目录
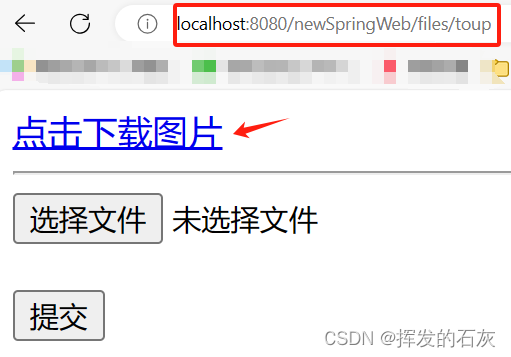
🍭🍬下载页面(其实就一个超链接)
🍭🍬下载的具体操作
🍭🍬结果
承接上传文件,接下来看看下载文件的操作及注意事项
下载页面(其实就一个超链接)
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>文件上传下载</title>
</head>
<body>
<a th:href="@{/files/downlode(fileName=2dfb-海贼王图片2.png)}">点击下载图片</a>
<hr>
<!--下面内容为文件上传博客案例所使用-->
<form th:action="@{/files/uplode}" method="post"
enctype="multipart/form-data">
<input type="file" name="newfile">
<br><br>
<input type="submit" value="提交">
</form>
</body>
</html>
注意:thymeleaf 链接的写法,我们需要通过href给后台传下载文件的名字,我们直接通过/downlode(携带参数),而不是原来的 /files/downlode?fileName='名字' 这样的格式,因为在解析时,这样的格式解析出来的文件名称会携带 ' ' ,导致下载文件找不到
下载的具体操作
//下载
//通过返回 ResponseEntity<byte[]> 对象进行下载
// 参数:读取到的字节数组,相应头信息,相应状态码
@RequestMapping("downlode")
public ResponseEntity<byte[]> downLode(String fileName, HttpServletRequest req){
//获取下载文件的路径
String realPath = req.getServletContext().getRealPath("/uplode/");
//如果知道自己要下载的文件的路径也可以直接写path,比如:“D:/...+文件名称”
String path = realPath+fileName;
//通过字节流下载
InputStream inputStream = null;
try{
inputStream = new FileInputStream(path);
//available,可以估计当前下载文件有多少字节,然后我们设置一个这么大的字节数组进行一次读取
byte[] bytes = new byte[inputStream.available()];
inputStream.read(bytes);
//设置下载的相应头信息
HttpHeaders headers = new HttpHeaders();
headers.setContentDispositionFormData("attachement", "new1.jpg");
//设置:读取内容-响应头信息-状态码
return new ResponseEntity<byte[]>(bytes,headers,HttpStatus.OK);
} catch (IOException e){
e.printStackTrace();
}finally {
//关闭资源
try {
inputStream.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return null;
}1.通过字节流下载文件

2.设置相应头信息,此处第一个参数必须为 attachement ,才能使浏览器识别当前相应为下载相应。第二个参数为下载文件的新文件名。
3.返回 ResponseEntity<byte[]> 对象(三个参数)。
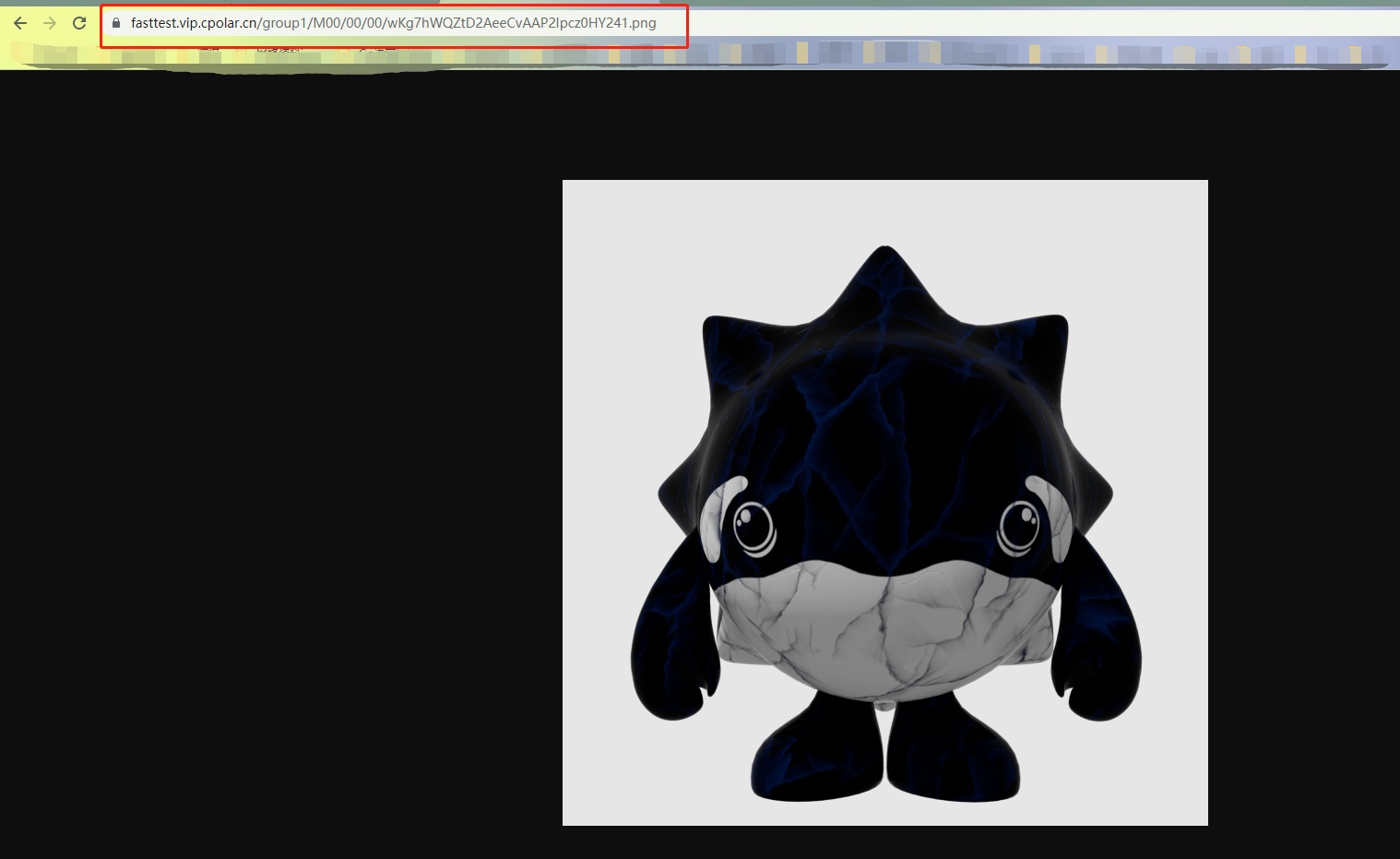
结果

具体下载到哪里,需要看自己使用的浏览器的下载地址