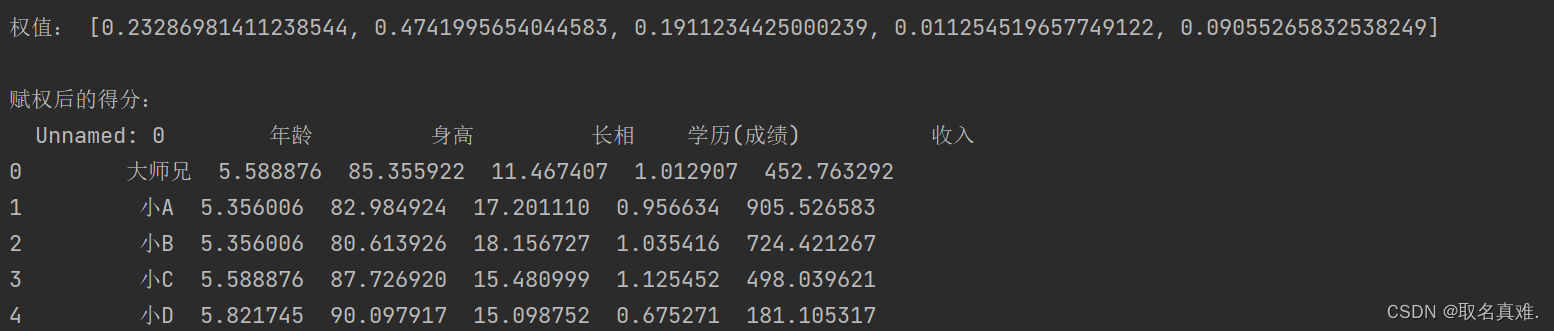
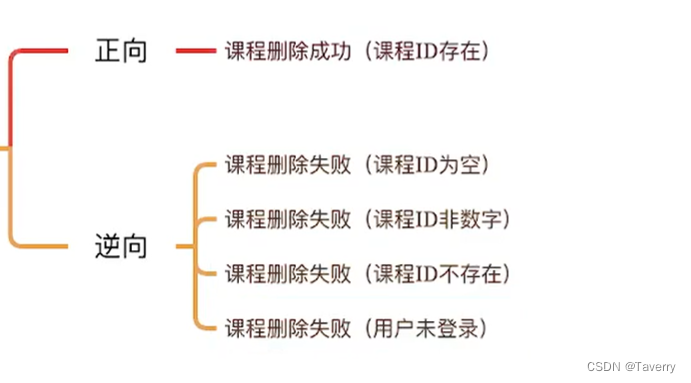
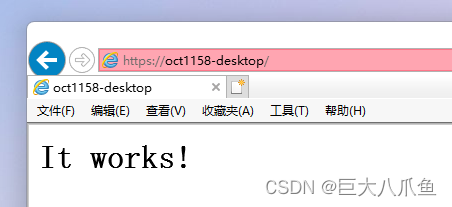
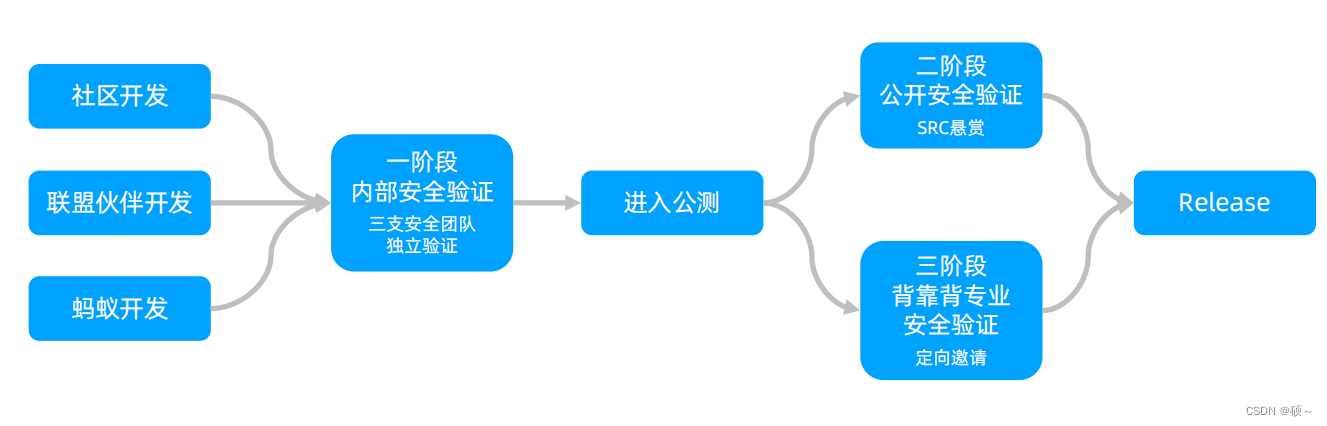
(1)NNLM模型(神经网络语言模型)
语言模型是一个单纯的、统一的、抽象的形式系统,语言客观事实经过语言模型的描述,比较适合于电子计算机进行自动处理,因而语言模型对于自然语言的信息处理具有重大的意义。换一句话说,语言模型其实就是看一句话是不是正常人说出来的正常的话。用神经网络来训练语言模型的思想最早由百度 IDL (深度学习研究院)的徐伟提出[1],其中这方面的一个经典模型是NNLM:已知前面n个词的情况下预测词典中所有次成为第n+1个词的概率,并以此为目标进行训练。总体架构如下:
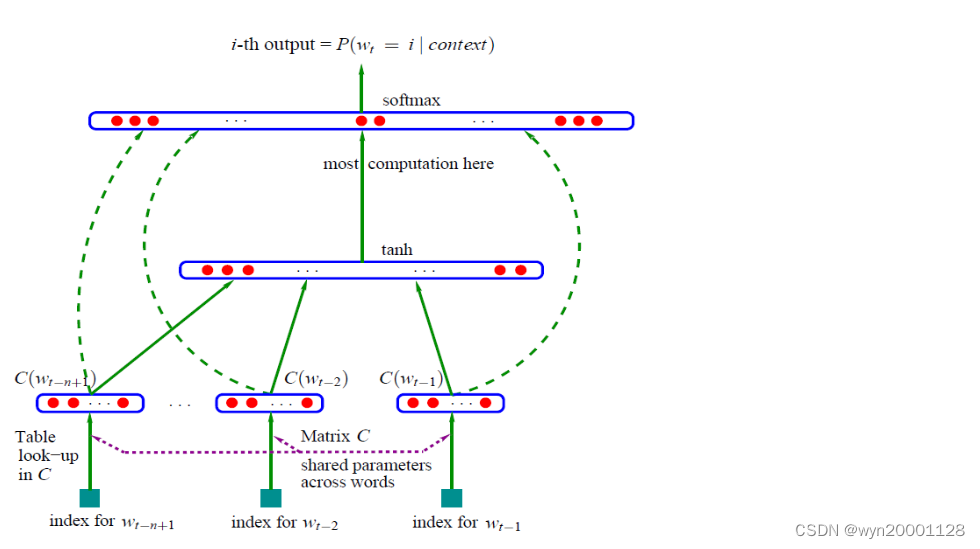
(1)模型输入:待预测的词
w
t
w_t
wt的前n个词
w
t
−
1
,
w
t
−
2
.
.
.
w
t
−
n
+
1
w_{t-1},w_{t-2}...w_{t-n+1}
wt−1,wt−2...wt−n+1
(2)训练过程:
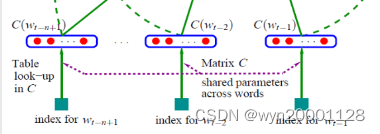
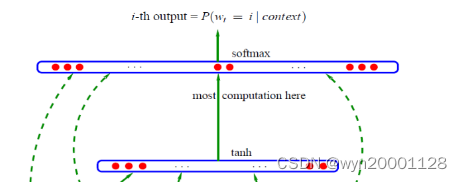
①输入层:把这n个词分别经过一个特征映射矩阵
M
a
t
r
i
x
C
MatrixC
MatrixC进行特征映射以后变成n个特征向量,而后再把这n个特征向量进行拼接。
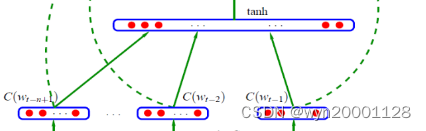
②隐藏层:拼接得到的向量经过一个全连接层再经过激活函数tanh。
③输出层:本质上这也是个全连接层加上softmax。一共有
V
V
V 个结点,其中
V
V
V代表的是词典中的不同的词的个数。其中输出层
V
i
V_i
Vi代表着单词
w
t
w_t
wt是词典的第
i
i
i个单词的概率。
(2)Word2vec
传统的one-hot 编码仅仅只是将词符号化,不包含任何语义信息。 所以我们需要解决两个问题:1 需要赋予词语义信息,2 降低维度。
通过NNML模型的训练以后我们获得了以下东西:词矩阵
M
a
t
r
i
x
Matrix
Matrix,两个全连接层的参数(隐藏层和输出层)
而对于word2vec 而言,词向量矩阵的意义就不一样了,因为Word2Vec的最终目的不是为了得到一个语言模型,而是只关心模型训练完后的副产物:特征映射矩阵
M
a
t
r
i
x
C
MatrixC
MatrixC,用这个可以直接把单词映射成一个K维向量。也就是说Word2vec是NNML模型的一个副产物,而Word2vec是在原有的基础上加上了一些拓展的优化,总结起来可以分为以下几点:(没有去深究,等以后学会了再补上)
①把输出层改造成了Huffman树的形式,采用了Hierarchical Softmax的方法来提高模型的预测准确度
②把词向量模型进一步划分为两种:
(1)CBOW:是一个基于上下文预测当前的目标单词向量模型。
(2)Skip-gram:是已经知道当前词语对上下文进行预测