文章目录
- @[toc]
- 前言
- 1. Base64编码原理
- 2. 加解密图示
- 3. base64编码Code
- 3. base64url编码Code
文章目录
- @[toc]
- 前言
- 1. Base64编码原理
- 2. 加解密图示
- 3. base64编码Code
- 3. base64url编码Code
前言
一个字节可以表示256种数值,但是由于一些字节在网络中有特殊的含义。所以当传输字节内容时就不能传输这些具有控制功能的字符。具体的做法就是将这些字符进行转码。
ASCII中0x20 ~ 0x7E是可打印字符,所以可以将要传输的字符转码为这个范围内的字符。
base64编码就是将255种字节转换为64种进行传输;
base64url编码也是将255种字节转换为64种进行传输,与base64选择的字符稍有不同.
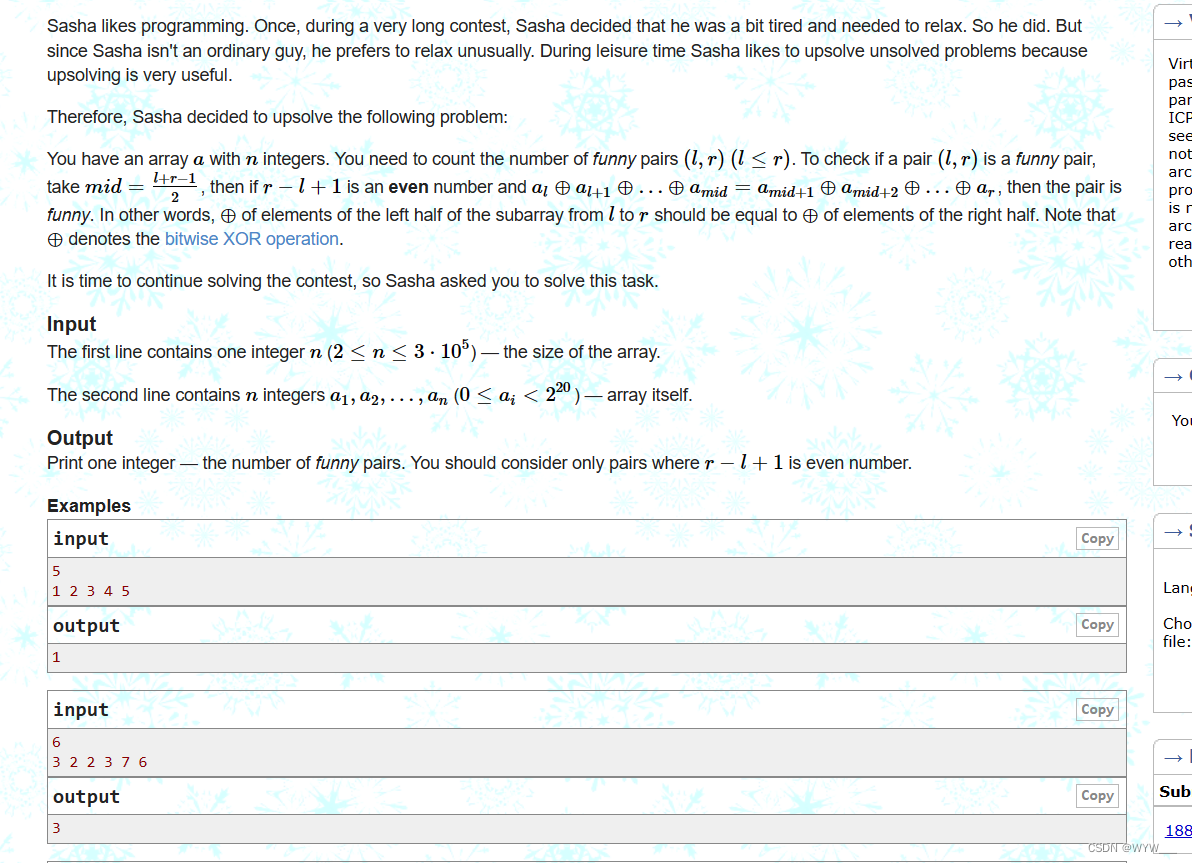
1. Base64编码原理
base64编码的原理就是:将原来的3个字节变成4个字节.
将3个字节(共24位)变成4个字节后,每个字节只有6bit有效,6bit所能表示的字符正好是64个。这也正式base64名字的由来。
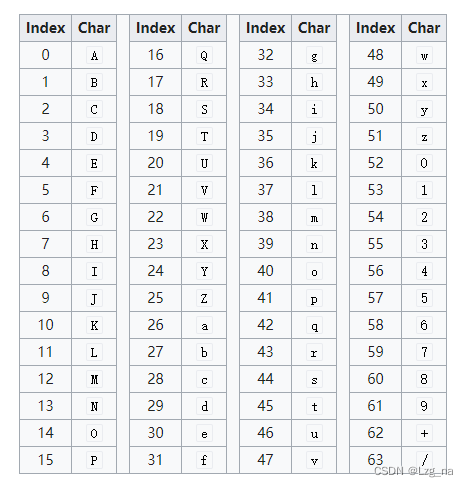
编码后的64个数字和A对应的SCII字符如下表:
2. 加解密图示
加密和解密其实就是将字符bit拆分和重组的过程.

既然编码原理是将3个字节拆分为4个字节,那么就肯定需要编码前总的字节数是3的倍数,这样编码后的内容才会是4的倍数,不是3的倍数时应该怎么办?
编码前可以不是3的倍数,但编码后需要是4的倍数。解决办法:给编码后的内容补充’==’
所以编码后的内容总是4的倍数,且字符串中的字符一定在上面的64个字符的范围内,且在末尾有且可能最多存在两个'='.
3. base64编码Code
const unsigned char Base64EncodeMap[64] =
{
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/'
};
unsigned int base64encode(char *dst, const char *src, unsigned int len_src)
{
unsigned int i;
char *p;
if(len_src<4)
{
return 0;
}
p = dst;
/* 将三个字节转换为4个字节 */
for (i = 0; i < len_src - 2; i += 3) {
*p++ = basis_64[(src[i] >> 2) & 0x3F];//第一个
*p++ = basis_64[((src[i] & 0x3) << 4) |
((int) (src[i + 1] & 0xF0) >> 4)];//第二个
*p++ = basis_64[((src[i + 1] & 0xF) << 2) |
((int) (src[i + 2] & 0xC0) >> 6)];//第三个
*p++ = basis_64[src[i + 2] & 0x3F];//第四个
}
/*处理剩余的字节编码*/
if (i < len_src) {
*p++ = basis_64[(src[i] >> 2) & 0x3F];
if (i == (len_src - 1)) {
*p++ = basis_64[((src[i] & 0x3) << 4)];
*p++ = '=';
}
else {,
*p++ = basis_64[((src[i] & 0x3) << 4) |
((int) (src[i + 1] & 0xF0) >> 4)];
*p++ = basis_64[((src[i + 1] & 0xF) << 2)];
}
*p++ = '=';
}
*p++ = '\0';
return p - dst;
}
从代码中可以看出Base64EncodeMap的作用就是:
- 将转换后生成的0-63数值映射成
表里的字符。如果编码后的数值为0,那么最终转换成的字符为A。如果编码后的数值为1,那么最终转换成的字符为B。