文章目录
- ①. 全表遍历
- ②. Hash结构
- ③. 平衡二叉搜索树(AVL)
- ④. B树
- ⑤. B+树
- ⑥. 时间复杂度
选择的合理性
- 磁盘的I/O操作次数对索引的使用效率至关重要
- 查找都是索引操作,一般来说索引非常大,尤其是关系型数据库,当数据量比较大的时候,索引的大小有可能几个G甚至更多,为了减少索引在内存的占用,数据库索引是储存在外部磁盘上的。当我们利用索引查询的时候,不可能把整个索引全部加载到内存,只能逐一加载,那么MYSQL衡量查询效率的标准就是磁盘IO的次数
①. 全表遍历
- 一行行去寻找记录,假设现在需要查找的数据在最后一行,那么就要从第一行遍历到最后一行,需要把所有的页都加载到内存,耗时且占内容
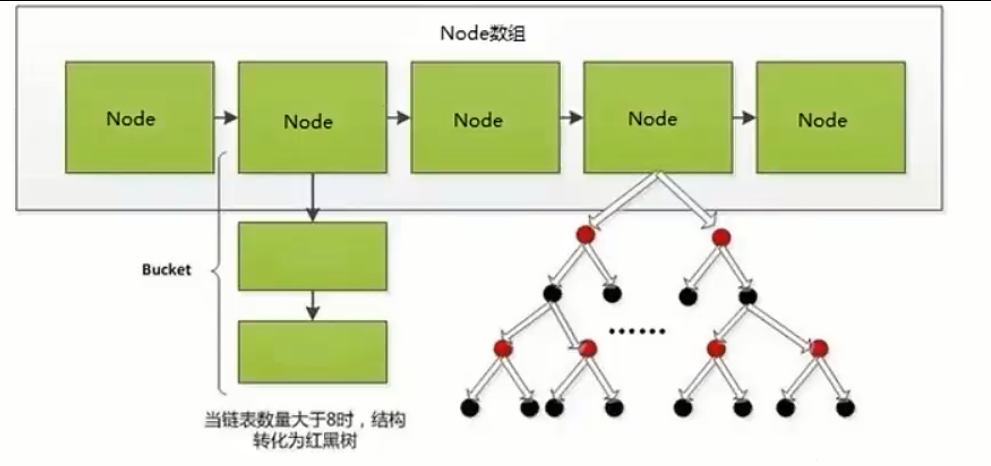
②. Hash结构
-
①. Hash本身就是一个函数,又被称为散列函数,Hash算法是通过某种确定性的算法(比如MD5、SHA1等)将输入转变为输出。相同的输入永远可以得到相同的输出,假设输入内容有微小偏差,在输出中通常会有不同的结果
-
②. 加速查找速度的数据结构,常见的有两类:
- 树,例如平衡二叉搜索树,增删改查的平均时间复杂度都是O(log2 n)
- 哈希,例如HashMap,增删改查的平均时间复杂度都是O(1)
- ③. Hash结构效率高,为什么索引结构要设计成树型呢?
- Hash索引仅能满足(=)(<>)和in查询,如果进行范围查询 ,哈希型的索引,时间复杂度会退化为O(n),而树状的"有序"特性,依然能够保持O(log2N)的高效率
- Hash索引还有一个缺陷,数据的储存是没有顺序的 ,在ORDER BY 的情况下,使用hash索引还需要对数据重新排序
- 对于联合索引的情况,Hash值是将联合索引键合并后一起来计算的,无法对单独的一个或者几个索引键进行查询
- 对于等值查询来说,通常Hash索引的效率更高,不过也存在一种情况,就是索引列的重复值如果有很多,效率就会降低。 这是因为遇到Hash冲突时,需要遍历中的指针进行比较,找到查询关键字,非常耗时。比如列为性别、年龄的情况等
- ④. Hash索引适合储存引擎如表所示:

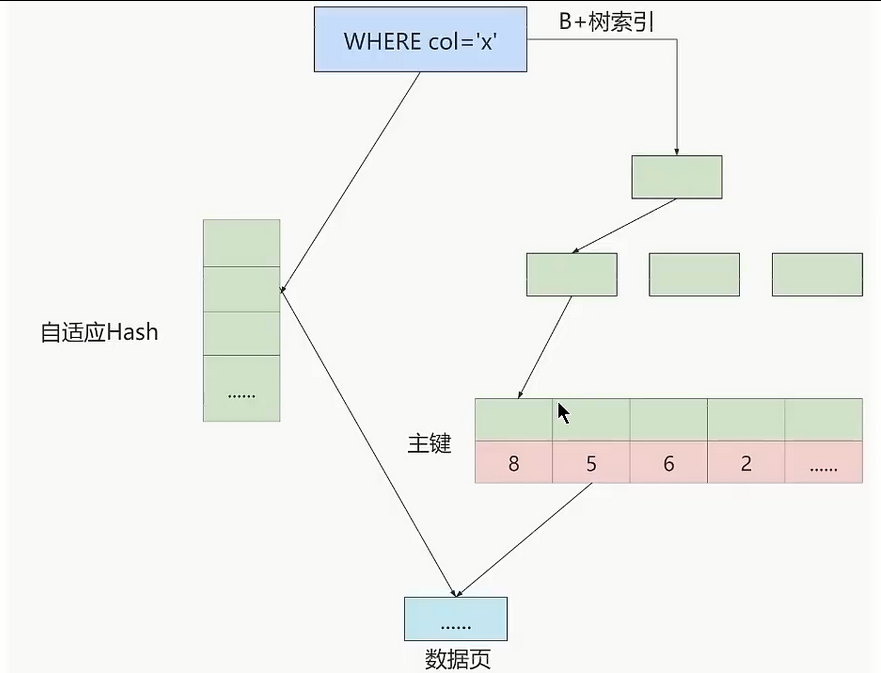
- ⑤. InnoDB本身不支持Hash索引,但是提供自适应Hash索引。什么情况下才会使用自适应Hash索引呢?如果某个数据经常被访问,当满足一定条件的时候,就会将这个数据页的地址存放到Hash表中,这样下次查询的时候,就可能直接找到页面的所在位置,这样让B+树也具备了Hash索引的优点
- 采用自适应Hash索引目的是方便根据SQL的查询条件加速定位到叶子节点,特别是当B+树比较深的时候,通过自适应Hash索引可以明显提高数据的检索效率
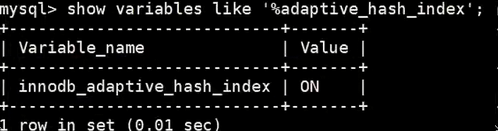
- 我们可以通过innodb_adaptive_hash_index变量来查看是否开启了自适应Hash,比如
show variables like '%adaptive_hash_index%';
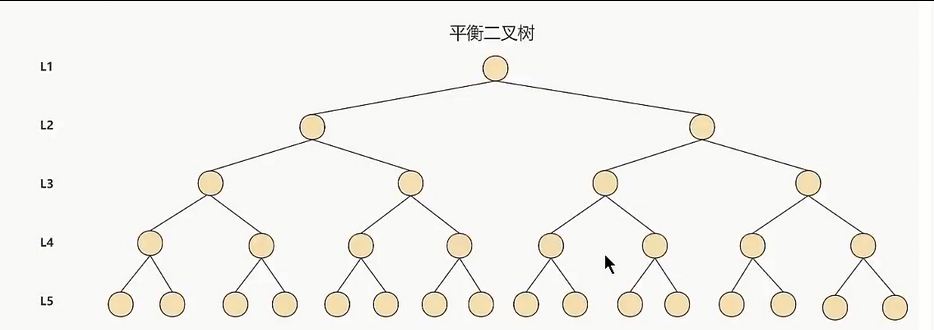
③. 平衡二叉搜索树(AVL)
-
①. 它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
-
②. 每访问一次节点就需要进行一次磁盘I/O操作,对于上面的树来说,我们需要进行5次I/O操作。虽然平衡二叉树的效率高,但是树的深度也同样高,这就意味着磁盘I/O操作次数多,会影响整体数据查询的效率
-
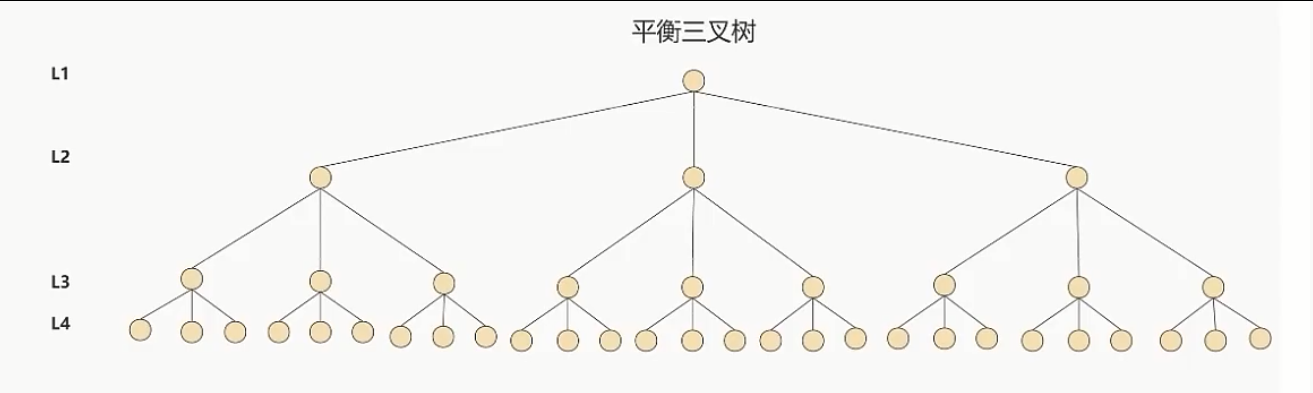
③. 针对同样的数据,如果我们把二叉树改为M叉树(M>2)呢?当M=3,同样的31个节点可以由下面的三叉树来进行储存
你就能看到此时树的高度降低了,当数据量N大的时候,以及树的叉树M大的时候,M叉树的高度会远小于二叉树的高度(M>2)。所以,我们需要把树从"瘦高"变"矮胖"
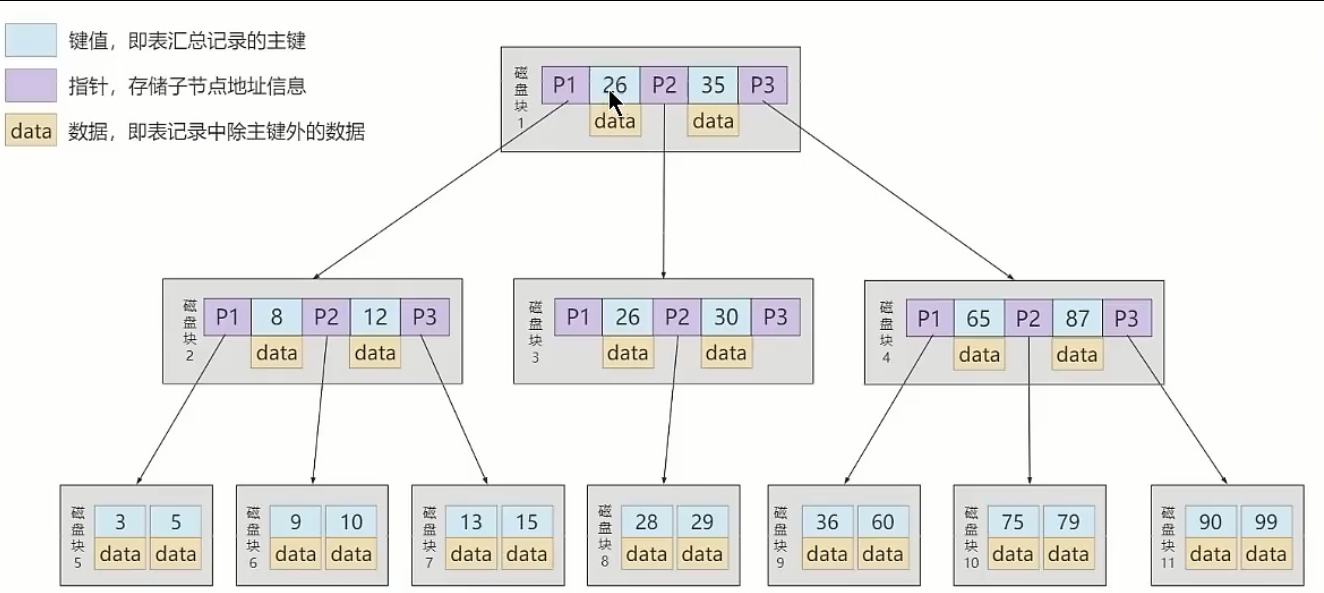
④. B树
-
①. B树,也叫多路平衡查找树,它的高度远小于平衡二叉树的高度。
-
②. 特点:
- B树在插入和删除节点的时候如果导致树不平衡,就通过自动调整节点的位置来保持树的自平衡
- 关键字集合分布在整棵树中,即叶子节点和非叶子节点都存放数据。搜索有可能在非叶子节点结束
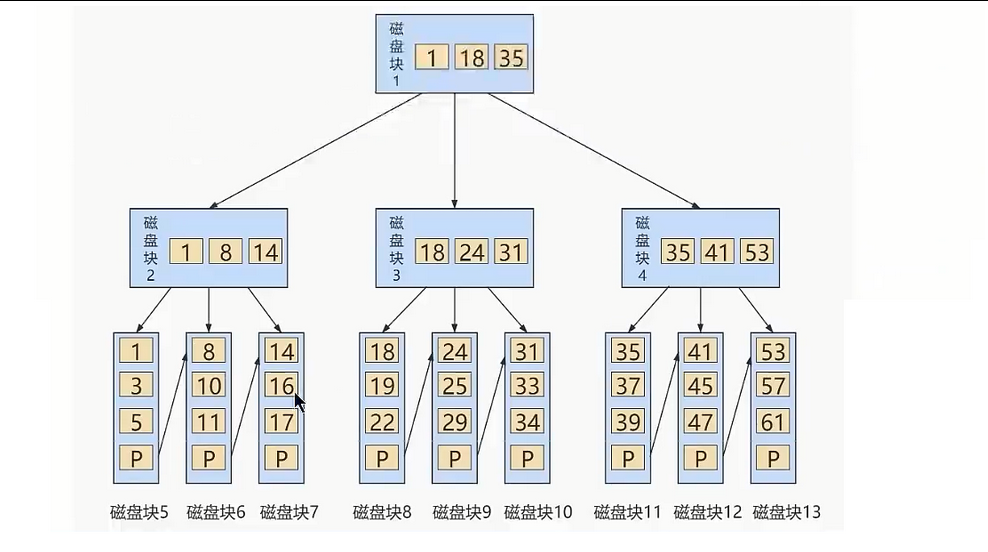
⑤. B+树
- ①. B+树和B树的对比
- B+树中间节点不直接储存元素,B树的叶子节点和非叶子节点都储存元素
- B+树的查询效率更稳定,因为B+树每次只有访问到叶子节点才能找到对应的数据,而在B树中,非叶子节点也储存数据,这样就会造成查询效率不稳定的情况
- B+树的查询效率更高。因为B+树比B树更矮胖(阶数更大,深度更低),查询所需要的磁盘I/O也会更少。同样的磁盘页大小,B+树可以储存更多的节点关键字
- 在查询范围上,B+树的效率也比B树高。因为所有关键字都出现在B+树的叶子节点上,叶子节点之间有指针,数据又是递增的,着使得我们范围查找可以通过指针连接查找。而在B树中则需要通过中序遍历才能完成查询范围的查询,效率要低很多
⑥. 时间复杂度