable[LT], length: int) -> list[LT]:
ordered = sorted(series, reverse=True)
return ordered[:length]
让我们来测试 top。示例 8-22 展示了一部分用于 pytest 的测试套件。首先尝试使用生成器表达式调用 top,该表达式生成 tuple[int, str],然后使用 object 列表。对于 object 列表,我们期望得到一个 TypeError 异常。
示例 8-22. top_test.py: top 测试套件的部分清单
from collections.abc import Iterator
from typing import TYPE_CHECKING # ①
import pytest
from top import top
# several lines omitted
def test_top_tuples() -> None:
fruit = 'mango pear apple kiwi banana'.split()
series: Iterator[tuple[int, str]] = ( # ②
(len(s), s) for s in fruit)
length = 3
expected = [(6, 'banana'), (5, 'mango'), (5, 'apple')]
result = top(series, length)
if TYPE_CHECKING: # ③
reveal_type(series) # ④
reveal_type(expected)
reveal_type(result)
assert result == expected
# intentional type error
def test_top_objects_error() -> None:
series = [object() for _ in range(4)]
if TYPE_CHECKING:
reveal_type(series)
with pytest.raises(TypeError) as excinfo:
top(series, 3) # ⑤
assert "'<' not supported" in str(excinfo.value)
①
typing.TYPE_CHECKING 常量在运行时始终为 False,但类型检查器在进行类型检查时会假装它为 True。
②
显式声明 series 变量的类型,以使 Mypy 输出更易读。¹⁶
③
这个 if 阻止了接下来的三行在测试运行时执行。
④
reveal_type() 不能在运行时调用,因为它不是常规函数,而是 Mypy 的调试工具—这就是为什么没有为它导入任何内容。对于每个 reveal_type() 伪函数调用,Mypy 将输出一条调试消息,显示参数的推断类型。
⑤
这一行将被 Mypy 标记为错误。
前面的测试通过了—但无论是否在 top.py 中有类型提示,它们都会通过。更重要的是,如果我用 Mypy 检查该测试文件,我会看到 TypeVar 正如预期的那样工作。查看 示例 8-23 中的 mypy 命令输出。
警告
截至 Mypy 0.910(2021 年 7 月),reveal_type 的输出在某些情况下并不精确显示我声明的类型,而是显示兼容的类型。例如,我没有使用 typing.Iterator,而是使用了 abc.Iterator。请忽略这个细节。Mypy 的输出仍然有用。在讨论输出时,我会假装 Mypy 的这个问题已经解决。
示例 8-23. mypy top_test.py 的输出(为了可读性而拆分的行)
…/comparable/ $ mypy top_test.py
top_test.py:32: note:
Revealed type is "typing.Iterator[Tuple[builtins.int, builtins.str]]" # ①
top_test.py:33: note:
Revealed type is "builtins.list[Tuple[builtins.int, builtins.str]]"
top_test.py:34: note:
Revealed type is "builtins.list[Tuple[builtins.int, builtins.str]]" # ②
top_test.py:41: note:
Revealed type is "builtins.list[builtins.object*]" # ③
top_test.py:43: error:
Value of type variable "LT" of "top" cannot be "object" # ④
Found 1 error in 1 file (checked 1 source file)
①
在 test_top_tuples 中,reveal_type(series) 显示它是一个 Iterator[tuple[int, str]]—这是我明确声明的。
②
reveal_type(result) 确认了 top 调用返回的类型是我想要的:给定 series 的类型,result 是 list[tuple[int, str]]。
③
在 test_top_objects_error 中,reveal_type(series) 显示为 list[object*]。Mypy 在任何推断的类型后面加上 *:我没有在这个测试中注释 series 的类型。
④
Mypy 标记了这个测试故意触发的错误:Iterable series的元素类型不能是object(必须是SupportsLessThan类型)。
协议类型相对于 ABCs 的一个关键优势是,一个类型不需要任何特殊声明来与协议类型一致。这允许创建一个协议利用预先存在的类型,或者在我们无法控制的代码中实现的类型。我不需要派生或注册str、tuple、float、set等类型到SupportsLessThan以在期望SupportsLessThan参数的地方使用它们。它们只需要实现__lt__。而类型检查器仍然能够完成其工作,因为SupportsLessThan被明确定义为Protocol—与鸭子类型常见的隐式协议相反,这些协议对类型检查器是不可见的。
特殊的Protocol类在PEP 544—Protocols: Structural subtyping (static duck typing)中引入。示例 8-21 展示了为什么这个特性被称为静态鸭子类型:注释top的series参数的解决方案是说“series的名义类型并不重要,只要它实现了__lt__方法。”Python 的鸭子类型总是允许我们隐式地说这一点,让静态类型检查器一头雾水。类型检查器无法阅读 CPython 的 C 源代码,或者执行控制台实验来发现sorted只需要元素支持<。
现在我们可以为静态类型检查器明确地定义鸭子类型。这就是为什么说typing.Protocol给我们静态鸭子类型是有意义的。¹⁷
还有更多关于typing.Protocol的内容。我们将在第四部分回来讨论它,在第十三章中对比结构化类型、鸭子类型和 ABCs——另一种形式化协议的方法。此外,“重载签名”(第十五章)解释了如何使用@typing.overload声明重载函数签名,并包括了一个使用typing.Protocol和有界TypeVar的广泛示例。
注意
typing.Protocol使得可以注释“类型由支持的操作定义”中提到的double函数而不会失去功能。关键是定义一个带有__mul__方法的协议类。我邀请你将其作为练习完成。解决方案出现在“类型化的 double 函数”中(第十三章)。
Callable
为了注释回调参数或由高阶函数返回的可调用对象,collections.abc模块提供了Callable类型,在尚未使用 Python 3.9 的情况下在typing模块中可用。Callable类型的参数化如下:
Callable[[ParamType1, ParamType2], ReturnType]
参数列表—[ParamType1, ParamType2]—可以有零个或多个类型。
这是在我们将在“lis.py 中的模式匹配:案例研究”中看到的一个repl函数的示例:¹⁸
def repl(input_fn: Callable[[Any], str] = input]) -> None:
在正常使用中,repl函数使用 Python 的input内置函数从用户那里读取表达式。然而,对于自动化测试或与其他输入源集成,repl接受一个可选的input_fn参数:一个与input具有相同参数和返回类型的Callable。
内置的input在 typeshed 上有这个签名:
def input(__prompt: Any = ...) -> str: ...
input的签名与这个Callable类型提示一致:
Callable[[Any], str]
没有语法来注释可选或关键字参数类型。typing.Callable的文档说“这样的函数类型很少用作回调类型。”如果你需要一个类型提示来匹配具有灵活签名的函数,用...替换整个参数列表—就像这样:
Callable[..., ReturnType]
泛型类型参数与类型层次结构的交互引入了一个新的类型概念:variance。
Callable 类型中的 variance
想象一个简单的温度控制系统,其中有一个简单的update函数,如示例 8-24 所示。update函数调用probe函数获取当前温度,并调用display显示温度给用户。probe和display都作为参数传递给update是为了教学目的。示例的目标是对比两个Callable注释:一个有返回类型,另一个有参数类型。
示例 8-24。说明 variance。
from collections.abc import Callable
def update( # ①
probe: Callable[[], float], # ②
display: Callable[[float], None] # ③
) -> None:
temperature = probe()
# imagine lots of control code here
display(temperature)
def probe_ok() -> int: # ④
return 42
def display_wrong(temperature: int) -> None: # ⑤
print(hex(temperature))
update(probe_ok, display_wrong) # type error # ⑥
def display_ok(temperature: complex) -> None: # ⑦
print(temperature)
update(probe_ok, display_ok) # OK # ⑧
①
update接受两个可调用对象作为参数。
②
probe必须是一个不带参数并返回float的可调用对象。
③
display接受一个float参数并返回None。
④
probe_ok与Callable[[], float]一致,因为返回一个int不会破坏期望float的代码。
⑤
display_wrong与Callable[[float], None]不一致,因为没有保证一个期望int的函数能处理一个float;例如,Python 的hex函数接受一个int但拒绝一个float。
⑥
Mypy 标记这行是因为display_wrong与update的display参数中的类型提示不兼容。
⑦
display_ok与Callable[[float], None]一致,因为一个接受complex的函数也可以处理一个float参数。
⑧
Mypy 对这行很满意。
总结一下,当代码期望返回float的回调时,提供返回int的回调是可以的,因为int值总是可以在需要float的地方使用。
正式地说,Callable[[], int]是subtype-ofCallable[[], float]——因为int是subtype-offloat。这意味着Callable在返回类型上是协变的,因为类型int和float的subtype-of关系与使用它们作为返回类型的Callable类型的关系方向相同。
另一方面,当需要处理float时,提供一个接受int参数的回调是类型错误的。
正式地说,Callable[[int], None]不是subtype-ofCallable[[float], None]。虽然int是subtype-offloat,但在参数化的Callable类型中,关系是相反的:Callable[[float], None]是subtype-ofCallable[[int], None]。因此我们说Callable在声明的参数类型上是逆变的。
“Variance”在第十五章中详细解释了 variance,并提供了不变、协变和逆变类型的更多细节和示例。
提示
目前,可以放心地说,大多数参数化的泛型类型是invariant,因此更简单。例如,如果我声明scores: list[float],那告诉我可以分配给scores的对象。我不能分配声明为list[int]或list[complex]的对象:
-
一个
list[int]对象是不可接受的,因为它不能容纳float值,而我的代码可能需要将其放入scores中。 -
一个
list[complex]对象是不可接受的,因为我的代码可能需要对scores进行排序以找到中位数,但complex没有提供__lt__,因此list[complex]是不可排序的。
现在我们来讨论本章中最后一个特殊类型。
NoReturn
这是一种特殊类型,仅用于注释永远不返回的函数的返回类型。通常,它们存在是为了引发异常。标准库中有数十个这样的函数。
例如,sys.exit()引发SystemExit来终止 Python 进程。
它在typeshed中的签名是:
def exit(__status: object = ...) -> NoReturn: ...
__status参数是仅位置参数,并且具有默认值。存根文件不详细说明默认值,而是使用...。__status的类型是object,这意味着它也可能是None,因此标记为Optional[object]将是多多的。
在第二十四章中,示例 24-6 在__flag_unknown_attrs中使用NoReturn,这是一个旨在生成用户友好和全面错误消息的方法,然后引发AttributeError。
这一史诗般章节的最后一节是关于位置和可变参数。
注释位置参数和可变参数
回想一下从示例 7-9 中的tag函数。我们上次看到它的签名是在“仅位置参数”中:
def tag(name, /, *content, class_=None, **attrs):
这里是tag,完全注释,写成几行——长签名的常见约定,使用换行符的方式,就像蓝色格式化程序会做的那样:
from typing import Optional
def tag(
name: str,
/,
*content: str,
class_: Optional[str] = None,
**attrs: str,
) -> str:
注意对于任意位置参数的类型提示*content: str;这意味着所有这些参数必须是str类型。函数体中content的类型将是tuple[str, ...]。
在这个例子中,任意关键字参数的类型提示是**attrs: str,因此函数内部的attrs类型将是dict[str, str]。对于像**attrs: float这样的类型提示,函数内部的attrs类型将是dict[str, float]。
如果attrs参数必须接受不同类型的值,你需要使用Union[]或Any:**attrs: Any。
仅位置参数的/符号仅适用于 Python ≥ 3.8。在 Python 3.7 或更早版本中,这将是语法错误。PEP 484 约定是在每个位置参数名称前加上两个下划线。这里是tag签名,再次以两行的形式,使用 PEP 484 约定:
from typing import Optional
def tag(__name: str, *content: str, class_: Optional[str] = None,
**attrs: str) -> str:
Mypy 理解并强制执行声明位置参数的两种方式。
为了结束这一章,让我们简要地考虑一下类型提示的限制以及它们支持的静态类型系统。
不完美的类型和强大的测试
大型公司代码库的维护者报告说,许多错误是由静态类型检查器发现的,并且比在代码运行在生产环境后才发现这些错误更便宜修复。然而,值得注意的是,在我所知道的公司中,自动化测试在静态类型引入之前就是标准做法并被广泛采用。
即使在它们最有益处的情况下,静态类型也不能被信任为正确性的最终仲裁者。很容易找到:
假阳性
工具会报告代码中正确的类型错误。
假阴性
工具不会报告代码中不正确的类型错误。
此外,如果我们被迫对所有内容进行类型检查,我们将失去 Python 的一些表现力:
-
一些方便的功能无法进行静态检查;例如,像
config(**settings)这样的参数解包。 -
属性、描述符、元类和一般元编程等高级功能对类型检查器的支持较差或超出理解范围。
-
类型检查器落后于 Python 版本,拒绝甚至在分析具有新语言特性的代码时崩溃——在某些情况下超过一年。
通常的数据约束无法在类型系统中表达,甚至是简单的约束。例如,类型提示无法确保“数量必须是大于 0 的整数”或“标签必须是具有 6 到 12 个 ASCII 字母的字符串”。总的来说,类型提示对捕捉业务逻辑中的错误并不有帮助。
鉴于这些注意事项,类型提示不能成为软件质量的主要支柱,强制性地使其成为例外会放大缺点。
将静态类型检查器视为现代 CI 流水线中的工具之一,与测试运行器、代码检查器等一起。CI 流水线的目的是减少软件故障,自动化测试可以捕获许多超出类型提示范围的错误。你可以在 Python 中编写的任何代码,都可以在 Python 中进行测试,无论是否有类型提示。
注
本节的标题和结论受到 Bruce Eckel 的文章“强类型 vs. 强测试”的启发,该文章也发表在 Joel Spolsky(Apress)编辑的文集The Best Software Writing I中。Bruce 是 Python 的粉丝,也是关于 C++、Java、Scala 和 Kotlin 的书籍的作者。在那篇文章中,他讲述了他是如何成为静态类型支持者的,直到学习 Python 并得出结论:“如果一个 Python 程序有足够的单元测试,它可以和有足够单元测试的 C++、Java 或 C#程序一样健壮(尽管 Python 中的测试编写速度更快)。”
目前我们的 Python 类型提示覆盖到这里。它们也是第十五章的主要内容,该章涵盖了泛型类、变异、重载签名、类型转换等。与此同时,类型提示将在本书的几个示例中做客串出现。
章节总结
我们从对渐进式类型概念的简要介绍开始,然后转向实践方法。没有一个实际读取类型提示的工具,很难看出渐进式类型是如何工作的,因此我们开发了一个由 Mypy 错误报告引导的带注解函数。
回到渐进式类型的概念,我们探讨了它是 Python 传统鸭子类型和用户更熟悉的 Java、C++等静态类型语言的名义类型的混合体。
大部分章节都致力于介绍注解中使用的主要类型组。我们涵盖的许多类型与熟悉的 Python 对象类型相关,如集合、元组和可调用对象,扩展以支持类似Sequence[float]的泛型表示。许多这些类型是在 Python 3.9 之前在typing模块中实现的临时替代品,直到标准类型被更改以支持泛型。
一些类型是特殊实体。Any、Optional、Union和NoReturn与内存中的实际对象无关,而仅存在于类型系统的抽象领域中。
我们研究了参数化泛型和类型变量,这为类型提示带来了更多灵活性,而不会牺牲类型安全性。
使用Protocol使参数化泛型变得更加表达丰富。因为它仅出现在 Python 3.8 中,Protocol目前并不广泛使用,但它非常重要。Protocol实现了静态鸭子类型:Python 鸭子类型核心与名义类型之间的重要桥梁,使静态类型检查器能够捕捉错误。
在介绍一些类型的同时,我们通过 Mypy 进行实验,以查看类型检查错误,并借助 Mypy 的神奇reveal_type()函数推断类型。
最后一节介绍了如何注释位置参数和可变参数。
类型提示是一个复杂且不断发展的主题。幸运的是,它们是一个可选功能。让我们保持 Python 对最广泛用户群体的可访问性,并停止宣扬所有 Python 代码都应该有类型提示的说法,就像我在类型提示布道者的公开布道中看到的那样。
我们的退休 BDFL¹⁹领导了 Python 中类型提示的推动,因此这一章的开头和结尾都以他的话语开始:
我不希望有一个我在任何时候都有道义义务添加类型提示的 Python 版本。我真的认为类型提示有它们的位置,但也有很多时候不值得,而且很棒的是你可以选择使用它们。²⁰
Guido van Rossum
进一步阅读
Bernát Gábor 在他的优秀文章中写道,“Python 中类型提示的现状”:
只要值得编写单元测试,就应该使用类型提示。
我是测试的忠实粉丝,但我也做很多探索性编码。当我在探索时,测试和类型提示并不有用。它们只是累赘。
Gábor 的文章是我发现的关于 Python 类型提示的最好介绍之一,还有 Geir Arne Hjelle 的“Python 类型检查(指南)”。Claudio Jolowicz 的“超现代 Python 第四章:类型”是一个更简短的介绍,也涵盖了运行时类型检查验证。
想要更深入的了解,Mypy 文档是最佳来源。它对于任何类型检查器都很有价值,因为它包含了关于 Python 类型提示的教程和参考页面,不仅仅是关于 Mypy 工具本身。在那里你还会找到一份方便的速查表和一个非常有用的页面,介绍了常见问题和解决方案。
typing模块文档是一个很好的快速参考,但它并没有详细介绍。PEP 483—类型提示理论包括了关于协变性的深入解释,使用Callable来说明逆变性。最终的参考资料是与类型提示相关的 PEP 文档。已经有 20 多个了。PEP 的目标受众是 Python 核心开发人员和 Python 的指导委员会,因此它们假定读者具有大量先前知识,绝对不是轻松阅读。
如前所述,第十五章涵盖了更多类型相关主题,而“进一步阅读”提供了额外的参考资料,包括表 15-1,列出了截至 2021 年底已批准或正在讨论的类型 PEPs。
“了不起的 Python 类型提示”是一个有价值的链接集合,包含了工具和参考资料。
¹ PEP 484—类型提示,“基本原理和目标”;粗体强调保留自原文。
² PyPy 中的即时编译器比类型提示有更好的数据:它在 Python 程序运行时监视程序,检测使用的具体类型,并为这些具体类型生成优化的机器代码。
³ 例如,截至 2021 年 7 月,不支持递归类型—参见typing模块问题#182,定义 JSON 类型和 Mypy 问题#731,支持递归类型。
⁴ Python 没有提供控制类型可能值集合的语法—除了在Enum类型中。例如,使用类型提示,你无法将Quantity定义为介于 1 和 1000 之间的整数,或将AirportCode定义为 3 个字母的组合。NumPy 提供了uint8、int16和其他面向机器的数值类型,但在 Python 标准库中,我们只有具有非常小值集合(NoneType、bool)或极大值集合(float、int、str、所有可能的元组等)的类型。
⁵ 鸭子类型是一种隐式的结构类型形式,Python ≥ 3.8 也支持引入typing.Protocol。这将在本章后面—“静态协议”—进行介绍,更多细节请参见第十三章。
⁶ 继承经常被滥用,并且很难在现实但简单的示例中证明其合理性,因此请接受这个动物示例作为子类型的快速说明。
⁷ 麻省理工学院教授、编程语言设计师和图灵奖获得者。维基百科:芭芭拉·利斯科夫。
⁸ 更准确地说,ord仅接受len(s) == 1的str或bytes。但目前的类型系统无法表达这个约束。
⁹ 在 ABC 语言——最初影响 Python 设计的语言中——每个列表都受限于接受单一类型的值:您放入其中的第一个项目的类型。
¹⁰ 我对typing模块文档的贡献之一是在 Guido van Rossum 的监督下将“模块内容”下的条目重新组织为子部分,并添加了数十个弃用警告。
¹¹ 在一些示例中,我使用:=是有意义的,但我在书中没有涵盖它。请参阅PEP 572—赋值表达式获取所有详细信息。
¹² 实际上,dict是abc.MutableMapping的虚拟子类。虚拟子类的概念在第十三章中有解释。暂时知道issubclass(dict, abc.MutableMapping)为True,尽管dict是用 C 实现的,不继承任何东西自abc.MutableMapping,而只继承自object。
¹³ 这里的实现比 Python 标准库中的statistics模块更简单。
¹⁴ 我向typeshed贡献了这个解决方案,这就是为什么mode在statistics.pyi中的注释截至 2020 年 5 月 26 日。
¹⁵ 多么美妙啊,打开一个交互式控制台并依靠鸭子类型来探索语言特性,就像我刚才做的那样。当我使用不支持它的语言时,我非常想念这种探索方式。
¹⁶ 没有这个类型提示,Mypy 会将series的类型推断为Generator[Tuple[builtins.int, builtins.str*], None, None],这是冗长的但与Iterator[tuple[int, str]]一致,正如我们将在“通用可迭代类型”中看到的。
¹⁷ 我不知道谁发明了术语静态鸭子类型,但它在 Go 语言中变得更加流行,该语言的接口语义更像 Python 的协议,而不是 Java 的名义接口。
¹⁸ REPL 代表 Read-Eval-Print-Loop,交互式解释器的基本行为。
¹⁹ “终身仁慈独裁者”。参见 Guido van Rossum 关于“BDFL 起源”。
²⁰ 来自 YouTube 视频,“Guido van Rossum 关于类型提示(2015 年 3 月)”。引用开始于13’40”。我进行了一些轻微的编辑以提高清晰度。
²¹ 来源:“与艾伦·凯的对话”。









![【动态规划】【同余前缀和】【多重背包】[推荐]2902. 和带限制的子多重集合的数目](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)