目录
聚簇索引,二级索引,MRR,联合索引和自适应哈希索引-详细总结
聚簇索引
定义:
问题:为什么不采用B树作为MySQL表数据底层的存储数据结构?
作图:
问题:如果数据库表没有设置主键字段怎么去构建聚簇索引?
问题:为什么要引出二级索引(辅助索引)?
二级索引
定义:
作图:
回表
问题:为什么会发生回表操作?
问题:为什么可以发送回表操作?
问题:回表操作性能高吗?
问题:为什么回表操作是随机I/O操作?
问题:Explain select * from test where name='leomessi' (表具有以name字段创建的二级索引) ,但是最终没有选择走索引而是选择走聚簇索引的全表扫描?
MRR
问题:什么是MRR?为什么要引出MRR?
联合索引
定义
自适应哈希索引
问题:为什么使用自适应哈希索引?
问题:自适应哈希索引的并发问题
问题:自适应哈希索引效率这么高,为什么底层不直接采用自适应哈希索引?
自适应哈希索引底层和JDK的hashmap差不多。
问题:InnoDB引擎的三大特性:
聚簇索引,二级索引,MRR,联合索引和自适应哈希索引-详细总结
聚簇索引
定义:
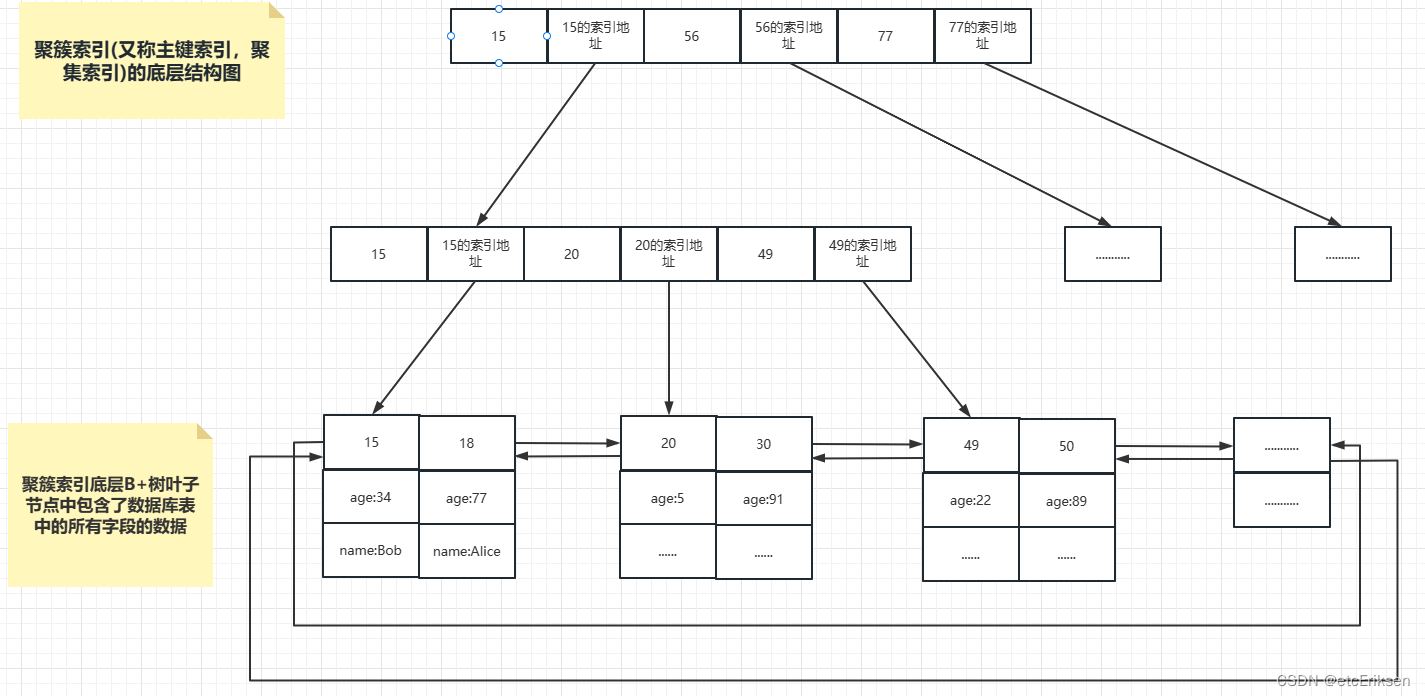
(1) 聚簇索引又称聚集索引,主键索引
(2) 根据表的主键字段进行构建出一棵B+树,并且将整张数据库表的数据记录存放到该B+树的叶子节点里。
(3) 对于B+树的非叶子节点存储的是各个主键字段的地址,目的是为了可以利用二分法进行搜索,进而达到快速检索的效果(快速检索就是索引的本质)。
问题:为什么不采用B树作为MySQL表数据底层的存储数据结构?
对于B树而言,非叶子节点不仅会存储表字段地址也会进行存储字段的数据,这样每一个页可以存储的总字段数就会减少。这样二分查询的效率会下降。具体见:《MySQL调优-深入理解MySQL索引底层数据结构与算法》中B树和B+树解析
作图:
问题:如果数据库表没有设置主键字段怎么去构建聚簇索引?
首先如果表没有设置主键字段,那么先会搜索表中是否有唯一索引字段。
如果有,那么就使用该字段作为主键字段。
如果没有,数据库就会搜索是否存在对于每行记录某个字段的值都是唯一的?
如果有,那么就使用该字段作为主键字段。
如果没有,MySQL数据库就会自己创建一个rowid虚拟列作为主键字段。
总之,最好自己就给每一个表设置一个主键字段,一定不要把设置主键字段的任务交给MySQL数据库,是会很大程度的消耗数据库的性能的!
问题:为什么要引出二级索引(辅助索引)?
因为聚簇索引底层B+数据结构的叶子节点中是存储着表的所有数据的,所以使用聚簇索引查询起来是十分慢的,因为我们每一次读取都需要把整颗树读取到磁盘,都是一次I/O操作。所以为了提升查询的效率,我们引出了二级索引(辅助索引)。
二级索引
定义:
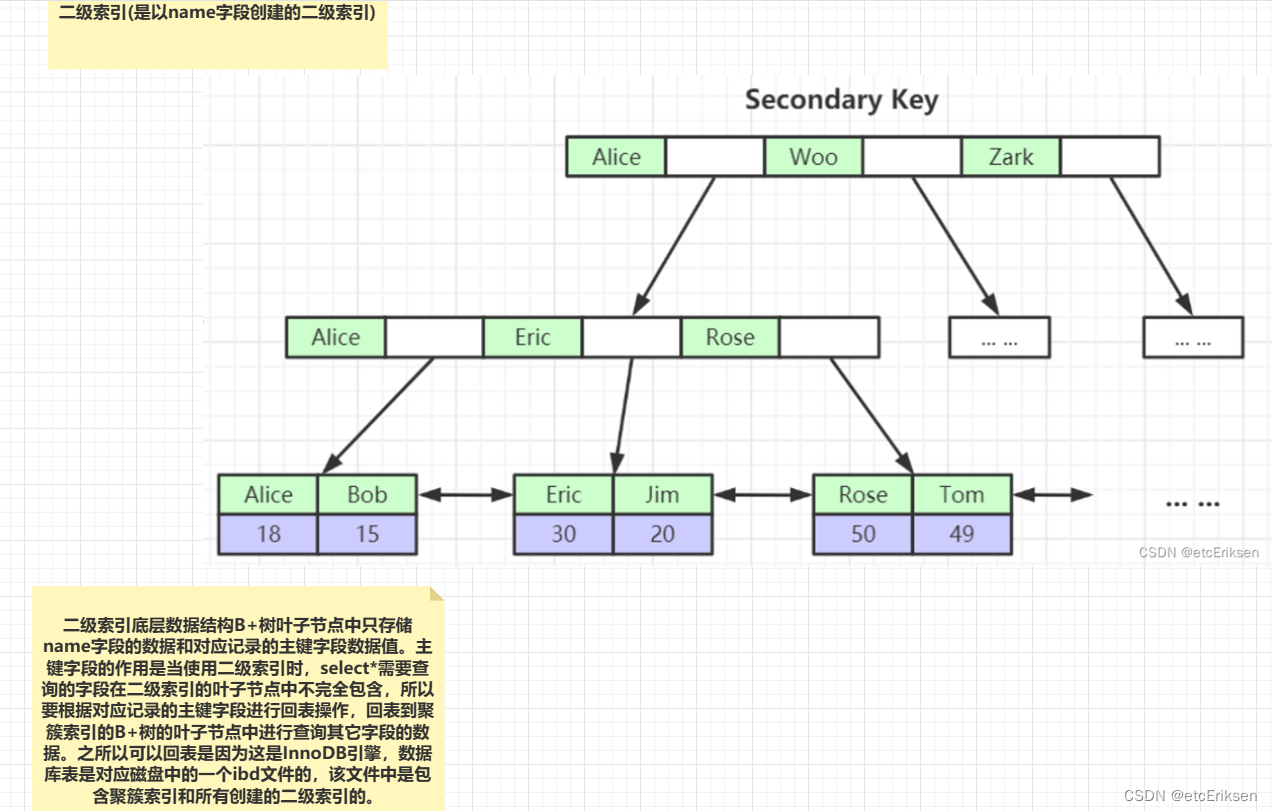
(1) 二级索引是以某一个字段作为构建整棵树的依据。比如说:构建name字段的二级索引,那么"某一个字段"对应的即是name字段
(2) 非叶子节点中存储的是该二级索引对应的字段的地址,同样是为了之后使用该索引进行二分查询时的迅速。
(3) 叶子节点中的存储:首先按照顺序排列进行存储该索引对应索引字段的所有数据,然后再在每一条字段数据的后面进行存储对应的主键字段的数据
作图:
回表
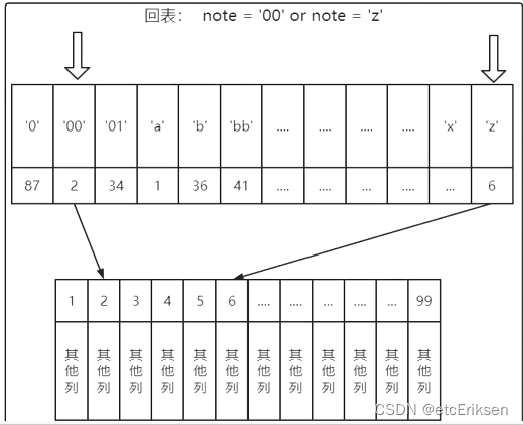
问题:为什么会发生回表操作?
当使用二级索引时,select *(*标识需要查询所有字段),但是需要查询的字段数据在二级索引的叶子节点中不完全包含,所以要根据叶子节点中对应记录的主键字段进行回表操作,回表到聚簇索引的B+树的叶子节点中进行查询其它字段的数据。
问题:为什么可以发送回表操作?
之所以可以回表是因为这是InnoDB引擎,数据库表是对应磁盘中的一个ibd文件的,该ibd文件的数据是包含聚簇索引和所有创建的二级索引的。因为索引都是在同一个ibd文件中的,所以我们可以进行回表操作。
问题:回表操作性能高吗?
不高。回表操作是一种随机I/O操作,效率是极低的,顺序I/O效率要比随机I/O读写的效率高出好几个数据量,大概是几千倍。所以回表操作效率极低!
问题:为什么回表操作是随机I/O操作?
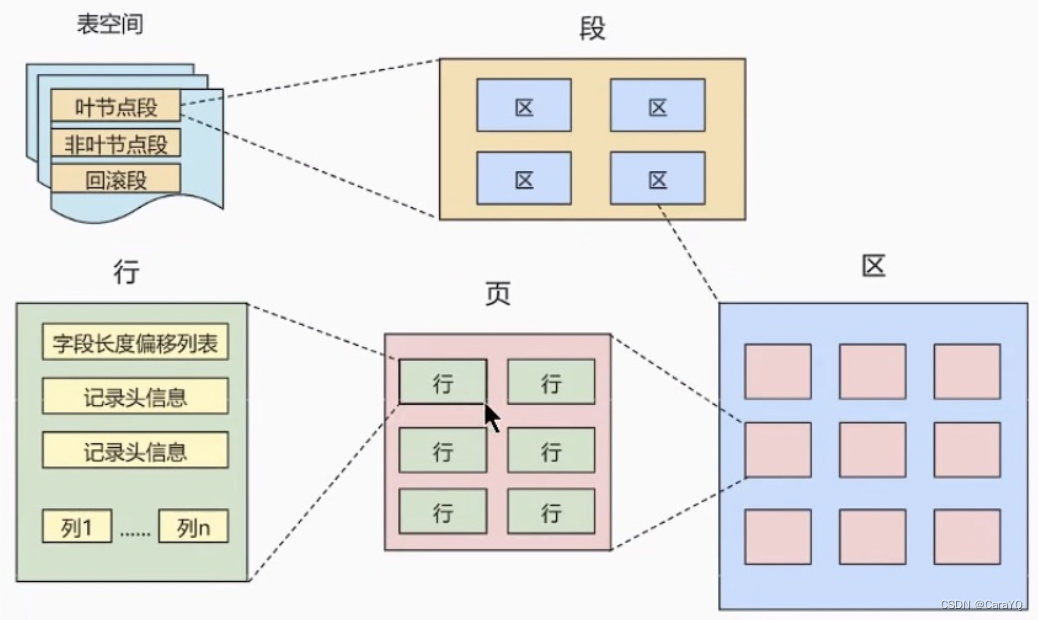
(1) I/O读写分为随机I/O和顺序I/O。
(2) 先看一张图:
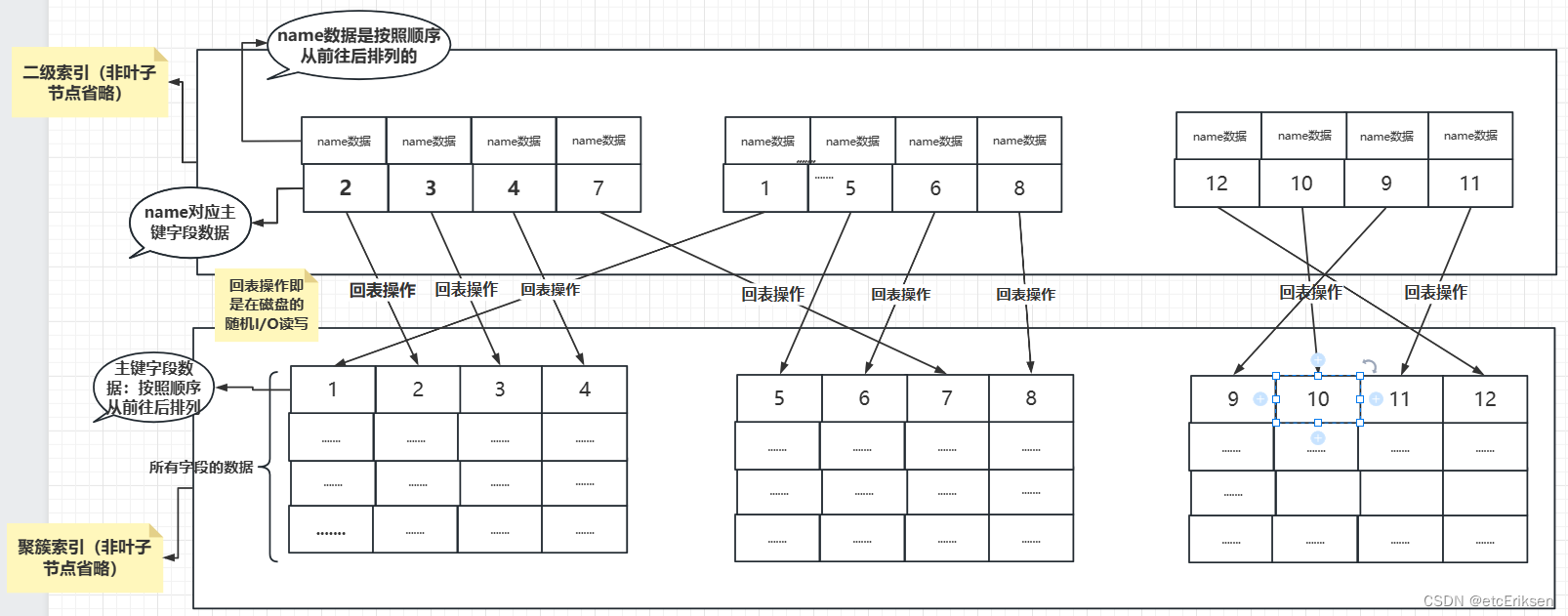
(3) 对于二级索引来说,整棵B+树就是以name字段为地址索引构建的,所以叶子节点中的name字段是按照数据大小从前往后排列的,但是name字段对应的主键id字段不是按照顺序排列的,是乱序的。
对于主键索引(聚簇索引)来说,整棵B+树就是以主键字段为地址索引构建的,所以叶子节点中的主键字段是按照数据大小从前往后排列的。
(4) 所以当我们进行回表操作时,二级索引的叶子节点的主键字段找聚簇索引中对应的主键字段。举一个例子:我们依次对主键id:2,3,4,7,1进行回表,但是2,3,4对应的数据记录是在一个数据页1中,然而7对应的数据记录在数据页2中,但是到1的时候,它又变成到数据页1中。这就是随机性。我们每一次读取都是一次随机的,所以称之为随机I/O读写。
(5) 随机I/O读写的效率是极低的,为什么呢?
磁盘读取数据页不是说一下子把所有数据页都读取进磁盘中的,而是进行扇形读取的,磁盘一次只可以读取512个字节,所以一个16KB大小的数据页需要磁盘读取32次。因此这么多数据页一共要读取许多许多次。
视觉回到(4),回表操作是,假设说回表主键字段7时需要磁盘32次读取一个数据页,但是回表主键字段1时又要磁盘32次读取另外一个数据页,这样效率太低了。
我们知道一个数据页中是包含很多主键字段数据的。这样每一个主键字段回表就需要磁盘读取一个数据页,这样的话随机I/O太频繁,效率太低了!
所以后面会使用MRR优化,把主键字段按照从小到大顺序排序,好处就是减少随机I/O读写。具体效果就是:我们回表多个主键字段只需要磁盘读取一个数据页!极大的提升性能。
问题:Explain select * from test where name='leomessi' (表具有以name字段创建的二级索引) ,但是最终没有选择走索引而是选择走聚簇索引的全表扫描?
easy。
因为select *中,*标识的是查询test表中的所有数据记录。但是对于name字段的二级索引来说,底层B+树的叶子节点中只存储了name字段的数据以及对应主键字段的数据。所以二级索引不可以查询到select *需求的所有字段的数据。
因此要进行回表,但是回表操作对应的是随机I/O读写,经过MySQL底层的计算,得出回表操作导致的随机I/O读写消耗的性能要比直接走聚簇索引按照顺序从前往后依次扫描消耗的性能要多!那么最终就会选择走聚簇索引的全局扫描。
MRR
问题:什么是MRR?为什么要引出MRR?
MRR是一种优化措施。MRR是对二级索引进行回表操作时的优化措施。
具体优化方式:
前置知识: 对于二级索引来说,整棵B+树就是以name字段为地址索引构建的,所以叶子节点中的name字段是按照数据大小从前往后排列的,但是name字段对应的主键id字段不是按照顺序排列的,是乱序的。
由于二级索引对应保存的主键字段是随机乱序的,但是聚簇索引的主键字段是从小到大顺序排列的。所以回表时是随机I/O操作。
MRR的作用即是:
对二级索引的随机乱序的主键字段进行顺序排序,让乱序变为如聚簇索引一样按照从小到大顺序排列,这样回表操作时就可以大大降低随机I/O的次数,极大的提升了性能。
但是MRR对主键字段进行排序不也消耗性能吗?
MRR对主键字段进行排序操作是发生在CPU的,排序的效率要比随机读写高出很多的!效率高出好多个数量级。
联合索引
定义
前面我们对索引的描述,隐含了一个条件,那就是构建索引的字段只有一个,但实 践工作中构建索引的完全可以是多个字段。所以,将表上的多个列组合起来进行索 引我们称之为联合索引或者复合索引,比如index(a,b)就是将a,b两个列组合起来 构成一个索引。
千万要注意一点,建立联合索引只会建立1棵B+树,多个列分别建立索引会分别以 每个列则建立B+树,有几个列就有几个B+树,比如,index(note)、index(b),就 分别对note,b两个列各构建了一个索引。
index(note,b)这个以note和b字段构建的联合索引,在索引构建上,包含了两个意思: 1、先把各个记录按照note列进行排序。 2、在记录的note列相同的情况下,采用b列进行排序
举个例子:
如图:a是按照从小到大顺序进行排列的,在a排序完成的基础上,b再进行按照顺序依次进行排序。c是在a和b都排序完成的基础上,进行依次排序的。d是在a和b和c都排序完成的基础上,进行依次排序的。

自适应哈希索引
问题:为什么使用自适应哈希索引?
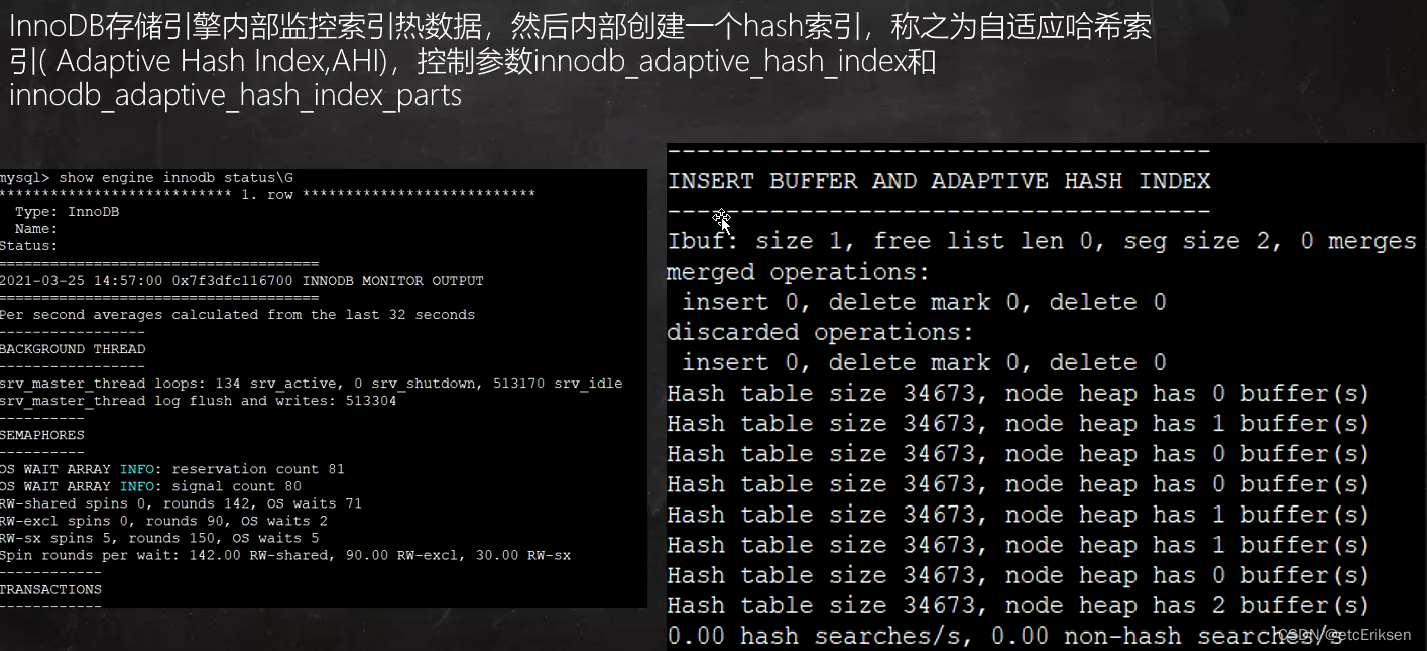
因为InnoDB存储引擎内部进行监控整个B+树,可能某一个索引对应的数据被大量访问,该索引对应的数据称之为热数据。对于该热数据,MySQL会给它进行分配一个自适应哈希索引,相当于缓存但是和redis又不同(不同之处体现在并发问题上,后面详细记录)。当下一次再来进行访问这个热数据时,直接通过自适应哈希索引锁定到该热数据。
问题:自适应哈希索引的并发问题
在并发多线程的场景下,自适应哈希好像是缓存,但是和Redis这种缓存又不一样,对于Redis内部的读取,无论如何读取都是一个单线程,对于MySQL的自适应哈希内部是多线程处理的。
在MySQL 5.7中,自适应哈希索引搜索系统被分区。每个索引都绑定到一个特定的分区,每个分区都由一个单独的 latch 锁保护。分区由 innodb_adaptive_hash_index_parts 配置选项控制 。在早期版本中,自适应哈希 索引搜索系统受到单个 latch 锁的保护,这可能成为繁重工作负载下的争用点。 innodb_adaptive_hash_index_parts 默认情况下,该 选项设置为8。最大设置为 512。当然禁用或启动此特性和调整分区个数这个应该是DBA的工作,我们了解即可。
问题:自适应哈希索引效率这么高,为什么底层不直接采用自适应哈希索引?
很easy,因为自适应哈希索引不支持范围查询的。
了解哈希表底层的都应该明白一点,进行hash计算后得到的key键值是随机的,所以数据value值是分布随机的,所以范围查询是不支持的,只支持特定值直接锁定!
自适应哈希索引底层和JDK的hashmap差不多。
(1) 定位使用的是除法
(2) 存储的时候如果出现了哈希冲突,使用链表。但是无红黑树,使用的结构是:数组+链表的存储形式。
问题:InnoDB引擎的三大特性:
(1) 双写缓冲区
(2) buffer pool
(3) 自适应哈希索引