Flink Sql
- 1、简介
- 2、网址
- 3、SQL客户端
- 4、Queries
- 5、Create
- 6、Drop
- 7、Alter
- 8、Insert
- 9、ANALYZE
- 10、Describe
- 11、Explain
- 12、Use
- 13、Show
- 14、Load
- 15、Unload
- 16、Set
- 17、Reset
- 18、Jar
- 19、Windowing TVF
- 19.1、TUMBLE(滚动窗口)
- 19.2、HOP(滑动窗口)
- 19.3、CUMULATE(累计窗口)
- 19.4、Window Offset(以上三个窗口函数的可选配置)
- 20、其他函数
1、简介
Flink Table Api在使用的时候需要嵌入java、Scala、Python编写的程序中,有的时候开发不是很方便,因此日常大多数基本开发都会使用Flink SQL进行开发。
介绍Flink支持的SQL语言,包括DDL (Data Definition language)、DML (Data Manipulation language)和查询语言。Flink的SQL支持基于Apache Calcite,它实现了SQL标准。

2、网址
1、Flinksql官方文档教程 Flink 1.16版本的SQL语法文档
3、SQL客户端
SQL客户端内置在Flink的版本中,大家只要启动即可,我使用的是docker环境中配置的Flink SQL Click,大家根据自己的需求安装即可。
查看结果:
运行成功:
4、Queries
SELECT语句和VALUES语句是通过TableEnvironment的sqlQuery()方法指定的。该方法将SELECT语句(或VALUES语句)的结果作为一个Table返回。Table可以在后续的SQL和Table API查询中使用,可以转换为DataStream,也可以写入到TableSink中。SQL和Table API查询可以无缝地混合,并进行整体优化,并转换为单个程序。
为了在SQL查询中访问一个表,它必须在TableEnvironment中注册。一个表可以从一个表源、表、CREATE table语句、DataStream注册。或者,用户还可以在TableEnvironment中注册目录,以指定数据源的位置。
为了方便起见,table . tostring()自动在其TableEnvironment中以唯一的名称注册表并返回该名称。因此,Table对象可以直接内联到SQL查询中,如下面的示例所示。
注意:包含不支持的SQL特性的查询会导致TableException。SQL在批处理表和流表上支持的特性将在以下部分中列出。
Flink使用Apache Calcite解析SQL,它支持标准的ANSI SQL。
具体语法链接
query:
values
| WITH withItem [ , withItem ]* query
| {
select
| selectWithoutFrom
| query UNION [ ALL ] query
| query EXCEPT query
| query INTERSECT query
}
[ ORDER BY orderItem [, orderItem ]* ]
[ LIMIT { count | ALL } ]
[ OFFSET start { ROW | ROWS } ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY]
withItem:
name
[ '(' column [, column ]* ')' ]
AS '(' query ')'
orderItem:
expression [ ASC | DESC ]
select:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
FROM tableExpression
[ WHERE booleanExpression ]
[ GROUP BY { groupItem [, groupItem ]* } ]
[ HAVING booleanExpression ]
[ WINDOW windowName AS windowSpec [, windowName AS windowSpec ]* ]
selectWithoutFrom:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
projectItem:
expression [ [ AS ] columnAlias ]
| tableAlias . *
tableExpression:
tableReference [, tableReference ]*
| tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ]
joinCondition:
ON booleanExpression
| USING '(' column [, column ]* ')'
tableReference:
tablePrimary
[ matchRecognize ]
[ [ AS ] alias [ '(' columnAlias [, columnAlias ]* ')' ] ]
tablePrimary:
[ TABLE ] tablePath [ dynamicTableOptions ] [systemTimePeriod] [[AS] correlationName]
| LATERAL TABLE '(' functionName '(' expression [, expression ]* ')' ')'
| [ LATERAL ] '(' query ')'
| UNNEST '(' expression ')'
tablePath:
[ [ catalogName . ] databaseName . ] tableName
systemTimePeriod:
FOR SYSTEM_TIME AS OF dateTimeExpression
dynamicTableOptions:
/*+ OPTIONS(key=val [, key=val]*) */
key:
stringLiteral
val:
stringLiteral
values:
VALUES expression [, expression ]*
groupItem:
expression
| '(' ')'
| '(' expression [, expression ]* ')'
| CUBE '(' expression [, expression ]* ')'
| ROLLUP '(' expression [, expression ]* ')'
| GROUPING SETS '(' groupItem [, groupItem ]* ')'
windowRef:
windowName
| windowSpec
windowSpec:
[ windowName ]
'('
[ ORDER BY orderItem [, orderItem ]* ]
[ PARTITION BY expression [, expression ]* ]
[
RANGE numericOrIntervalExpression {PRECEDING}
| ROWS numericExpression {PRECEDING}
]
')'
matchRecognize:
MATCH_RECOGNIZE '('
[ PARTITION BY expression [, expression ]* ]
[ ORDER BY orderItem [, orderItem ]* ]
[ MEASURES measureColumn [, measureColumn ]* ]
[ ONE ROW PER MATCH ]
[ AFTER MATCH
( SKIP TO NEXT ROW
| SKIP PAST LAST ROW
| SKIP TO FIRST variable
| SKIP TO LAST variable
| SKIP TO variable )
]
PATTERN '(' pattern ')'
[ WITHIN intervalLiteral ]
DEFINE variable AS condition [, variable AS condition ]*
')'
measureColumn:
expression AS alias
pattern:
patternTerm [ '|' patternTerm ]*
patternTerm:
patternFactor [ patternFactor ]*
patternFactor:
variable [ patternQuantifier ]
patternQuantifier:
'*'
| '*?'
| '+'
| '+?'
| '?'
| '??'
| '{' { [ minRepeat ], [ maxRepeat ] } '}' ['?']
| '{' repeat '}'
5、Create
CREATE 语句用于向当前或指定的 Catalog 中注册表、视图或函数。注册后的表、视图和函数可以在 SQL 查询中使用。
具体语法链接
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
{ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n]
[ <watermark_definition> ]
[ <table_constraint> ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( <like_options> )] | AS select_query ]
<physical_column_definition>:
column_name column_type [ <column_constraint> ] [COMMENT column_comment]
<column_constraint>:
[CONSTRAINT constraint_name] PRIMARY KEY NOT ENFORCED
<table_constraint>:
[CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED
<metadata_column_definition>:
column_name column_type METADATA [ FROM metadata_key ] [ VIRTUAL ]
<computed_column_definition>:
column_name AS computed_column_expression [COMMENT column_comment]
<watermark_definition>:
WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
<source_table>:
[catalog_name.][db_name.]table_name
<like_options>:
{
{ INCLUDING | EXCLUDING } { ALL | CONSTRAINTS | PARTITIONS }
| { INCLUDING | EXCLUDING | OVERWRITING } { GENERATED | OPTIONS | WATERMARKS }
}[, ...]
6、Drop
DROP 语句可用于删除指定的 catalog,也可用于从当前或指定的 Catalog 中删除一个已经注册的表、视图或函数。
具体语法链接
--删除表
DROP TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
--删除数据库
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
--删除视图
DROP [TEMPORARY] VIEW [IF EXISTS] [catalog_name.][db_name.]view_name
--删除函数
DROP [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name;
7、Alter
ALTER 语句用于修改一个已经在 Catalog 中注册的表、视图、数据库或函数的定义。
具体语法链接
--修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
--设置或修改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
--修改视图名
ALTER VIEW [catalog_name.][db_name.]view_name RENAME TO new_view_name
--在数据库中设置一个或多个属性。若个别属性已经在数据库中设定,将会使用新值覆盖旧值。
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
8、Insert
INSERT 语句用来向表中添加行(INTO是追加,OVERWRITE是覆盖)
具体语法链接
-- 1. 插入别的表的数据
[EXECUTE] INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name [PARTITION part_spec] [column_list] select_statement
part_spec:
(part_col_name1=val1 [, part_col_name2=val2, ...])
column_list:
(col_name1 [, column_name2, ...])
-- 追加行到该静态分区中 (date='2019-8-30', country='China')
INSERT INTO country_page_view PARTITION (date='2019-8-30', country='China')
SELECT user, cnt FROM page_view_source;
-- 追加行到分区 (date, country) 中,其中 date 是静态分区 '2019-8-30';country 是动态分区,其值由每一行动态决定
INSERT INTO country_page_view PARTITION (date='2019-8-30')
SELECT user, cnt, country FROM page_view_source;
-- 覆盖行到静态分区 (date='2019-8-30', country='China')
INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30', country='China')
SELECT user, cnt FROM page_view_source;
-- 覆盖行到分区 (date, country) 中,其中 date 是静态分区 '2019-8-30';country 是动态分区,其值由每一行动态决定
INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30')
SELECT user, cnt, country FROM page_view_source;
-- 2. 将值插入表中
INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name VALUES [values_row , values_row ...]
values_row:
(val1 [, val2, ...])
CREATE TABLE students (name STRING, age INT, gpa DECIMAL(3, 2)) WITH (...);
INSERT INTO students
VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
-- 3.将数据插入多个表中
EXECUTE STATEMENT SET
BEGIN
insert_statement;
...
insert_statement;
END;
insert_statement:
<insert_from_select>|<insert_from_values>
CREATE TABLE students (name STRING, age INT, gpa DECIMAL(3, 2)) WITH (...);
EXECUTE STATEMENT SET
BEGIN
INSERT INTO students
VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
INSERT INTO students
VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32);
END;
9、ANALYZE
ANALYZE语句用于收集现有表的统计信息,并将结果存储到目录中。现在只支持ANALYZE TABLE语句,并且需要手动触发,而不是自动触发。
注意目前ANALYZE TABLE只支持批处理模式。只支持现有的表,如果表是视图或表不存在,则会抛出异常。
具体语法链接
ANALYZE TABLE [catalog_name.][db_name.]table_name PARTITION(partcol1[=val1] [, partcol2[=val2], ...]) COMPUTE STATISTICS [FOR COLUMNS col1 [, col2, ...] | FOR ALL COLUMNS]
10、Describe
DESCRIBE语句用于描述表或视图的结构。
具体语法链接
{ DESCRIBE | DESC } [catalog_name.][db_name.]table_name
11、Explain
EXPLAIN语句用于解释查询或INSERT语句的逻辑和优化的查询计划。
具体语法链接
EXPLAIN [([ExplainDetail[, ExplainDetail]*]) | PLAN FOR] <query_statement_or_insert_statement_or_statement_set>
statement_set:
EXECUTE STATEMENT SET
BEGIN
insert_statement;
...
insert_statement;
END;
Flink SQL> CREATE TABLE MyTable1 (`count` bigint, word VARCHAR(256)) WITH ('connector' = 'datagen');
[INFO] Table has been created.
Flink SQL> CREATE TABLE MyTable2 (`count` bigint, word VARCHAR(256)) WITH ('connector' = 'datagen');
[INFO] Table has been created.
Flink SQL> EXPLAIN PLAN FOR SELECT `count`, word FROM MyTable1 WHERE word LIKE 'F%'
> UNION ALL
> SELECT `count`, word FROM MyTable2;
Flink SQL> EXPLAIN ESTIMATED_COST, CHANGELOG_MODE, JSON_EXECUTION_PLAN SELECT `count`, word FROM MyTable1
> WHERE word LIKE 'F%'
> UNION ALL
> SELECT `count`, word FROM MyTable2;
== Abstract Syntax Tree ==
LogicalUnion(all=[true])
:- LogicalProject(count=[$0], word=[$1])
: +- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')])
: +- LogicalTableScan(table=[[default_catalog, default_database, MyTable1]])
+- LogicalProject(count=[$0], word=[$1])
+- LogicalTableScan(table=[[default_catalog, default_database, MyTable2]])
== Optimized Physical Plan ==
Union(all=[true], union=[count, word], changelogMode=[I]): rowcount = 1.05E8, cumulative cost = {3.1E8 rows, 3.05E8 cpu, 4.0E9 io, 0.0 network, 0.0 memory}
:- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')], changelogMode=[I]): rowcount = 5000000.0, cumulative cost = {1.05E8 rows, 1.0E8 cpu, 2.0E9 io, 0.0 network, 0.0 memory}
: +- TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word], changelogMode=[I]): rowcount = 1.0E8, cumulative cost = {1.0E8 rows, 1.0E8 cpu, 2.0E9 io, 0.0 network, 0.0 memory}
+- TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word], changelogMode=[I]): rowcount = 1.0E8, cumulative cost = {1.0E8 rows, 1.0E8 cpu, 2.0E9 io, 0.0 network, 0.0 memory}
== Optimized Execution Plan ==
Union(all=[true], union=[count, word])
:- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])
: +- TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word])
+- TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word])
== Physical Execution Plan ==
{
"nodes" : [ {
"id" : 37,
"type" : "Source: TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word])",
"pact" : "Data Source",
"contents" : "Source: TableSourceScan(table=[[default_catalog, default_database, MyTable1]], fields=[count, word])",
"parallelism" : 1
}, {
"id" : 38,
"type" : "Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])",
"pact" : "Operator",
"contents" : "Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])",
"parallelism" : 1,
"predecessors" : [ {
"id" : 37,
"ship_strategy" : "FORWARD",
"side" : "second"
} ]
}, {
"id" : 39,
"type" : "Source: TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word])",
"pact" : "Data Source",
"contents" : "Source: TableSourceScan(table=[[default_catalog, default_database, MyTable2]], fields=[count, word])",
"parallelism" : 1
} ]
12、Use
USE语句用于设置当前数据库或目录,或更改模块的解析顺序和启用状态。
具体语法链接
USE CATALOG catalog_name
USE MODULES module_name1[, module_name2, ...]
USE [catalog_name.]database_name
13、Show
SHOW语句用于在相应的父对象中列出对象,如目录、数据库、表和视图、列、函数和模块。有关更多详细信息和其他选项,请参阅各个命令。
SHOW CREATE语句用于打印DDL语句,可以使用该DDL语句创建给定对象。目前’ SHOW CREATE '语句仅在打印给定表和视图的DDL语句时可用。
Flink SQL目前支持以下SHOW语句:
具体语法链接
SHOW CATALOGS
SHOW CURRENT CATALOG
SHOW DATABASES
SHOW CURRENT DATABASE
SHOW TABLES
SHOW CREATE TABLE
SHOW COLUMNS
SHOW VIEWS
SHOW CREATE VIEW
SHOW FUNCTIONS
SHOW MODULES
SHOW JARS
14、Load
LOAD语句用于加载内置或用户定义的模块。
具体语法链接
LOAD MODULE module_name [WITH ('key1' = 'val1', 'key2' = 'val2', ...)]
Flink SQL> LOAD MODULE hive WITH ('hive-version' = '3.1.2');
[INFO] Load module succeeded!
Flink SQL> SHOW MODULES;
+-------------+
| module name |
+-------------+
| core |
| hive |
+-------------+
15、Unload
UNLOAD语句用于卸载内置或用户定义的模块。
具体语法链接
UNLOAD MODULE module_name
Flink SQL> UNLOAD MODULE core;
[INFO] Unload module succeeded!
Flink SQL> SHOW MODULES;
Empty set
16、Set
SET语句用于修改配置或列出配置。
具体语法链接
SET ('key' = 'value');
Flink SQL> SET 'table.local-time-zone' = 'Europe/Berlin';
[INFO] Session property has been set.
Flink SQL> SET;
'table.local-time-zone' = 'Europe/Berlin'
17、Reset
RESET语句用于将配置重置为默认值。
具体语法链接
RESET ('key');
Flink SQL> RESET 'table.planner';
[INFO] Session property has been reset.
Flink SQL> RESET;
[INFO] All session properties have been set to their default values.
18、Jar
JAR语句用于将用户JAR添加到类路径中,或从类路径中删除用户JAR,或在运行时在类路径中显示添加的JAR。
Flink SQL目前支持以下JAR语句:
具体语法链接
ADD JAR
SHOW JARS
REMOVE JAR
ADD JAR '<path_to_filename>.jar'
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
19、Windowing TVF
具体语法链接
窗口是处理无限流的核心。Windows将流分割为有限大小的“桶”,我们可以对其进行计算。本文档重点介绍如何在Flink SQL中执行窗口,以及程序员如何从其提供的功能中获得最大的好处。
Apache Flink提供了几个窗口表值函数(TVF)来将表中的元素划分为窗口,包括:
- Tumble Windows
- Hop Windows
- Cumulate Windows
- Session Windows (will be supported soon)
请注意,每个元素在逻辑上可以属于多个窗口,这取决于您使用的窗口表值函数。例如,HOP窗口创建重叠的窗口,其中一个元素可以分配给多个窗口。
窗口tvf是传统分组窗口函数的替代品。窗口TVFs更符合SQL标准,更强大,可以支持复杂的基于窗口的计算,例如窗口TopN,窗口Join。但是,分组窗口函数只能支持窗口聚合。
Apache Flink提供了3个内置的窗口tvf: TUMBLE、HOP和CUMULATE。窗口TVF的返回值是一个新的关系,它包括原始关系的所有列,以及额外的3列“window_start”,“window_end”,“window_time”,以指示分配的窗口。在流模式下,“window_time”字段是窗口的时间属性。在批处理模式下,“window_time”字段是一个基于输入时间字段类型的TIMESTAMP或TIMESTAMP_LTZ类型的属性。“window_time”字段可用于后续的基于时间的操作,例如另一个窗口TVF,或聚合上的间隔连接。window_time的值总是等于window_end - 1ms。
19.1、TUMBLE(滚动窗口)
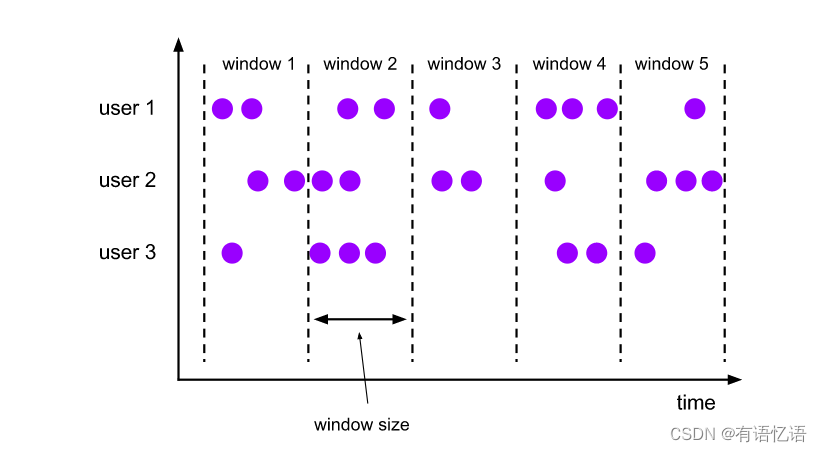
TUMBLE函数将每个元素分配给指定窗口大小的窗口。滚动窗口有固定的大小,不重叠。例如,假设您指定了一个大小为5分钟的滚动窗口。在这种情况下,Flink将评估当前窗口,并每五分钟启动一个新窗口,如下图所示。
--1. TUMBLE函数的参数
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
-- TABLE:代表数据源
-- DESCRIPTOR(timecol):指时间列
-- size:指窗口大小
-- offset:可增加其他参数,会有特别的意义
-- 2. 例子
-- tables must have time attribute, e.g. `bidtime` in this table
Flink SQL> desc Bid;
+-------------+------------------------+------+-----+--------+---------------------------------+
| name | type | null | key | extras | watermark |
+-------------+------------------------+------+-----+--------+---------------------------------+
| bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND |
| price | DECIMAL(10, 2) | true | | | |
| item | STRING | true | | | |
+-------------+------------------------+------+-----+--------+---------------------------------+
Flink SQL> SELECT * FROM Bid;
+------------------+-------+------+
| bidtime | price | item |
+------------------+-------+------+
| 2020-04-15 08:05 | 4.00 | C |
| 2020-04-15 08:07 | 2.00 | A |
| 2020-04-15 08:09 | 5.00 | D |
| 2020-04-15 08:11 | 3.00 | B |
| 2020-04-15 08:13 | 1.00 | E |
| 2020-04-15 08:17 | 6.00 | F |
+------------------+-------+------+
Flink SQL> SELECT * FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
Flink SQL> SELECT * FROM TABLE(
TUMBLE(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the tumbling windowed table
Flink SQL> SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+
为了更好地理解窗口的行为,我们简化了时间戳值的显示,不显示后面的零,例如,如果类型是timestamp(3),在Flink SQL客户端中,2020-04-15 08:05应该显示为2020-04-15 08:05:00.000。
19.2、HOP(滑动窗口)
HOP函数将元素分配给固定长度的窗口。与TUMBLE窗口函数一样,窗口的大小由窗口大小参数配置。一个附加的窗口滑动参数控制跳窗启动的频率。因此,如果幻灯片小于窗口大小,则跳跃窗口可以重叠。在这种情况下,元素被分配给多个窗口。跳窗又称“滑动窗”。
例如,您可以有一个大小为10分钟的窗口,它可以滑动5分钟。这样,每隔5分钟就会有一个窗口,其中包含最近10分钟内到达的事件,如下图所示。
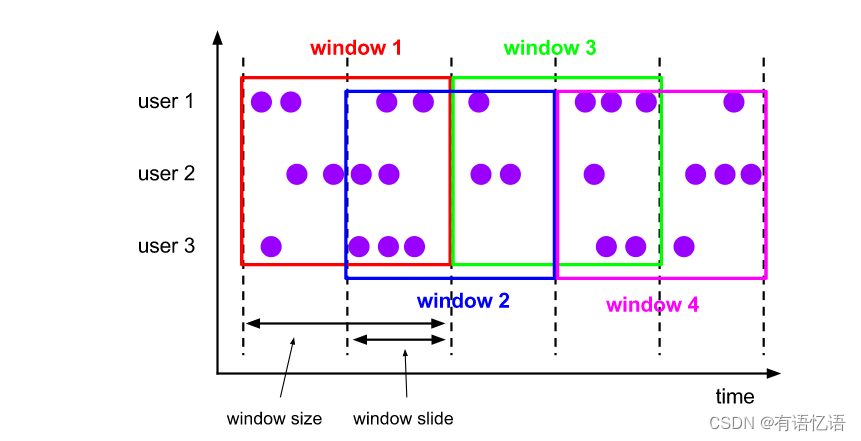
HOP函数分配窗口,这些窗口覆盖大小间隔内的行,并根据时间属性字段移动每一张幻灯片。在流模式中,时间属性字段必须是事件或处理时间属性。在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP_LTZ类型的属性。HOP的返回值是一个新的关系,它包括原来关系的所有列,以及额外的3列“window_start”,“window_end”,“window_time”,表示分配的窗口。原始时间属性“timecol”将是对TVF加窗后的常规时间戳列。
-- 1. HOP函数的参数
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
-- TABLE:代表数据源
-- DESCRIPTOR(timecol):指时间列
-- slide:指窗口滑动的大小
-- size:指窗口大小
-- offset:可增加其他参数,会有特别的意义
-- 2.例子
> SELECT * FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
> SELECT * FROM TABLE(
HOP(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SLIDE => INTERVAL '5' MINUTES,
SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:15 | 2020-04-15 08:25 | 2020-04-15 08:24:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the hopping windowed table
> SELECT window_start, window_end, SUM(price)
FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:05 | 2020-04-15 08:15 | 15.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
| 2020-04-15 08:15 | 2020-04-15 08:25 | 6.00 |
+------------------+------------------+-------+
19.3、CUMULATE(累计窗口)
累计窗口是指在固定窗口内,每隔一段时间触发操作。类似于滚动窗口内定时进行累计操作。
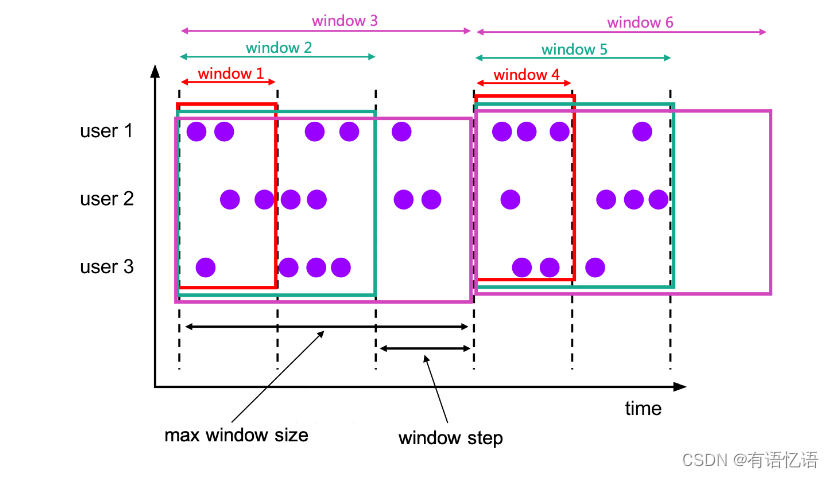
--1. 累计窗口的参数
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
--data: 和时间有关的数据源
--timecol: 时间列,数据的哪些时间属性列应该映射到滚动窗口。
--step: 是指定顺序累积窗口结束之间增加的窗口大小的持续时间。
--size: 是指定累积窗口最大宽度的持续时间。size 必须是 step 的整数倍。
-- offset:可增加其他参数,会有特别的意义
-- 2、例子
> SELECT * FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
> SELECT * FROM TABLE(
CUMULATE(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
STEP => INTERVAL '2' MINUTES,
SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:06 | 2020-04-15 08:05:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:08 | 2020-04-15 08:07:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:08 | 2020-04-15 08:07:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:12 | 2020-04-15 08:11:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:16 | 2020-04-15 08:15:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:16 | 2020-04-15 08:15:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the cumulating windowed table
> SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:06 | 4.00 |
| 2020-04-15 08:00 | 2020-04-15 08:08 | 6.00 |
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:12 | 3.00 |
| 2020-04-15 08:10 | 2020-04-15 08:14 | 4.00 |
| 2020-04-15 08:10 | 2020-04-15 08:16 | 4.00 |
| 2020-04-15 08:10 | 2020-04-15 08:18 | 10.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+
19.4、Window Offset(以上三个窗口函数的可选配置)
Offset是一个可选参数,可用于更改窗口分配。可以是正持续时间,也可以是负持续时间。窗口偏移量的默认值为0。如果设置不同的偏移值,同一条记录可能分配给不同的窗口。
例如,对于一个大小为10分钟的Tumble窗口,哪个窗口将被分配给时间戳为2021-06-30 00:00:04的记录?
- If offset value is -16 MINUTE, the record assigns to window [2021-06-29 23:54:00, 2021-06-30 00:04:00).
- If offset value is -6 MINUTE, the record assigns to window [2021-06-29 23:54:00, 2021-06-30 00:04:00).
- If offset is -4 MINUTE, the record assigns to window [2021-06-29 23:56:00, 2021-06-30 00:06:00).
- If offset is 0, the record assigns to window [2021-06-30 00:00:00, 2021-06-30 00:10:00).
- If offset is 4 MINUTE, the record assigns to window [2021-06-29 23:54:00, 2021-06-30 00:04:00).
- If offset is 6 MINUTE, the record assigns to window [2021-06-29 23:56:00, 2021-06-30 00:06:00).
- If offset is 16 MINUTE, the record assigns to window [2021-06-29 23:56:00, 2021-06-30 00:06:00). We could find that, some windows offset parameters may have same effect on the assignment of windows. In the above case, -16 MINUTE, -6 MINUTE and 4 MINUTE have same effect for a Tumble window with 10 MINUTE as size.
窗口偏移的效果只是更新窗口分配,它对水印没有影响。
在下面的SQL中,我们展示了一个例子来描述如何在Tumble窗口中使用偏移量。
-- NOTE: Currently Flink doesn't support evaluating individual window table-valued function,
-- window table-valued function should be used with aggregate operation,
-- this example is just used for explaining the syntax and the data produced by table-valued function.
Flink SQL> SELECT * FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES, INTERVAL '1' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
Flink SQL> SELECT * FROM TABLE(
TUMBLE(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SIZE => INTERVAL '10' MINUTES,
OFFSET => INTERVAL '1' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the tumbling windowed table
Flink SQL> SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES, INTERVAL '1' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:01 | 2020-04-15 08:11 | 11.00 |
| 2020-04-15 08:11 | 2020-04-15 08:21 | 10.00 |
+------------------+------------------+-------+
20、其他函数
除了上述这些,剩下还有的操作都是和我们的SQL语法差不多,就不再阐述:
窗口聚合函数:group by、…
分组聚合函数:count、having、count(distinct xxx)、…
over聚合函数:over(partition by xxx order by xxx)、…
内外连接函数:join、left join 、outer join、…
limit 函数
TOP-N函数: rank()、dense_rank()、row_number()
flink sql中的窗口函数和我们传统的窗口函数不一样,按理来说,我们正常的窗口函数应该叫over聚合函数。