一、东窗事发
某个版本送测,测试大佬给提了一个缺陷,且听我描述描述:
-
一个学习任务:

-
两个一模一样的学习动态:

- 产品定义:学习任务(生字学习)完成后,会在小程序生成一个动态,再次完成不重复生成
obviously,上边出现的两个动态不符合“罗辑”

二、排查看看
既然出现了两个动态,那就来看看动态的源头是不是生成了两个
1.先看动态生成的触发点
下边为简化版的伪代码
// student_id - learn_type 是唯一索引
val rt = execSql(
"""
INSERT INTO t_learn_state (student_id, learn_type, create_time, update_time)
VALUES ("bc6b5e6979af11e8a10c1c1b0d1c49aa",10,now(),now())
ON DUPLICATE KEY UPDATE update_time = now()
""")
//判断是否首次完成
if (rt == 1) {
//发送完成MQ消息
sendMq("StudyXXXTopic","ResourceFinish","bc6b5e6979af11e8a10c1c1b0d1c49aa finish 10")
}
复制代码看起来没什么问题,难道是mq重复消费了?
2.看看mq的消息情况
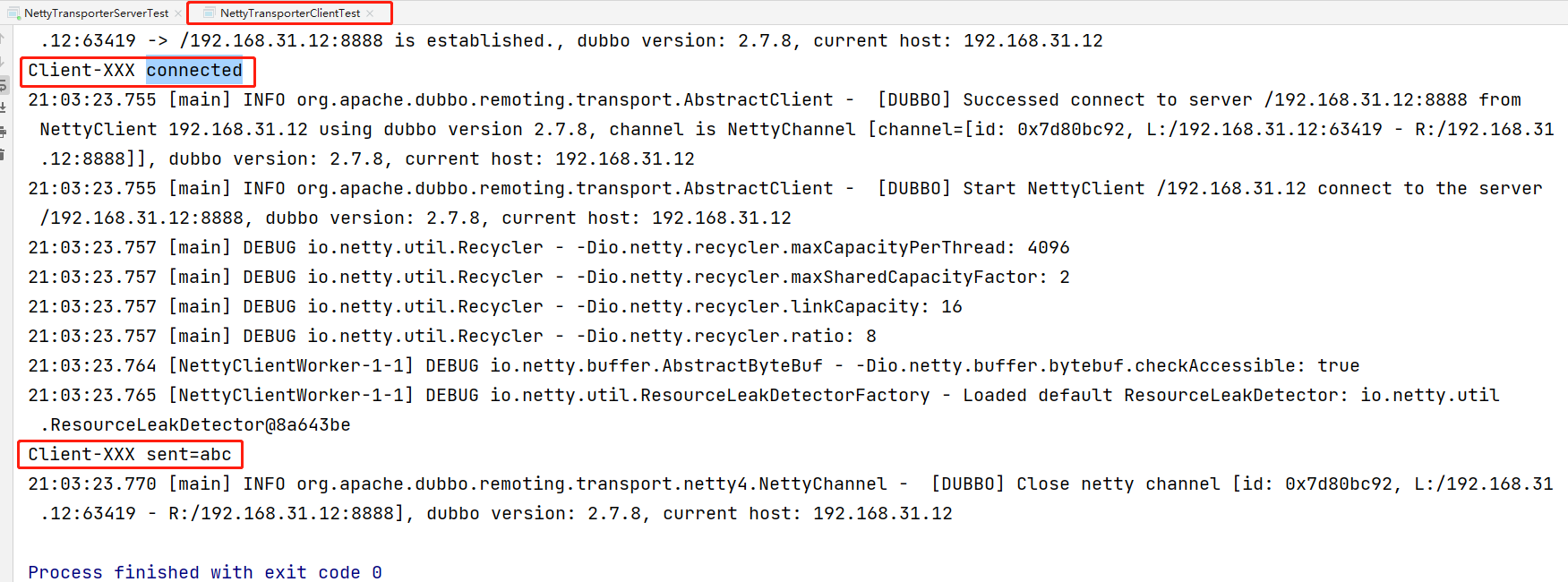
直接看mq后台的消息记录:
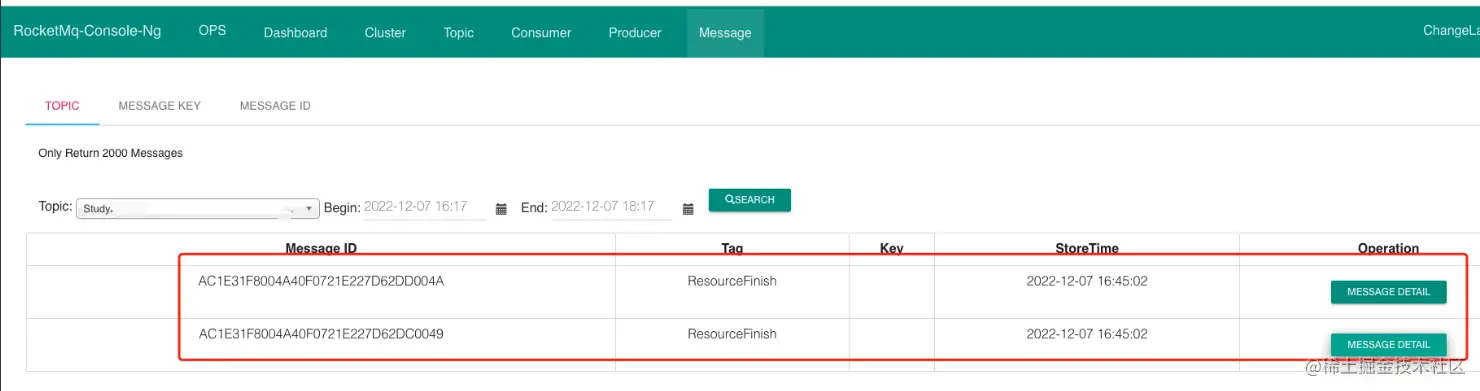
可见有两条时间非常接近的mq消息,展开消息后发现内容是一致的,也就是重复生成了消息,而不是重复消费,怎么会这样呢?难道唯一索引没创建?
3.看看表中有多少条记录
only one!

也就是唯一索引是生效的,表中确实只有一条记录
4.难道对 INSERT ON DUPLICATE KEY UPDATE 理解有误?
首先确认了jdbc的链接参数并没有使用useAffectedRows=true,也就是该sql的返回值是matched的行数!(后文也是基于此进行的分析)
再经过几番搜索及请教大佬,返回值确实是这样子的:
- 如果是新插入的记录,那么返回值是
1 - 如果发生了唯一键冲突并更新了记录,那么返回值是
2
如此这般,那问题到底出在哪了呢?
4.还是复现看看吧!
找了下对应时间的流量,符合的其实就两条:

经过代码排查,这两个请求最终都会执行到上边的伪代码,在清除数据并重放几次之后,复现了!
5.结果都是1
经过debug发现,两次execSql的结果都是1,通过mybatis的日志也能拿到准确的sql,如下:
//两次非常临近执行的sql是一模一样的,并且rt都是1
val rt = execSql(
"""
INSERT INTO t_learn_state (student_id, learn_type, create_time, update_time)
VALUES ("bc6b5e6979af11e8a10c1c1b0d1c49aa",10,now(),now())
ON DUPLICATE KEY UPDATE update_time = now()
"""
)
复制代码但是为什么两次执行的结果都是1呢?按照说明应该是第一次为1,第二次应该会触发唯一键冲突而导致更新进而返回2才对呀!
6.恍然大明白
将sql拿到idea中执行,也能够复现,多执行几次,终于发现了华点:
在同一秒内执行的多次该sql,其返回值都是
1,跨秒之后则会出现一次2
再喵一眼表结构:
CREATE TABLE `t_learn_state`
(
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`student_id` char(32) NOT NULL COMMENT '学生id',
`learn_type` int(4) NOT NULL COMMENT '学习类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `udx_student_learn_type` (`student_id`, `learn_type`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4;
复制代码时间用的是 datetime 类型,这意味着时间精度是秒,也就是当我同一秒内多次进行更新的时候,实际上该行的记录是没有变动的!!!在这种情况下,返回值也是1!!!

7.补充INSERT ON DUPLICATE KEY UPDATE的一种情况
完整如下:
- 如果是新插入的记录,那么返回值是
1 - 如果发生了唯一键冲突并更新了记录,那么返回值是
2 - 如果唯一键发生了冲突,但是并没有更新记录,那么返回值将会是
1
三、场景回顾和分析
- 为什么需要使用到
INSERT ON DUPLICATE KEY UPDATE的返回值呢? - 能不能有其它的方式达到这个效果?
1.原始需求和场景
描述下几个关键的点:
- 只有首次完成任务的时候,才会触发一系列的操作(可以理解为发mq消息)
- 完成的判定标准则是在表里边有一条完成记录(唯一键冲突时可认为非首次完成)
- 当用户重复完成的时候,会更新一些属性字段,但是不应触发mq消息
- 存在并发完成的操作场景
从代码逻辑上看,也就是并发情况下能区分出该用户是否为首次完成即可
2.常见的解决方案有哪些?
各有取舍、各有优劣!
a.朴素版
//伪代码
var data = "select * from t_learn_state where student_id = bc6b5e6979af11e8a10c1c1b0d1c49aa and learn_type=10"
if (data == null){
//首次完成
"insert into t_learn_state(student_id, learn_type) values ('bc6b5e6979af11e8a10c1c1b0d1c49aa','10')"
}else{
//非首次完成
"update t_learn_state set update_time = now()"
}
复制代码b.事务版
//伪代码
transaction.open //打开事务
var data = "select * from t_learn_state where student_id = bc6b5e6979af11e8a10c1c1b0d1c49aa and learn_type=10"
if (data == null){
//首次完成
"insert into t_learn_state(student_id, learn_type) values ('bc6b5e6979af11e8a10c1c1b0d1c49aa','10')"
}else{
//非首次完成
"update t_learn_state set update_time = now()"
}
transaction.commit //提交事务
复制代码c.互斥锁版
//伪代码
transaction.open //打开事务
var data = "select * from t_learn_state where student_id = bc6b5e6979af11e8a10c1c1b0d1c49aa and learn_type=10 for update"
if (data == null){
//首次完成
"insert into t_learn_state(student_id, learn_type) values ('bc6b5e6979af11e8a10c1c1b0d1c49aa','10')"
}else{
//非首次完成
"update t_learn_state set update_time = now()"
}
transaction.commit //提交事务
复制代码d.冲突更新版
//伪代码
val rt =
"""
INSERT INTO t_learn_state (student_id, learn_type, create_time, update_time)
VALUES ("bc6b5e6979af11e8a10c1c1b0d1c49aa",10,now(),now())
ON DUPLICATE KEY UPDATE update_time = now()
"""
//判断是否首次完成
if (rt == 1) {
//首次完成
}else{
//非首次完成
}
复制代码e.分布式锁版
//伪代码
distributeLock.lock //获取分布式锁
var data = "select * from t_learn_state where student_id = bc6b5e6979af11e8a10c1c1b0d1c49aa and learn_type=10"
if (data == null){
//首次完成
"insert into t_learn_state(student_id, learn_type) values ('bc6b5e6979af11e8a10c1c1b0d1c49aa','10')"
}else{
//非首次完成
"update t_learn_state set update_time = now()"
}
distributeLock.unlock //释放分布式锁
复制代码3.常见的做法的比较
| 版本 | 实现复杂度 | 对db的压力 | 对业务服务的压力 | 并发出错概率 | 备注 |
|---|---|---|---|---|---|
| 朴素版 | ✦ | ✦ | ✦ | ✦✦✦✦✦ | 不处理并发 |
| 事务版 | ✦ | ✦ | ✦ | ✦✦✦✦✦ | mysql的RR级别 |
| 互斥锁版 | ✦ | ✦✦✦✦✦ | ✦✦ | ✦ | 竞争完全下放到db,并且多次分离执行sql |
| 冲突更新版 | ✦ | ✦✦✦✦ | ✦ | ✦ | 一条sql搞定 |
| 分布式锁版 | ✦✦✦✦ | ✦ | ✦✦✦✦✦ | ✦ | 竞争完全放到业务服务 |
4.本文选择 朴素版+冲突更新版
目前遇到的场景及要求是,并发较小、但是数据是用户可见的,因此对并发错误的容忍度是比较低的,但是又不想把整个流程搞得非常复杂,所以可以将朴素版+冲突更新版进行结合,示意:
//伪代码
var data = "select * from t_learn_state where student_id = bc6b5e6979af11e8a10c1c1b0d1c49aa and learn_type=10"
if (data == null){
val rt =
"""
INSERT INTO t_learn_state (student_id, learn_type, create_time, update_time)
VALUES ("bc6b5e6979af11e8a10c1c1b0d1c49aa",10,now(),now())
ON DUPLICATE KEY UPDATE update_time = now()
"""
//判断是否首次完成
if (rt == 1) {
//首次完成
}else{
//非首次完成
}
}else{
//非首次完成
"update t_learn_state set update_time = now()"
}
复制代码综上,我们还是得解决INSERT ON DUPLICATE KEY UPDATE的返回值问题
四、回到 INSERT ON DUPLICATE KEY UPDATE 问题
目前根据搜集到的资料和请教大佬,得到如下几种解法
1.变更返回值类型
也就是前文提到的通过在jdbc中配置useAffectedRows=true,可以将matched rows变为 updated rows,这样也能解决,但是目前jdbc已经使用已久,很多返回值已经有在使用,因此不可贸然变更
| 配置 | 插入 | 更新 | 无变化 |
|---|---|---|---|
useAffectedRows=true | 1 | 2 | 0 |
useAffectedRows=false | 1 | 2 | 1 |
2.细化时间精度
可见,由于datetime是精确到秒的,因此秒内的依据now()更新时实际上是不更新的,因此我们可以把这个类型细化到更细的粒度,如毫秒级,这样只有在毫秒内的并发才会出现重复
3.增加一个版本号
如何保证每次INSERT ON DUPLICATE KEY UPDATE都更新到表记录呢?那就是每次都手动更新,通过增加一个version字段,每次冲突时都进行+1操作:
val rt = execSql(
"""
INSERT INTO t_learn_state (student_id, learn_type, version, create_time, update_time)
VALUES ("bc6b5e6979af11e8a10c1c1b0d1c49aa",10,1,now(),now())
ON DUPLICATE KEY UPDATE update_time = now() and version = version + 1
"""
)
复制代码这样就能屏蔽唯一索引冲突时,没有更新行记录的情况
五、写在最后
thanks for reading.有其它方案或想法可以一起交流!