分布式id
- 一 什么是分布式系统唯一ID
- 二 分布式系统唯一ID的特点
- 三 分布式系统唯一ID的实现方案
- 3.1 基于UUID
- 3.2 基于数据库自增id
- 3.3 基于数据库集群模式
- 3.4 基于Redis模式
- 3.5 基于雪花算法(Snowflake)模式
- 3.6 百度(uid-generator)
- 3.7 美团(Leaf)
- 3.8 滴滴(Tinyid)
一 什么是分布式系统唯一ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
如在金融、电商、支付、等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,此时一个能够生成全局唯一ID的系统是非常必要的。
二 分布式系统唯一ID的特点
- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,这就会带来一场灾难。
由此总结下一个ID生成系统应该做到如下几点:
- 平均延迟和TP999延迟都要尽可能低(TP90就是满足百分之九十的网络请求所需要的最低耗时。TP99就是满足百分之九十九的网络请求所需要的最低耗时。同理TP999就是满足千分之九百九十九的网络请求所需要的最低耗时);
- 可用性5个9(99.999%);
- 高QPS。
补充:QPS和TPS
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS:是TransactionsPerSecond的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
三 分布式系统唯一ID的实现方案
3.1 基于UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
优点:
- 生成简单,本地生成无网络消耗,性能非常高,具有唯一性。
缺点:
- 没有具体的业务含义:无序的字符串,没有具体的业务含义,且不具备趋势自增特性
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置。
- 存储性能差查询耗时:如果作为MySQL数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能,可以查阅 Mysql 索引原理 B+树的知识。
- 传输数据量大,且不可读。
3.2 基于数据库自增id
基于数据库的auto_increment自增ID完全可以充当分布式ID,具体实现:需要一个单独的MySQL实例用来生成ID。
优点:
- 实现简单,ID单调自增,数值类型查询速度快。
缺点:
- 强依赖DB,DB单点存在宕机风险,无法扛住高并发场景
3.3 基于数据库集群模式
前边说了单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。
那这样还会有个问题,两个MySQL实例的自增ID都从1开始,会生成重复的ID怎么办?
解决方案:设置起始值和自增步长
MySQL_1 配置:
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步长
MySQL_2 配置:
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长
优点:
- 解决DB单点问题
缺点:
- 不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景
3.4 基于Redis模式
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。
这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
- 需要编码和配置的工作量比较大。
3.5 基于雪花算法(Snowflake)模式
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式ID生成器。
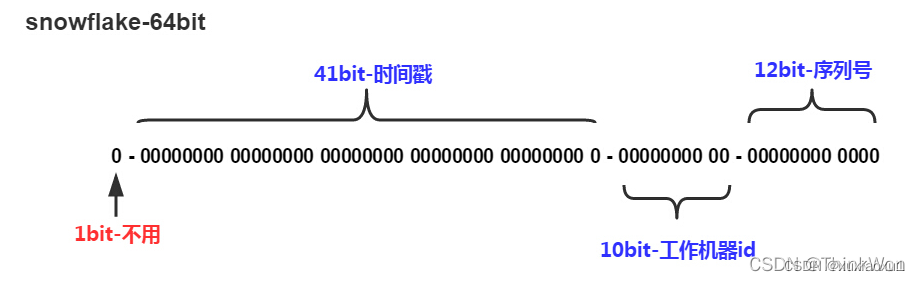
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
第一个bit位(1bit):代表正负,一般生成ID都为正数,所以默认为0。
时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
工作机器id(10bit):也被叫做workId,这个可以灵活配置,机房或者机器号组合都可以。
序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
优点:
- 不依赖外部组件,稳定性高
- 灵活方便,可以根据自身业务特性分配bit位
- 单机上ID单调自增,毫秒数在高位,自增序列在低位,整个ID都是趋势递增的
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态
- ID可能不是全局递增。在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况
python实现雪花算法
import time
import logging
from exceptions import InvalidSystemClock # 继承的Excpetion即可。
# 64 位 id 的划分,通常机器位和数据位各为 5 位
WORKER_ID_BITS = 5 # 机器位
DATACENTER_ID_BITS = 5 # 数据位
SEQUENCE_BITS = 12 # 循环位
# 最大取值计算,计算机中负数表示为他的补码
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS) # 2**5 -1 =31
MAX_DATACENTER_ID = -1 ^ (-1 << DATACENTER_ID_BITS)
# 移位偏移计算
WORKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS
# X序号循环掩码
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS)
# Twitter 元年时间戳
TWEPOCH = 1288834974657
logger = logging.getLogger('雪花算法')
class IdWorker(object):
'''
用于生成IDS.
'''
def __init__(self, datacenter_id, worker_id, sequence=0):
'''
初始化方法
:param datacenter_id:数据id
:param worker_id:机器id
:param sequence:序列码
'''
if worker_id > MAX_WORKER_ID or worker_id < 0:
raise ValueError('worker_id 值越界')
if datacenter_id > MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError('datacenter_id 值越界')
self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = sequence
self.last_timestamp = -1 # 上次计算的时间戳
def _gen_timestamp(self):
'''
生成整数时间戳。
:return:
'''
return int(time.time() * 1000)
def get_id(self):
'''
获取新的ID.
:return:
'''
# 获取当前时间戳
timestamp = self._gen_timestamp()
# 时钟回拨的情况
if timestamp < self.last_timestamp:
logging.error('clock is moving backwards. Rejecting requests util {}'.format(self.last_timestamp))
raise InvalidSystemClock
if timestamp == self.last_timestamp:
# 同一毫秒的处理。
self.sequence = (self.sequence + 1) & SEQUENCE_MASK
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
new_id = (((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.datacenter_id << DATACENTER_ID_SHIFT) | (
self.worker_id << WORKER_ID_SHIFT)) | self.sequence
return new_id
def _til_next_millis(self, last_timestamp):
'''
等到下一毫秒。
:param last_timestamp:
:return:
'''
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp
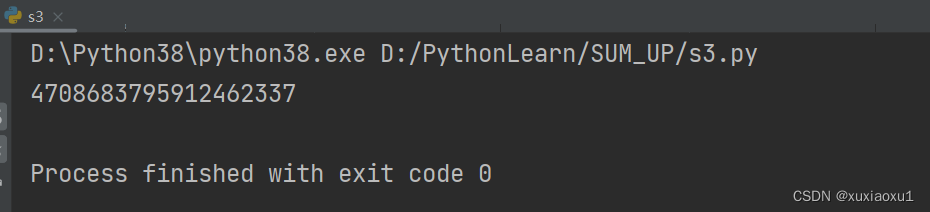
if __name__ == '__main__':
worker = IdWorker(1, 2, 0)
print(worker.get_id())
第三方包的使用
pip install pysnowflake
# 启动服务
snowflake_start_server --worker=1

from snowflake import client
print(client.get_guid())
3.6 百度(uid-generator)
uid-generator是由百度技术部开发,项目GitHub地址 https://github.com/baidu/uid-generator
uid-generator是基于Snowflake算法实现的,与原始的snowflake算法不同在于,uid-generator支持自定义时间戳、工作机器ID和 序列号 等各部分的位数,而且uid-generator中采用用户自定义workId的生成策略。
uid-generator需要与数据库配合使用,需要新增一个WORKER_NODE表。当应用启动时会向数据库表中去插入一条数据,插入成功后返回的自增ID就是该机器的workId数据,由host,port组成。
3.7 美团(Leaf)
Leaf由美团开发,github地址:https://github.com/Meituan-Dianping/Leaf
3.8 滴滴(Tinyid)
Tinyid由滴滴开发,Github地址:https://github.com/didi/tinyid。