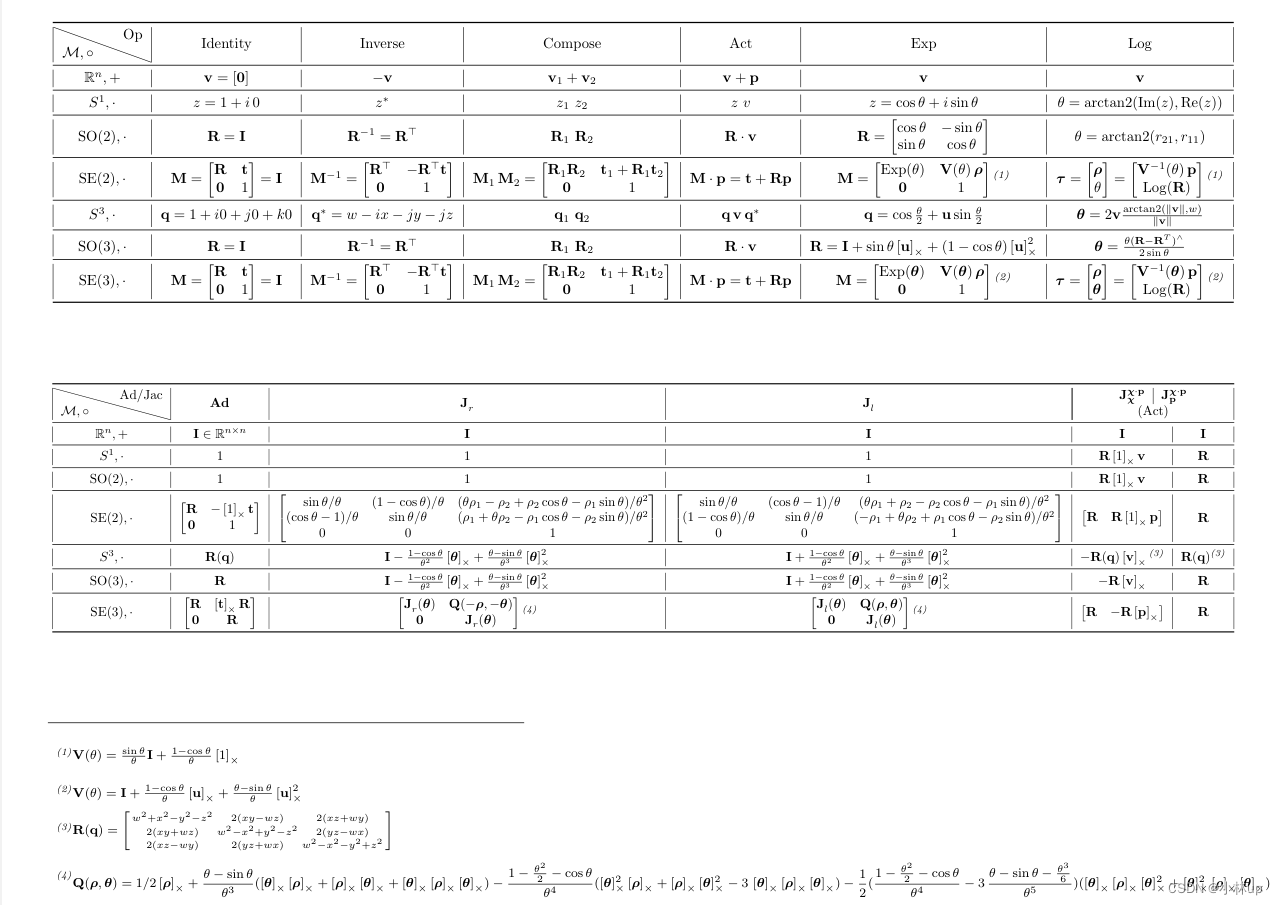
总言
两次作业汇报:其一。
文章目录
- 总言
- 1、作业一:
- 1.1 、任务一:各项数据建立
- 1.2 、任务二:去除缺失值
- 1.3 、任务三:返回性别为女生,年龄<20的学生及成绩
- 1.4、 任务四:统计性别为女生,年龄<20,成绩>90的学生姓名、总人数
- 1.5 、任务五:重新按照上述方法构建数据框,包含学生姓名,期中成绩两列
- 1.6、 任务六:将上述数据框同有学生信息合并构建新的数据框
- 1.7、 任务七:对新的数据框按照期末升序,期中降序排列
1、作业一:

1.1 、任务一:各项数据建立
1)、创建100个学生名称
思路:
①由于需要我们自己创建数据,而题目要求100位学生,如果手动直接输入会很费时,如果能一次性形成多个值就比较高效。
②其次,要考虑学生姓名,假如直接随机生成100个纯数值以充当学生姓名,容易造成数据上的概念模糊,而假如直接使用汉字、字符串等,26个英文字母重组不便于编号整理。
③因此,此处选择了以下方式创建学生名称:使用paste函数将字符型向量和数值型向量组合。
> c1=("学生");
> c2=(1:100);
> studentnames<-paste(c1,c2,sep="");
> studentnames
[1] "学生1" "学生2" "学生3" "学生4" "学生5" "学生6" "学生7" "学生8"
[9] "学生9" "学生10" "学生11" "学生12" "学生13" "学生14" "学生15" "学生16"
[17] "学生17" "学生18" "学生19" "学生20" "学生21" "学生22" "学生23" "学生24"
[25] "学生25" "学生26" "学生27" "学生28" "学生29" "学生30" "学生31" "学生32"
[33] "学生33" "学生34" "学生35" "学生36" "学生37" "学生38" "学生39" "学生40"
[41] "学生41" "学生42" "学生43" "学生44" "学生45" "学生46" "学生47" "学生48"
[49] "学生49" "学生50" "学生51" "学生52" "学生53" "学生54" "学生55" "学生56"
[57] "学生57" "学生58" "学生59" "学生60" "学生61" "学生62" "学生63" "学生64"
[65] "学生65" "学生66" "学生67" "学生68" "学生69" "学生70" "学生71" "学生72"
[73] "学生73" "学生74" "学生75" "学生76" "学生77" "学生78" "学生79" "学生80"
[81] "学生81" "学生82" "学生83" "学生84" "学生85" "学生86" "学生87" "学生88"
[89] "学生89" "学生90" "学生91" "学生92" "学生93" "学生94" "学生95" "学生96"
[97] "学生97" "学生98" "学生99" "学生100"
当然我们也可以像学号一样使用一串位数相同且具有连续性的数字来表示学生编号。
> student<-c(2019210001:2019210100);
> student
[1] 2019210001 2019210002 2019210003 2019210004 2019210005 2019210006 2019210007
[8] 2019210008 2019210009 2019210010 2019210011 2019210012 2019210013 2019210014
[15] 2019210015 2019210016 2019210017 2019210018 2019210019 2019210020 2019210021
[22] 2019210022 2019210023 2019210024 2019210025 2019210026 2019210027 2019210028
[29] 2019210029 2019210030 2019210031 2019210032 2019210033 2019210034 2019210035
[36] 2019210036 2019210037 2019210038 2019210039 2019210040 2019210041 2019210042
[43] 2019210043 2019210044 2019210045 2019210046 2019210047 2019210048 2019210049
[50] 2019210050 2019210051 2019210052 2019210053 2019210054 2019210055 2019210056
[57] 2019210057 2019210058 2019210059 2019210060 2019210061 2019210062 2019210063
[64] 2019210064 2019210065 2019210066 2019210067 2019210068 2019210069 2019210070
[71] 2019210071 2019210072 2019210073 2019210074 2019210075 2019210076 2019210077
[78] 2019210078 2019210079 2019210080 2019210081 2019210082 2019210083 2019210084
[85] 2019210085 2019210086 2019210087 2019210088 2019210089 2019210090 2019210091
[92] 2019210092 2019210093 2019210094 2019210095 2019210096 2019210097 2019210098
[99] 2019210099 2019210100
2)、创建100个学生的性别,具有NA值
思路:
①在课上简单介绍过sample函数,此处我们仍旧可以使用这个函数来随机生成性别,达到快速复刻的目的。
②由于要含有NA值,一种方法是先将所有数据创建好,然后手动添加几个NA值,此处我选择了随机生成。但随机生成需要注意一个问题,NA值不限制在性别、年龄、成绩等各项中,如果直接使用sample(sex,100,replace=T),加上其它几项后,NA值所占行太分散,之后进行去除NA值的操作后,列表所剩余的行可能过少。恰好sample函数中有用于控制相关比例的参数prob,此处我们只需要控制好比例即可。
> sex=c("male","famle",NA);
> sex
[1] "male" "famle" NA
> studentsex<-sample(sex,100,replace=T,prob=c(0.4,0.5,0.1));
> studentsex
[1] "famle" "famle" "famle" "famle" "male" "male" "male" "famle" "famle" "famle"
[11] "famle" "famle" NA "male" "famle" NA "famle" "famle" "male" "famle"
[21] "male" "famle" "famle" "famle" "male" NA "famle" "male" "famle" "famle"
[31] "famle" "male" "famle" "famle" "famle" "male" "male" "male" "famle" "famle"
[41] "famle" "famle" "male" "male" "male" "male" NA "male" "famle" "famle"
[51] "famle" NA "famle" "famle" "famle" "famle" "famle" "famle" "famle" NA
[61] "famle" "famle" "male" "male" "male" NA "male" "famle" NA NA
[71] "male" "male" "famle" "famle" "male" "male" "male" "famle" "famle" NA
[81] "male" "male" "famle" "male" "famle" "male" "famle" "famle" "male" "male"
[91] "male" "male" "male" "famle" "male" "famle" "famle" "famle" "male" "famle"
3)、照猫画虎生成其它的几项数据
①年龄:此处固定在18~23之间,含NA值;
> studentages<-sample(c(18:23),size=100,replace=T);
> studentages #随机生成ages,数值类型,如果并入c(18:23,NA)会改变向量类型,因此对NA单独处理
[1] 20 18 19 22 18 22 23 19 20 18 23 18 18 18 18 18 23 18 18 20 21 18 22 19 23 22 20
[28] 19 20 20 22 23 19 18 18 18 22 20 20 22 22 20 23 18 18 19 21 21 18 20 18 21 20 23
[55] 22 22 18 18 21 19 18 20 22 20 21 18 20 18 21 20 19 23 20 19 23 21 18 20 19 18 22
[82] 21 21 19 19 21 22 18 22 18 23 20 18 18 19 23 19 21 22 20
> c<-sample(1:100,10); #用于生成随机位置的NA值,此处c为将替换NA值的下标
> c
[1] 23 90 55 86 12 88 84 26 3 83
> for(i in c){
+ studentages[i]<-NA; #遍历,将studentages中下标满足c的位置替换为NA值。
+ }
> studentages
[1] 20 18 NA 22 18 22 23 19 20 18 23 NA 18 18 18 18 23 18 18 20 21 18 NA 19 23 NA 20
[28] 19 20 20 22 23 19 18 18 18 22 20 20 22 22 20 23 18 18 19 21 21 18 20 18 21 20 23
[55] NA 22 18 18 21 19 18 20 22 20 21 18 20 18 21 20 19 23 20 19 23 21 18 20 19 18 22
[82] 21 NA NA 19 NA 22 NA 22 NA 23 20 18 18 19 23 19 21 22 20
②成绩:此处固定在60~100之间,含NA值;
> studentmarks<-sample(c(60:100),size=100,replace=T);
> studentmarks
[1] 62 68 71 89 61 82 66 74 94 61 99 97 86 98 62 86 77 64 68 93
[21] 73 96 95 68 73 81 96 94 65 83 82 95 61 64 72 90 78 71 99 99
[41] 95 65 96 93 83 71 67 79 75 75 98 76 70 73 72 87 88 73 70 70
[61] 70 76 81 88 91 75 90 83 84 95 100 75 76 74 93 88 83 83 62 72
[81] 96 81 78 99 97 76 92 94 60 68 75 65 95 94 68 85 65 81 98 71
> c<-sample(1:100,10);
> c
[1] 78 91 59 68 48 43 71 45 28 77
> for(i in c){
+ studentmarks[i]=NA;
+ }
> studentmarks
[1] 62 68 71 89 61 82 66 74 94 61 99 97 86 98 62 86 77 64 68 93 73 96 95 68 73 81 96
[28] NA 65 83 82 95 61 64 72 90 78 71 99 99 95 65 NA 93 NA 71 67 NA 75 75 98 76 70 73
[55] 72 87 88 73 NA 70 70 76 81 88 91 75 90 NA 84 95 NA 75 76 74 93 88 NA NA 62 72 96
[82] 81 78 99 97 76 92 94 60 68 NA 65 95 94 68 85 65 81 98 71
1.2 、任务二:去除缺失值
1)、生成数据框
> alldate<-data.frame(studentnames,studentsex,studentages,studentmarks);
> alldate
studentnames studentsex studentages studentmarks
1 学生1 famle 20 62
2 学生2 famle 18 68
3 学生3 famle NA 71
4 学生4 famle 22 89
5 学生5 male 18 61
6 学生6 male 22 82
7 学生7 male 23 66
8 学生8 famle 19 74
9 学生9 famle 20 94
10 学生10 famle 18 61
11 学生11 famle 23 99
12 学生12 famle NA 97
13 学生13 <NA> 18 86
14 学生14 male 18 98
15 学生15 famle 18 62
16 学生16 <NA> 18 86
17 学生17 famle 23 77
18 学生18 famle 18 64
19 学生19 male 18 68
20 学生20 famle 20 93
21 学生21 male 21 73
22 学生22 famle 18 96
23 学生23 famle NA 95
24 学生24 famle 19 68
25 学生25 male 23 73
26 学生26 <NA> NA 81
27 学生27 famle 20 96
28 学生28 male 19 NA
29 学生29 famle 20 65
30 学生30 famle 20 83
31 学生31 famle 22 82
32 学生32 male 23 95
33 学生33 famle 19 61
34 学生34 famle 18 64
35 学生35 famle 18 72
36 学生36 male 18 90
37 学生37 male 22 78
38 学生38 male 20 71
39 学生39 famle 20 99
40 学生40 famle 22 99
41 学生41 famle 22 95
42 学生42 famle 20 65
43 学生43 male 23 NA
44 学生44 male 18 93
45 学生45 male 18 NA
46 学生46 male 19 71
47 学生47 <NA> 21 67
48 学生48 male 21 NA
49 学生49 famle 18 75
50 学生50 famle 20 75
51 学生51 famle 18 98
52 学生52 <NA> 21 76
53 学生53 famle 20 70
54 学生54 famle 23 73
55 学生55 famle NA 72
56 学生56 famle 22 87
57 学生57 famle 18 88
58 学生58 famle 18 73
59 学生59 famle 21 NA
60 学生60 <NA> 19 70
61 学生61 famle 18 70
62 学生62 famle 20 76
63 学生63 male 22 81
64 学生64 male 20 88
65 学生65 male 21 91
66 学生66 <NA> 18 75
67 学生67 male 20 90
68 学生68 famle 18 NA
69 学生69 <NA> 21 84
70 学生70 <NA> 20 95
71 学生71 male 19 NA
72 学生72 male 23 75
73 学生73 famle 20 76
74 学生74 famle 19 74
75 学生75 male 23 93
76 学生76 male 21 88
77 学生77 male 18 NA
78 学生78 famle 20 NA
79 学生79 famle 19 62
80 学生80 <NA> 18 72
81 学生81 male 22 96
82 学生82 male 21 81
83 学生83 famle NA 78
84 学生84 male NA 99
85 学生85 famle 19 97
86 学生86 male NA 76
87 学生87 famle 22 92
88 学生88 famle NA 94
89 学生89 male 22 60
90 学生90 male NA 68
91 学生91 male 23 NA
92 学生92 male 20 65
93 学生93 male 18 95
94 学生94 famle 18 94
95 学生95 male 19 68
96 学生96 famle 23 85
97 学生97 famle 19 65
98 学生98 famle 21 81
99 学生99 male 22 98
100 学生100 famle 20 71
2)、去除缺失值
实际上有两种方法,使用na.omit(alldate)或者alldate[complete.cases(alldate)]
> alldate<-na.omit(alldate);
> length(alldate[,1]); #可看到去除后数据框还剩下71行,即71个学生(有效数据)
[1] 71
事实上如果使用Rstudio也能在environment中观测到:
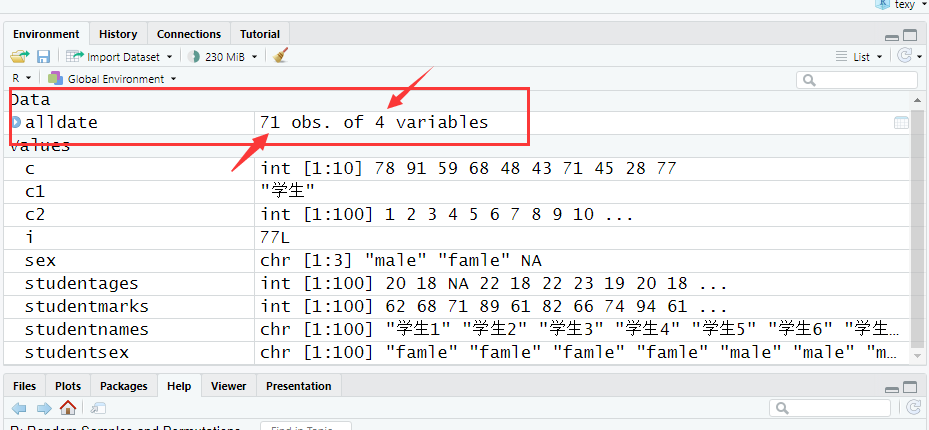
> alldate
studentnames studentsex studentages studentmarks
1 学生1 famle 20 62
2 学生2 famle 18 68
4 学生4 famle 22 89
5 学生5 male 18 61
6 学生6 male 22 82
7 学生7 male 23 66
8 学生8 famle 19 74
9 学生9 famle 20 94
10 学生10 famle 18 61
11 学生11 famle 23 99
14 学生14 male 18 98
15 学生15 famle 18 62
17 学生17 famle 23 77
18 学生18 famle 18 64
19 学生19 male 18 68
20 学生20 famle 20 93
21 学生21 male 21 73
22 学生22 famle 18 96
24 学生24 famle 19 68
25 学生25 male 23 73
27 学生27 famle 20 96
29 学生29 famle 20 65
30 学生30 famle 20 83
31 学生31 famle 22 82
32 学生32 male 23 95
33 学生33 famle 19 61
34 学生34 famle 18 64
35 学生35 famle 18 72
36 学生36 male 18 90
37 学生37 male 22 78
38 学生38 male 20 71
39 学生39 famle 20 99
40 学生40 famle 22 99
41 学生41 famle 22 95
42 学生42 famle 20 65
44 学生44 male 18 93
46 学生46 male 19 71
49 学生49 famle 18 75
50 学生50 famle 20 75
51 学生51 famle 18 98
53 学生53 famle 20 70
54 学生54 famle 23 73
56 学生56 famle 22 87
57 学生57 famle 18 88
58 学生58 famle 18 73
61 学生61 famle 18 70
62 学生62 famle 20 76
63 学生63 male 22 81
64 学生64 male 20 88
65 学生65 male 21 91
67 学生67 male 20 90
72 学生72 male 23 75
73 学生73 famle 20 76
74 学生74 famle 19 74
75 学生75 male 23 93
76 学生76 male 21 88
79 学生79 famle 19 62
81 学生81 male 22 96
82 学生82 male 21 81
85 学生85 famle 19 97
87 学生87 famle 22 92
89 学生89 male 22 60
92 学生92 male 20 65
93 学生93 male 18 95
94 学生94 famle 18 94
95 学生95 male 19 68
96 学生96 famle 23 85
97 学生97 famle 19 65
98 学生98 famle 21 81
99 学生99 male 22 98
100 学生100 famle 20 71
1.3 、任务三:返回性别为女生,年龄<20的学生及成绩
1)、使用函数介绍

2)、演示如下:
此处为了方便查看把学生姓名也罗列出来了。
> assignment3<-subset(alldate,studentsex=="famle" & studentages<20,select=c("studentnames","studentsex","studentages"));
> length(assignment3[,1])
[1] 20
> assignment3
studentnames studentsex studentages
2 学生2 famle 18
8 学生8 famle 19
10 学生10 famle 18
15 学生15 famle 18
18 学生18 famle 18
22 学生22 famle 18
24 学生24 famle 19
33 学生33 famle 19
34 学生34 famle 18
35 学生35 famle 18
49 学生49 famle 18
51 学生51 famle 18
57 学生57 famle 18
58 学生58 famle 18
61 学生61 famle 18
74 学生74 famle 19
79 学生79 famle 19
85 学生85 famle 19
94 学生94 famle 18
97 学生97 famle 19
1.4、 任务四:统计性别为女生,年龄<20,成绩>90的学生姓名、总人数
1)、演示过程如下:
任务四的要求和任务三大差不差,我们可用一致的方法解决:
> assignment4<-subset(alldate,studentsex=="famle" & studentages<20 & studentmarks>90);
> assignment4
studentnames studentsex studentages studentmarks
22 学生22 famle 18 96
51 学生51 famle 18 98
85 学生85 famle 19 97
94 学生94 famle 18 94
> length(assignment4[,1]);
[1] 4
1.5 、任务五:重新按照上述方法构建数据框,包含学生姓名,期中成绩两列
1)、数据框创建过程演示:
准备数据:根据后续任务要求有共同学生,此处创建50个学生姓名及成绩。对于学生编号采取随机生成。
> c1
[1] "学生"
> c3<-sample(c(1:150),size=50); #乱序生成50个编号,范围在1:150内,这样就有包含和非包含关系
> c3 #C3是乱序,此处我们先做一个升序整理,以便后续学生编号有序且美观
[1] 148 127 97 12 122 36 61 134 54 60 62 52 115 100 38 130 67 84 71 49
[21] 103 92 137 2 107 11 145 125 98 86 15 113 73 81 41 64 105 101 3 16
[41] 93 87 22 129 72 39 99 76 26 74
> c3<-sort(c3)
[1] 2 3 11 12 15 16 22 26 36 38 39 41 49 52 54 60 61 62 64 67
[21] 71 72 73 74 76 81 84 86 87 92 93 97 98 99 100 101 103 105 107 113
[41] 115 122 125 127 129 130 134 137 145 148
> anotherstudentnames<-paste(c1,c3,sep="");
> anotherstudentnames
[1] "学生2" "学生3" "学生11" "学生12" "学生15" "学生16" "学生22" "学生26"
[9] "学生36" "学生38" "学生39" "学生41" "学生49" "学生52" "学生54" "学生60"
[17] "学生61" "学生62" "学生64" "学生67" "学生71" "学生72" "学生73" "学生74"
[25] "学生76" "学生81" "学生84" "学生86" "学生87" "学生92" "学生93" "学生97"
[33] "学生98" "学生99" "学生100" "学生101" "学生103" "学生105" "学生107" "学生113"
[41] "学生115" "学生122" "学生125" "学生127" "学生129" "学生130" "学生134" "学生137"
[49] "学生145" "学生148"
> anotherstudentmarks<-sample(c(60:100),size=50,replace=T);
> anotherstudentmarks
[1] 86 72 66 66 87 65 76 78 79 71 68 90 88 88 92 66 78 85 84 86
[21] 62 83 60 63 87 78 80 62 99 61 89 75 98 76 71 82 65 94 80 74
[41] 73 68 100 100 60 76 78 90 71 92
创建第二个数据框:需要对行名做修改。
> alldate2<-data.frame(anotherstudentnames,anotherstudentmarks);
> names(alldate2)
[1] "anotherstudentnames" "anotherstudentmarks"
> names(alldate2)[1]<-"studentnames";#此处对数据框的行名称做修改是为了方便后续合并
> names(alldate2)[2]<-"studentmidmarks";#期中成绩
> names(alldate)#顺带对之前的数据框行名称也稍作修改方便观察
[1] "studentnames" "studentsex" "studentages" "studentmarks"
> names(alldate)[4]<-"studentfinmarks";#期末成绩
详细显示如下:
> alldate2
studentnames studentmarks
1 学生2 86
2 学生3 72
3 学生11 66
4 学生12 66
5 学生15 87
6 学生16 65
7 学生22 76
8 学生26 78
9 学生36 79
10 学生38 71
11 学生39 68
12 学生41 90
13 学生49 88
14 学生52 88
15 学生54 92
16 学生60 66
17 学生61 78
18 学生62 85
19 学生64 84
20 学生67 86
21 学生71 62
22 学生72 83
23 学生73 60
24 学生74 63
25 学生76 87
26 学生81 78
27 学生84 80
28 学生86 62
29 学生87 99
30 学生92 61
31 学生93 89
32 学生97 75
33 学生98 98
34 学生99 76
35 学生100 71
36 学生101 82
37 学生103 65
38 学生105 94
39 学生107 80
40 学生113 74
41 学生115 73
42 学生122 68
43 学生125 100
44 学生127 100
45 学生129 60
46 学生130 76
47 学生134 78
48 学生137 90
49 学生145 71
50 学生148 92
1.6、 任务六:将上述数据框同有学生信息合并构建新的数据框
1)、所用函数:
merge(数据框1,数据框2,by="标识符"):将两个数据框中个案按照标识符进行合并,只有同时出现在两个数据框中的个案才会被合并。
2)、数据框合并过程演示:
> alldate3<-merge(alldate,alldate2,by="studentnames");
> length(alldate3[,1]);
[1] 26
可看到合并生成的数据框是乱序,其共有26个学生。
> alldate3
studentnames studentsex studentages studentfinmarks studentmidmarks
1 学生100 famle 20 71 71
2 学生11 famle 23 99 66
3 学生15 famle 18 62 87
4 学生2 famle 18 68 86
5 学生22 famle 18 96 76
6 学生36 male 18 90 79
7 学生38 male 20 71 71
8 学生39 famle 20 99 68
9 学生41 famle 22 95 90
10 学生49 famle 18 75 88
11 学生54 famle 23 73 92
12 学生61 famle 18 70 78
13 学生62 famle 20 76 85
14 学生64 male 20 88 84
15 学生67 male 20 90 86
16 学生72 male 23 75 83
17 学生73 famle 20 76 60
18 学生74 famle 19 74 63
19 学生76 male 21 88 87
20 学生81 male 22 96 78
21 学生87 famle 22 92 99
22 学生92 male 20 65 61
23 学生93 male 18 95 89
24 学生97 famle 19 65 75
25 学生98 famle 21 81 98
26 学生99 male 22 98 76
1.7、 任务七:对新的数据框按照期末升序,期中降序排列
1)、演示如下:
使用order命令进行排序,此处演示三种情况:
①若单独按照期末升序,则为alldate3[order(alldate3$studentfinmarks),]
> alldate3[order(alldate3$studentfinmarks),]
studentnames studentsex studentages studentfinmarks studentmidmarks
3 学生15 famle 18 62 87
22 学生92 male 20 65 61
24 学生97 famle 19 65 75
4 学生2 famle 18 68 86
12 学生61 famle 18 70 78
1 学生100 famle 20 71 71
7 学生38 male 20 71 71
11 学生54 famle 23 73 92
18 学生74 famle 19 74 63
10 学生49 famle 18 75 88
16 学生72 male 23 75 83
13 学生62 famle 20 76 85
17 学生73 famle 20 76 60
25 学生98 famle 21 81 98
14 学生64 male 20 88 84
19 学生76 male 21 88 87
6 学生36 male 18 90 79
15 学生67 male 20 90 86
21 学生87 famle 22 92 99
9 学生41 famle 22 95 90
23 学生93 male 18 95 89
5 学生22 famle 18 96 76
20 学生81 male 22 96 78
26 学生99 male 22 98 76
2 学生11 famle 23 99 66
8 学生39 famle 20 99 68
②若单独按照期中降序,则为alldate3[order(-alldate3$studentmidmarks),]
> alldate3[order(-alldate3$studentmidmarks),]
studentnames studentsex studentages studentfinmarks studentmidmarks
21 学生87 famle 22 92 99
25 学生98 famle 21 81 98
11 学生54 famle 23 73 92
9 学生41 famle 22 95 90
23 学生93 male 18 95 89
10 学生49 famle 18 75 88
3 学生15 famle 18 62 87
19 学生76 male 21 88 87
4 学生2 famle 18 68 86
15 学生67 male 20 90 86
13 学生62 famle 20 76 85
14 学生64 male 20 88 84
16 学生72 male 23 75 83
6 学生36 male 18 90 79
12 学生61 famle 18 70 78
20 学生81 male 22 96 78
5 学生22 famle 18 96 76
26 学生99 male 22 98 76
24 学生97 famle 19 65 75
1 学生100 famle 20 71 71
7 学生38 male 20 71 71
8 学生39 famle 20 99 68
2 学生11 famle 23 99 66
18 学生74 famle 19 74 63
22 学生92 male 20 65 61
17 学生73 famle 20 76 60
③若按照期期末升序,期末相等时期中降序则为alldate3[order(alldate3$studentfinmarks),-alldate3$studentmidmarks]
> alldate3[order(alldate3$studentfinmarks),-alldate3$studentmidmarks]
studentnames studentsex studentages studentfinmarks studentmidmarks
3 学生15 famle 18 62 87
22 学生92 male 20 65 61
24 学生97 famle 19 65 75
4 学生2 famle 18 68 86
12 学生61 famle 18 70 78
1 学生100 famle 20 71 71
7 学生38 male 20 71 71
11 学生54 famle 23 73 92
18 学生74 famle 19 74 63
10 学生49 famle 18 75 88
16 学生72 male 23 75 83
13 学生62 famle 20 76 85
17 学生73 famle 20 76 60
25 学生98 famle 21 81 98
14 学生64 male 20 88 84
19 学生76 male 21 88 87
6 学生36 male 18 90 79
15 学生67 male 20 90 86
21 学生87 famle 22 92 99
9 学生41 famle 22 95 90
23 学生93 male 18 95 89
5 学生22 famle 18 96 76
20 学生81 male 22 96 78
26 学生99 male 22 98 76
2 学生11 famle 23 99 66
8 学生39 famle 20 99 68