目录
- 一、创建索引
- 1、创建索引
- 2、通过索引查询
- 二、复合索引
- 三、索引内嵌文档
- 四、索引基数
- 五、explain
- 六、为何不使用索引
- 七、固定集合
一、创建索引
1、创建索引
> db.student.createIndex({"name":1})
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}
2、通过索引查询
> db.student.find({"name":"哪吒"}).explain("executionStats"))
{
"explainVersion" : "1",
"queryPlanner" : {
"namespace" : "test.student",
"indexFilterSet" : false,
"parsedQuery" : {
"name" : {
"$eq" : "哪吒"
}
},
"maxIndexedOrSolutionsReached" : false,
"maxIndexedAndSolutionsReached" : false,
"maxScansToExplodeReached" : false,
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"name" : 1
},
"indexName" : "name_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"name" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"name" : [
"[\"哪吒\", \"哪吒\"]"
]
}
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 0,
"executionTimeMillis" : 16,
"totalKeysExamined" : 0,
"totalDocsExamined" : 0,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 0,
"executionTimeMillisEstimate" : 13,
"works" : 1,
"advanced" : 0,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"docsExamined" : 0,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 0,
"executionTimeMillisEstimate" : 13,
"works" : 1,
"advanced" : 0,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"keyPattern" : {
"name" : 1
},
"indexName" : "name_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"name" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"name" : [
"[\"哪吒\", \"哪吒\"]"
]
},
"keysExamined" : 0,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0
}
}
},
"command" : {
"find" : "student",
"filter" : {
"name" : "哪吒"
},
"$db" : "test"
},
"serverInfo" : {
"host" : "DESKTOP-HU0H0AI",
"port" : 27017,
"version" : "5.0.14",
"gitVersion" : "1b3b0073a0b436a8a502b612f24fb2bd572772e5"
},
"serverParameters" : {
"internalQueryFacetBufferSizeBytes" : 104857600,
"internalQueryFacetMaxOutputDocSizeBytes" : 104857600,
"internalLookupStageIntermediateDocumentMaxSizeBytes" : 104857600,
"internalDocumentSourceGroupMaxMemoryBytes" : 104857600,
"internalQueryMaxBlockingSortMemoryUsageBytes" : 104857600,
"internalQueryProhibitBlockingMergeOnMongoS" : 0,
"internalQueryMaxAddToSetBytes" : 104857600,
"internalDocumentSourceSetWindowFieldsMaxMemoryBytes" : 104857600
},
"ok" : 1
}
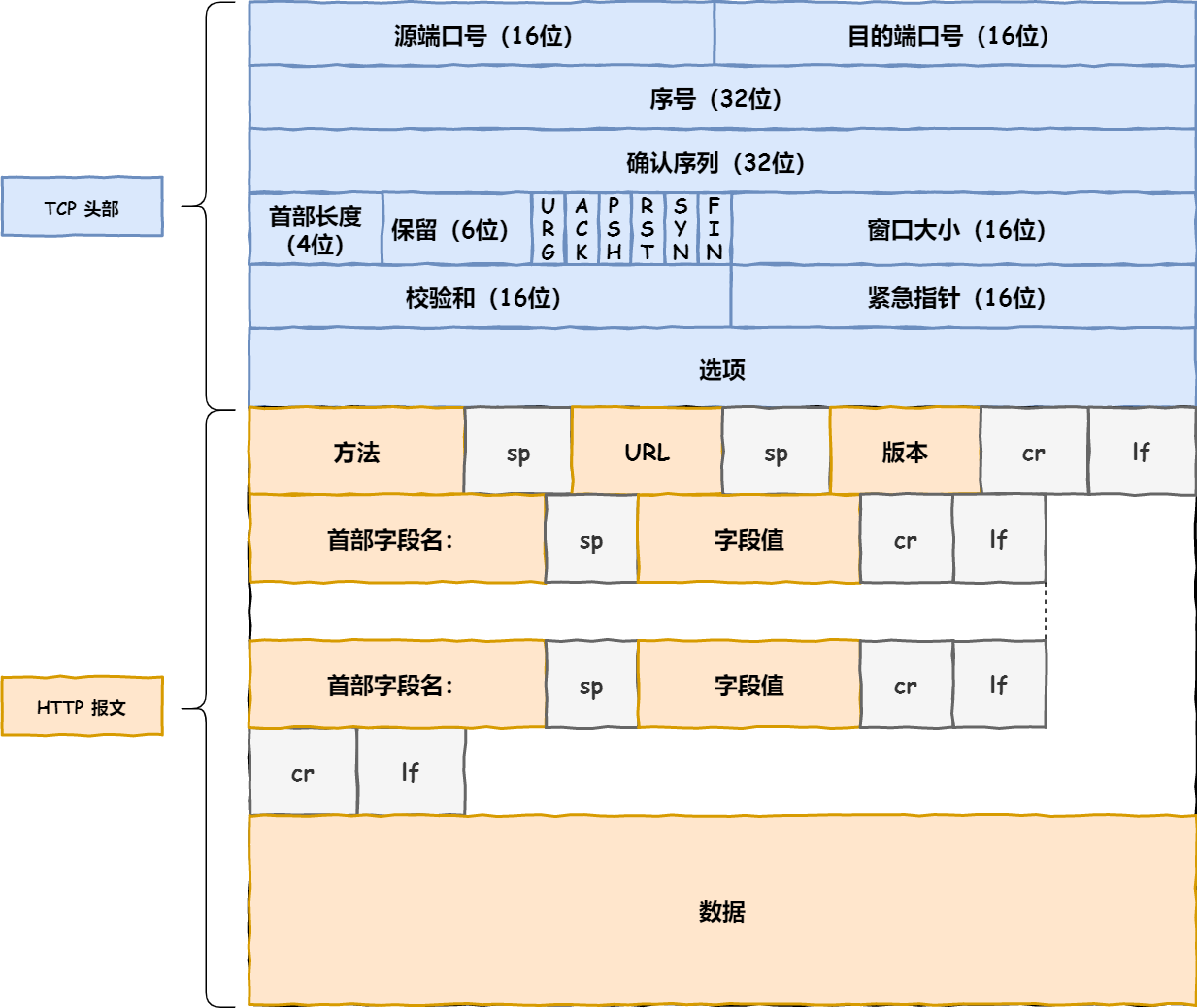
explain()返回值含义一览:
queryPlanner(查询计划):查询优化选择的计划细节和被拒绝的计划。其可能包括以下值:
queryPlanner.namespace-一个字符串,运行查询的指定命名空间
queryPlanner.indexFilterSet-一个布尔什,表示MongoDB在查询中是否使用索引过滤
queryPlanner.winningPlan-由查询优化选择的计划文档 winningPlan.stage-表示查询阶段的字符串
winningPlan.inputStage-表示子过程的文档 winningPlan.inputStages-表示子过程的文档数组
queryPlanner.rejectedPlans-被查询优化备选并被拒绝的计划数组
executionStats,(执行状态):被选中执行计划和被拒绝执行计划的详细说明:
queryPlanner.nReturned-匹配查询条件的文档数
queryPlanner.executionTimeMillis-计划选择和查询执行所需的总时间(毫秒数)
queryPlanner.totalKeysExamined-扫描的索引总数
queryPlanner.totalDocsExamined-扫描的文档总数
queryPlanner.totalDocsExamined-扫描的文档总数
queryPlanner.executionStages-显示执行成功细节的查询阶段树
executionStages.works-指定查询执行阶段执行的“工作单元”的数量
executionStages.advanced-返回的中间结果数
executionStages.needTime-未将中间结果推进到其父级的工作周期数
executionStages.needYield-存储层要求查询系统产生的锁的次数
executionStages.isEOF-指定执行阶段是否已到达流结束
queryPlanner.allPlansExecution-包含在计划选择阶段期间捕获的部分执行信息,包括选择计划和拒绝计划
serverInfo,(服务器信息):MongoDB实例的相关信息: serverInfo.winningPlan-使用的执行计划
winningPlan.shards-包括每个访问片的queryPlanner和serverInfo的文档数组
索引可以显著缩短查询时间,但是,使用索引也是有代价的,索引字段的增删改操作会花费更长时间,因为在更改数据时,除了更新文档数据,MongoDB还必须更新索引。这个和关系型数据库是一样的。MongoDB的索引机制和关系型数据库的索引机制大同小异。
要选择为哪些字段建索引,可以查看常用的查询以及那些需要快速执行的查询。
二、复合索引
在两个或者多个键上创建索引是必须的,索引会将其所有值按顺序保存,因此按照索引键对文档进行排序的速度要快得多。
> db.student.createIndex({"name":1,"age":1}) ")
{
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"createdCollectionAutomatically" : false,
"ok" : 1
}
符合索引使MongoDB能够高效地执行具有多个子句的查询。当设计基于多个字段的索引时,应该讲用于精确匹配的字段放在最前面,用于范围匹配的字段放在最后面。这样就可以先用第一个索引键进行精确匹配,然后再用第二个索引范围在这个结果集内部进行搜索。
三、索引内嵌文档
MongoDB允许深入文档内部,对内嵌字段和数组创建索引。内嵌对象和数组字段可以和顶级字段一起在符合索引中使用。
可以在内嵌文档的键上创建索引,方法与在普通键上创建索引相同。
在info中的address字段上建立索引。对子文档创建索引,只有进行与子文档字段顺序完全匹配的查询时,查询优化器才能使用"address"上的索引。
> db.teacher.find() 新园区"}})
{ "_id" : ObjectId("638ca288e96330d24f819182"), "id" : "1", "name" : "哪吒编程", "info" : { "id" : 1, "level" : "1", "address" : "大连市高新园区" } }
{ "_id" : ObjectId("638ca288e96330d24f819183"), "id" : "2", "name" : "云韵", "info" : { "id" : 2, "level" : "1", "address" : "北京市" } }
{ "_id" : ObjectId("638ca288e96330d24f819184"), "id" : "3", "name" : "萧炎", "info" : { "id" : 3, "level" : "2", "address" : "沈阳市青年大街" } }
{ "_id" : ObjectId("638ca289e96330d24f819185"), "id" : "4", "name" : "美杜莎", "info" : { "id" : 4, "level" : "3", "address" : "上海市浦项道" } }
{ "_id" : ObjectId("638ca28ae96330d24f819186"), "id" : "5", "name" : "雅妃", "info" : { "id" : 5, "level" : "2", "address" : "深圳市中山路" } }
> db.teacher.createIndex({"info.address":1})
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}
四、索引基数
基数是指集合中某个字段有多少个不同的值。
通常来说,一个字段的基数越高,这个字段上的索引就越有用。这是因为这样的索引能够迅速将搜索范围缩小到一个比较小的结果集。对于基数比较低的字段,索引通常无法排除大量可能的匹配项。
五、explain
对于慢查询而言,explain 是最重要的诊断工具之一,通过explain可以了解查询都使用了哪些索引以及是如何使用的。对于任何查询,都可以在末尾添加一个explain进行查询分析。
六、为何不使用索引
索引在提取较小的子数据集时是最高效的,而有些查询在不使用索引时会更快。
结果集在原集合中所占的比例越大,索引就会越低效,因为使用索引需要进行两次查找:一次是查找索引项,一次是根据索引的指针区查找其指向的文档。而全表扫描只需进行一次查找:查找文档。在最坏的情况下(返回集合内的所有文档),使用索引进行查找的次数会是全表扫描的两倍,通常会明显比全表扫描慢。
七、固定集合
对于固定大小的集合,当我们向已经满了的固定集合中插入数据时,文档中最旧的文档会被删除,固定集合不允许进行会导致集合大小变化的操作,固定集合中的文档以插入顺序进行存储,并且不需要为已删除文档的空间维护空闲列表。
与MongoDB中的大部分集合不同,固定集合的访问模式是数据被顺序写入磁盘上的固定空间,这让它们在机械硬盘上的写入速度非常快,尤其是当集合拥有专有的磁盘时。
通常来说,对于固定集合,MongoDB优先推荐使用TTL索引,因为它们在WiredTiger存储引擎中性能更好。TTL索引会基于日期类型字段的值和索引的TTL值而过期,并从普通集合中删除数据。
TTL索引允许为每一个文档设置一个超时时间,当一个文档达到其预设的过期时间之后就会被删除。为了防止活跃的会话被删除,可以在会话上有活动发生时,将lastUpdated字段更新为当前时间。

Java学习路线总结,搬砖工逆袭Java架构师
10万字208道Java经典面试题总结(附答案)
Java基础教程系列
Java高并发编程系列
数据库进阶实战系列
.