上一篇文章介绍了一种门控循环神经网络门控循环单元GRU,本文将介绍另一种常用的门控循环神经网络:长短期记忆(long short-term memory,LSTM),它比GRU稍复杂一点。
本文将介绍其实现方法,并使用其进行歌曲的训练与创作。
目录
- 1 长短期记忆介绍
- 1.1 输入门、遗忘门和输出门
- 1.2 候选记忆细胞
- 1.3 记忆细胞
- 1.4 隐藏状态
- 2 读取数据集
- 3 从零实现长短期记忆网络并进行歌词训练与预测
- 3.1 初始化模型参数
- 3.2 定义模型
- 3.3 训练模型并创作歌词
- 4 基于Pytorch的nn.LSTM模块实现歌词训练与预测
- 总结
1 长短期记忆介绍
LSTM 中引入了3个门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及与隐藏状态形状相同的记忆细胞(某些文献把记忆细胞当成一种特殊的隐藏状态),从而记录额外的信息。
1.1 输入门、遗忘门和输出门
与门控循环单元中的重置门和更新门一样,如下图所示,长短期记忆的门的输入均为当前时间步输入 X t \boldsymbol{X}_t Xt与上一时间步隐藏状态 H t − 1 \boldsymbol{H}_{t-1} Ht−1,输出由激活函数为sigmoid函数的全连接层计算得到。如此一来,这3个门元素的值域均为 [ 0 , 1 ] [0,1] [0,1]。
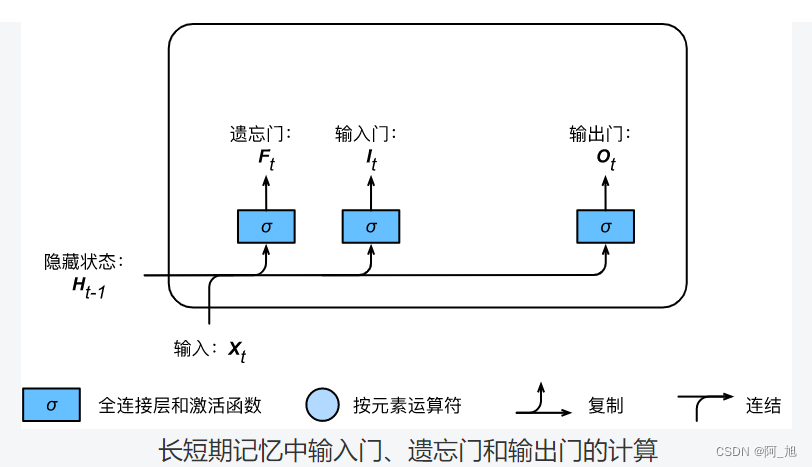
具体来说,假设隐藏单元个数为
h
h
h,给定时间步
t
t
t的小批量输入
X
t
∈
R
n
×
d
\boldsymbol{X}_t \in \mathbb{R}^{n \times d}
Xt∈Rn×d(样本数为
n
n
n,输入个数为
d
d
d)和上一时间步隐藏状态
H
t
−
1
∈
R
n
×
h
\boldsymbol{H}_{t-1} \in \mathbb{R}^{n \times h}
Ht−1∈Rn×h。
时间步
t
t
t的输入门
I
t
∈
R
n
×
h
\boldsymbol{I}_t \in \mathbb{R}^{n \times h}
It∈Rn×h、遗忘门
F
t
∈
R
n
×
h
\boldsymbol{F}_t \in \mathbb{R}^{n \times h}
Ft∈Rn×h和输出门
O
t
∈
R
n
×
h
\boldsymbol{O}_t \in \mathbb{R}^{n \times h}
Ot∈Rn×h分别计算如下:
I t = σ ( X t W x i + H t − 1 W h i + b i ) , F t = σ ( X t W x f + H t − 1 W h f + b f ) , O t = σ ( X t W x o + H t − 1 W h o + b o ) , \begin{aligned} \boldsymbol{I}_t &= \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xi} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hi} + \boldsymbol{b}_i),\\ \boldsymbol{F}_t &= \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xf} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hf} + \boldsymbol{b}_f),\\ \boldsymbol{O}_t &= \sigma(\boldsymbol{X}_t \boldsymbol{W}_{xo} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{ho} + \boldsymbol{b}_o), \end{aligned} ItFtOt=σ(XtWxi+Ht−1Whi+bi),=σ(XtWxf+Ht−1Whf+bf),=σ(XtWxo+Ht−1Who+bo),
其中的 W x i , W x f , W x o ∈ R d × h \boldsymbol{W}_{xi}, \boldsymbol{W}_{xf}, \boldsymbol{W}_{xo} \in \mathbb{R}^{d \times h} Wxi,Wxf,Wxo∈Rd×h和 W h i , W h f , W h o ∈ R h × h \boldsymbol{W}_{hi}, \boldsymbol{W}_{hf}, \boldsymbol{W}_{ho} \in \mathbb{R}^{h \times h} Whi,Whf,Who∈Rh×h是权重参数, b i , b f , b o ∈ R 1 × h \boldsymbol{b}_i, \boldsymbol{b}_f, \boldsymbol{b}_o \in \mathbb{R}^{1 \times h} bi,bf,bo∈R1×h是偏差参数。
1.2 候选记忆细胞
接下来,长短期记忆需要计算候选记忆细胞 C ~ t \tilde{\boldsymbol{C}}_t C~t。它的计算与上面介绍的3个门类似,但使用了值域在 [ − 1 , 1 ] [-1, 1] [−1,1]的tanh函数作为激活函数,如下图所示。
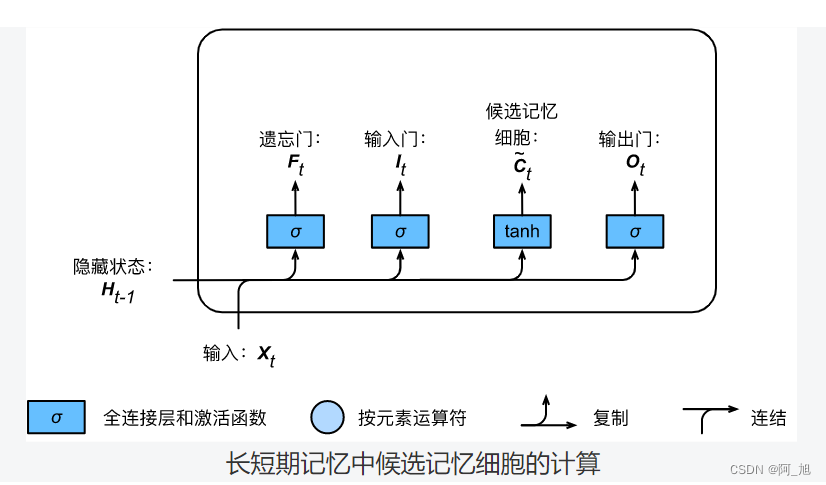
具体来说,时间步 t t t的候选记忆细胞 C ~ t ∈ R n × h \tilde{\boldsymbol{C}}_t \in \mathbb{R}^{n \times h} C~t∈Rn×h的计算为
C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) , \tilde{\boldsymbol{C}}_t = \text{tanh}(\boldsymbol{X}_t \boldsymbol{W}_{xc} + \boldsymbol{H}_{t-1} \boldsymbol{W}_{hc} + \boldsymbol{b}_c), C~t=tanh(XtWxc+Ht−1Whc+bc),
其中 W x c ∈ R d × h \boldsymbol{W}_{xc} \in \mathbb{R}^{d \times h} Wxc∈Rd×h和 W h c ∈ R h × h \boldsymbol{W}_{hc} \in \mathbb{R}^{h \times h} Whc∈Rh×h是权重参数, b c ∈ R 1 × h \boldsymbol{b}_c \in \mathbb{R}^{1 \times h} bc∈R1×h是偏差参数。
1.3 记忆细胞
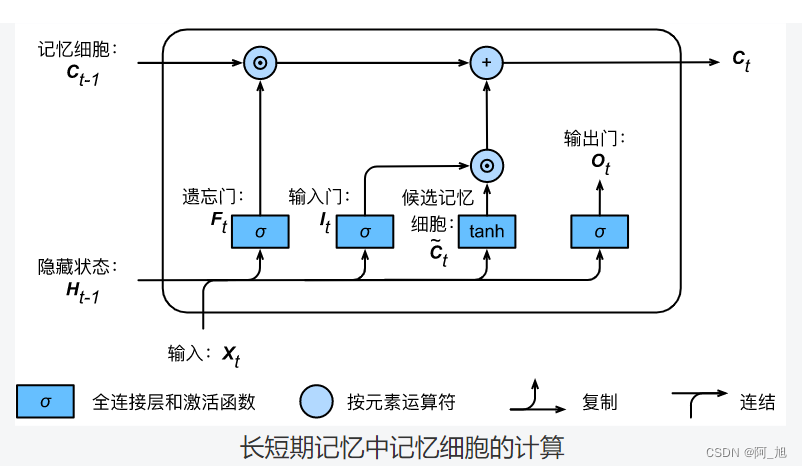
我们可以通过元素值域在 [ 0 , 1 ] [0, 1] [0,1]的输入门、遗忘门和输出门来控制隐藏状态中信息的流动,这一般也是通过使用按元素乘法(符号为 ⊙ \odot ⊙)来实现的。当前时间步记忆细胞 C t ∈ R n × h \boldsymbol{C}_t \in \mathbb{R}^{n \times h} Ct∈Rn×h的计算组合了上一时间步记忆细胞和当前时间步候选记忆细胞的信息,并通过遗忘门和输入门来控制信息的流动:
C t = F t ⊙ C t − 1 + I t ⊙ C ~ t . \boldsymbol{C}_t = \boldsymbol{F}_t \odot \boldsymbol{C}_{t-1} + \boldsymbol{I}_t \odot \tilde{\boldsymbol{C}}_t. Ct=Ft⊙Ct−1+It⊙C~t.
如下图所示,遗忘门控制上一时间步的记忆细胞 C t − 1 \boldsymbol{C}_{t-1} Ct−1中的信息是否传递到当前时间步,而输入门则控制当前时间步的输入 X t \boldsymbol{X}_t Xt通过候选记忆细胞 C ~ t \tilde{\boldsymbol{C}}_t C~t如何流入当前时间步的记忆细胞。如果遗忘门一直近似1且输入门一直近似0,过去的记忆细胞将一直通过时间保存并传递至当前时间步。这个设计可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。
1.4 隐藏状态
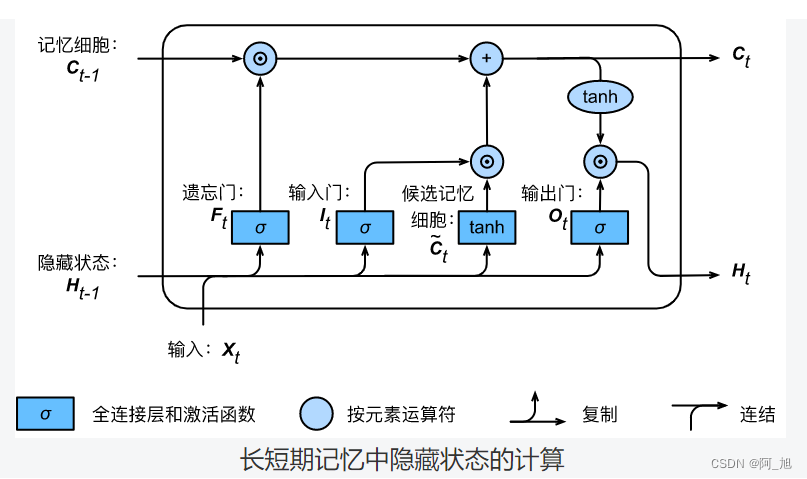
有了记忆细胞以后,接下来我们还可以通过输出门来控制从记忆细胞到隐藏状态 H t ∈ R n × h \boldsymbol{H}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h的信息的流动:
H t = O t ⊙ tanh ( C t ) . \boldsymbol{H}_t = \boldsymbol{O}_t \odot \text{tanh}(\boldsymbol{C}_t). Ht=Ot⊙tanh(Ct).
这里的tanh函数确保隐藏状态元素值在-1到1之间。需要注意的是,当输出门近似1时,记忆细胞信息将传递到隐藏状态供输出层使用;当输出门近似0时,记忆细胞信息只自己保留。下图展示了长短期记忆中隐藏状态的计算。
2 读取数据集
为了实现并展示长短期记忆网络(long short-term memory,LSTM),下面依然使用上一篇文章中的周杰伦歌词专辑数据集来训练模型作词。
数据集获取参见第34篇文章《【从零开始学习深度学习】34. Pytorch-RNN项目实战:RNN创作歌词案例–使用周杰伦专辑歌词训练模型并创作歌曲【含数据集与源码】》。
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = load_data_jay_lyrics('./RNN-JayZhou/jaychou_lyrics.txt.zip')
3 从零实现长短期记忆网络并进行歌词训练与预测
3.1 初始化模型参数
对模型参数进行初始化,超参数num_hiddens定义了隐藏单元的个数。
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xi, W_hi, b_i = _three() # 输入门参数
W_xf, W_hf, b_f = _three() # 遗忘门参数
W_xo, W_ho, b_o = _three() # 输出门参数
W_xc, W_hc, b_c = _three() # 候选记忆细胞参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q])
3.2 定义模型
在初始化函数中,长短期记忆的隐藏状态需要返回额外的形状为(批量大小, 隐藏单元个数)的值为0的记忆细胞。
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
下面根据长短期记忆的计算表达式定义模型。需要注意的是,只有隐藏状态会传递到输出层,而记忆细胞不参与输出层的计算。
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid(torch.matmul(X, W_xi) + torch.matmul(H, W_hi) + b_i)
F = torch.sigmoid(torch.matmul(X, W_xf) + torch.matmul(H, W_hf) + b_f)
O = torch.sigmoid(torch.matmul(X, W_xo) + torch.matmul(H, W_ho) + b_o)
C_tilda = torch.tanh(torch.matmul(X, W_xc) + torch.matmul(H, W_hc) + b_c)
C = F * C + I * C_tilda
H = O * C.tanh()
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H, C)
3.3 训练模型并创作歌词
同上一节一样,我们在训练模型时只使用相邻采样。设置好超参数后,我们将训练模型并根据前缀“分开”和“不分开”分别创作长度为50个字符的一段歌词。
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
我们每过40个迭代周期便根据当前训练的模型创作一段歌词。
d2l.train_and_predict_rnn(lstm, get_params, init_lstm_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
输出:
epoch 40, perplexity 210.213021, time 2.80 sec
- 分开 我不的 我不 我不的 我不的 我不的 我不的 我不的 我不的 我不的 我不的 我不的 我不的 我不
- 不分开 我不的我 我不的 我不 我不的 我不的 我不的 我不的 我不的 我不的 我不的 我不的 我不的 我
epoch 80, perplexity 65.762053, time 2.82 sec
- 分开 我想你你的你 我想想你你的你 我想要你 我不要 我不要 我不要 我不要 我不要 我不要 我不要 我
- 不分开 我想你你的你 我想想你你的你 我想要你 我不要 我不要 我不要 我不要 我不要 我不要 我不要 我
epoch 120, perplexity 15.044255, time 2.37 sec
- 分开 我想你的爱笑 你想你的你笑 想想你的生活 爱爱你 你爱我 我想要这样 你你的话面面你开龙卷风 不
- 不分开 你有你的话我有妈 难散 你想你的太笑 像 你想你很很久 想这样的生笑 我爱你 你爱我 我想要这样
epoch 160, perplexity 4.358501, time 2.82 sec
- 分开 我想的回斯坦堡 想想 却又再考倒我 想散 你想很久了吧? 我 想和你的黑笑 我想要你样活 每天歌一
- 不分开 你已经 说不么 我想就这样牵着你的手不放开 爱可不可以简简单单没有伤害 你 靠着我的肩膀 你 在我
4 基于Pytorch的nn.LSTM模块实现歌词训练与预测
在Pytorch中我们可以直接调用rnn模块中的LSTM类。
lr = 1e-2 # 注意调整学习率
lstm_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(lstm_layer, vocab_size)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
输出:
epoch 40, perplexity 1.022743, time 1.39 sec
- 分开始打呼 管家是一只会说法语举止优雅的猪 吸血前会念约翰福音做为弥补 拥有一双蓝色眼睛的凯萨琳公主 专
- 不分开 我不能再想 我不 我不 我不能 爱情走的太快就像龙卷风 不能承受我已无处可躲 我不要再想 我不要再
epoch 80, perplexity 1.066224, time 1.63 sec
- 分开始打呼 管家是一只会说法语举止优雅的猪 吸血前会念约翰福音做为弥补 拥有一双蓝色眼睛的凯萨琳公主 专
- 不分开 我不能 爱情走的太快就像龙卷风 不能承受我已无处可躲 我不要再想 我不要再想 我不 我不 我不要再
epoch 120, perplexity 1.015384, time 1.59 sec
- 分开的爱写在西元前 深埋在美索不达米亚平原 几十个世纪后出土发现 泥板上的字迹依然清晰可见 我给你的爱写
- 不分开 我不能再想 我不 我不 我不能 爱情走的太快就像龙卷风 不能承受我已无处可躲 我不要再想 我不要再
epoch 160, perplexity 1.010300, time 1.12 sec
- 分开始爱写在西元前 深埋在美索不达米亚平原 几十个世纪后出土发现 泥板上的字迹依然清晰可见 我给你的爱写
- 不分开 爱能不能够永远单纯没有悲哀 我 想带你骑单车 我 想和你看棒球 想这样没担忧 唱着歌 一直走 我想
总结
- 长短期记忆的隐藏层输出包括隐藏状态和记忆细胞。只有隐藏状态会传递到输出层。
- 长短期记忆的输入门、遗忘门和输出门可以控制信息的流动。
- 长短期记忆可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。
如果文章内容对你有帮助,感谢点赞+关注!
关注下方GZH:阿旭算法与机器学习,可获取更多干货内容~欢迎共同学习交流