流量控制
为了系统的健壮性和稳定性考虑,通常要对访问进行有效的控制,防止流量突然暴增,引发一系列服务雪崩效应。
1.单机限流
大概逻辑就是把每个请求当作一个小朋友,把最细粒度Dubbo服务中的方法当作游乐场,每个方法设计出一个标准容量参数,然后在方法开始执行业务逻辑时进行计数加 1,最后在方法结束执行业务时进行计数减 1,而这个计数加 1、计数减 1 就是我们需要的实时容量参数。
于是权限系统的流程图变成这样:
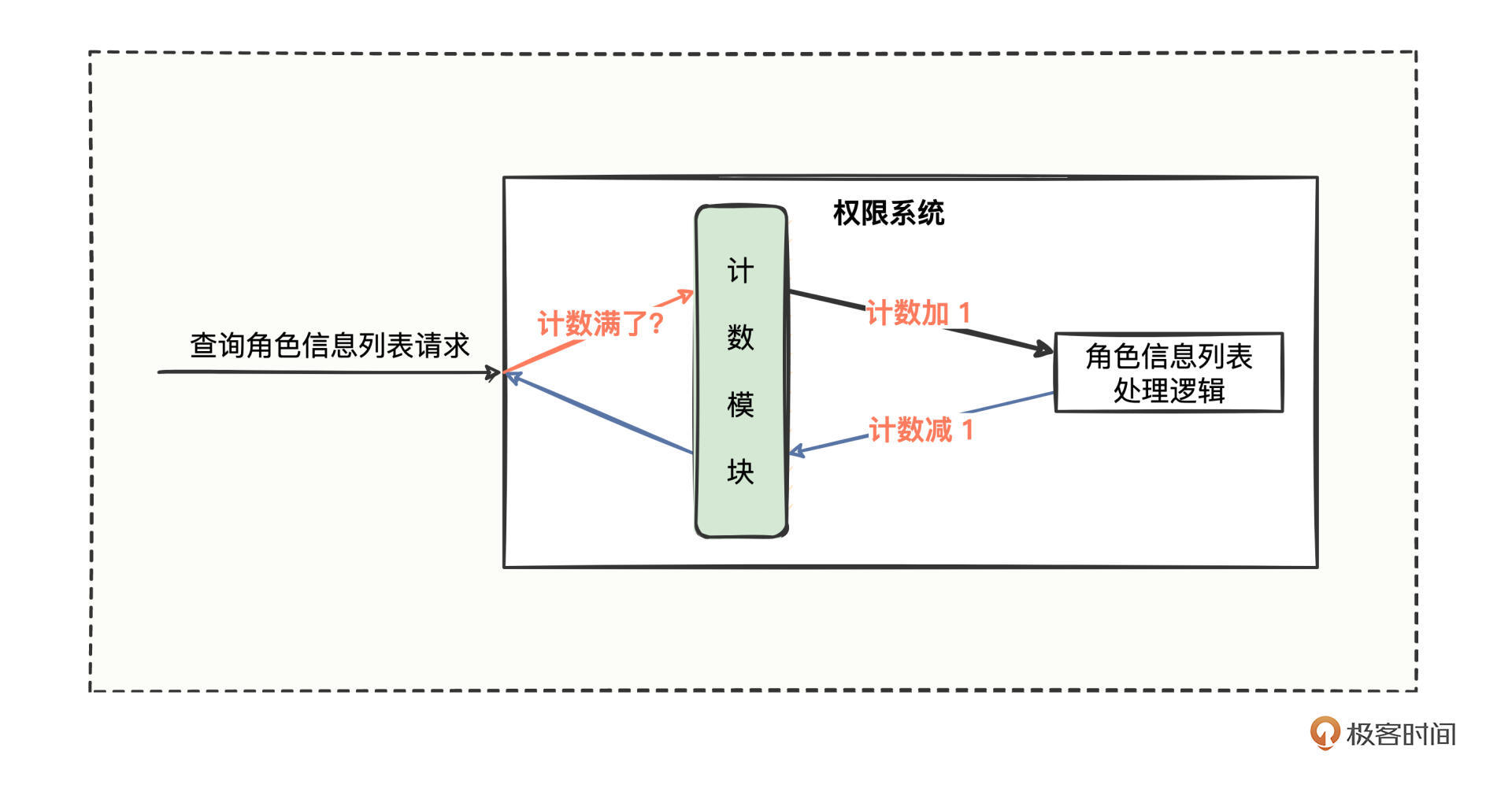
查询请求进入权限系统后,正常情况是先经过计数模块,计数模块进行加1操作,再去处理业务逻辑,待业务逻辑处理后返回,再进行计数减1操作。如果请求进来时,计数模块发现实时容量已满,就拒绝或等待。
计数模块核心逻辑:
使用拦截器,来进行统一计数处理。
考虑多线程情况,我们使用ConcurrentMap + AtomicInteger 来进行加减操在,以服务名 + 方法名作为key,value是当前接口使用次数,ConcurrentMap保证同一个key在并发操作时线程安全,AtomicInteger保证原子性的加减计数。
对服务提供方的改造主要有以下几点:
- 定义一个自定义计数器,设置为主要在提供方生效。
- 定义qps.enable、qps.value 两个方法级别的参数,qps.enable 参数主要表示是否开启流量控制,qps.value 参数主要表示流量的标准容量上限值
- 在invoke方法中先尝试获取计数资源,如果不需要限流或者已获取计数资源,则放行,否则会抛出无法获取计数资源的运行时异常。
- 在invoke的finally代码块中处理释放计数资源的逻辑。
- 在提供方的@DubboService 注解中,为方法增加了 qps.enable=true、qps.value=3 两个配置,来应用我们刚刚写的限流过滤器。
2.分布式限流
分布式是集群部署,单机模式那样限流也不是不行,只是不是最优解,我们需要考虑有少部分机器宕机的情况下总的QPS不变。
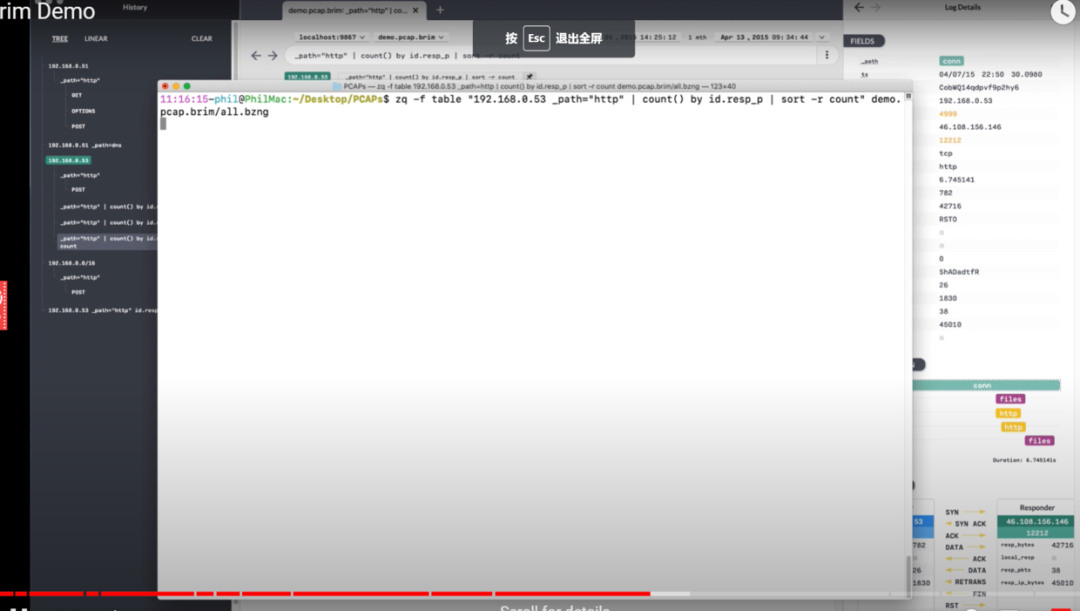
分布式我们就不能在每台机器的JVM内存中控制流量,需要把计数信息存放在第三方。这个第三方要可以缓存,可以进行计算,操作的效率也要相对较高,这里就推荐Redis。
引入Redis来保存接口访问计数之后,对之前的限流逻辑进行改造:
- 新增qps.type方法级别参数,主要表示处理限流的工具,有jlimit、rlimit两种,jlimit表示采用JVM限流,rlimit表示采用Redis限流,不配置的情况默认为JVM限流。
- 根据qps.type不同的值需要用不同的工具进行限流处理,这里采用了Map结果引入策略模式来做分发,并把策略模式应用到invoke方法的主体逻辑。
- 新增了一套关于Redis的计数累加、计数核减的逻辑实现。
- 在提供方的 @DubboService 注解中,继续为方法增加了 qps.type=redis 的配置,表示需要使用分布式限流。
以上只是实现思路,代码实现还得实操,动手实现一下才能更好的掌握。
限流在我们业务场景中的应用:
- 合法性限流,比如验证码攻击、恶意爬虫、恶意请求参数、利用限流有效拦截这些恶意请求。
- 业务限流,合理地评估功能的并发支撑能力。
- 网关限流,防止爆发流量对网关的冲击
- 连接数限流,比如利用线程池的数量来控制流量
学习来源:极客时间