问答系统
- 问答系统概述
- 问答系统定义
- 问答(QA)系统发展历程
- 问答系统分类:
- 问答系统框架:
- 内容提要
- 专家系统
- 检索式问答系统
- 1.问题分析
- 主要功能:问题分类 和 关键词提取
- 问题分类实现方法
- 2.关键词提取
- 检索模块
- 相关文档检索
- 句段检索
- 3. 答案抽取模块
- 检索式问答实现方式
- 流水线方式
- Document Retriever
- Document Reader
- 流水线方式小结
- 端到端方式
- Retriever-Reader的联合学习
- 基于预训练的Retriever-Free方法
- 社区问答系统
- 问题分析
- 信息检索部分
- 答案抽取部分
- 社区问答的特点:
- 社区问答的优势:
- 知识库问答系统
- 知识库问答任务:
- 技术挑战:
- 解决方法
- 最新研究方向:融合文本和知识图谱的问答
- 知识图谱问答的优势
- 知识图谱问答的局限性
问答系统概述
问答系统定义
问答系统(QA)是一个人与计算机交互的过程。其中包括了解用户的需求,(通常以自然语言查询语句表示);从选定的资源中检索相关的文档、数据或知识,产生相应答案并以有效的方式回答问题
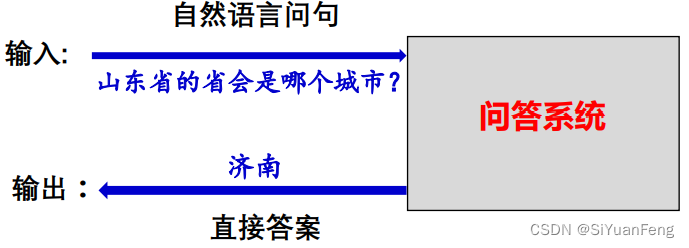
问答(QA)系统发展历程

- 从完成简单任务向复杂任务发展
- 从有限领域向开放领域发展
- 研究范围越来越广泛
问答系统分类:
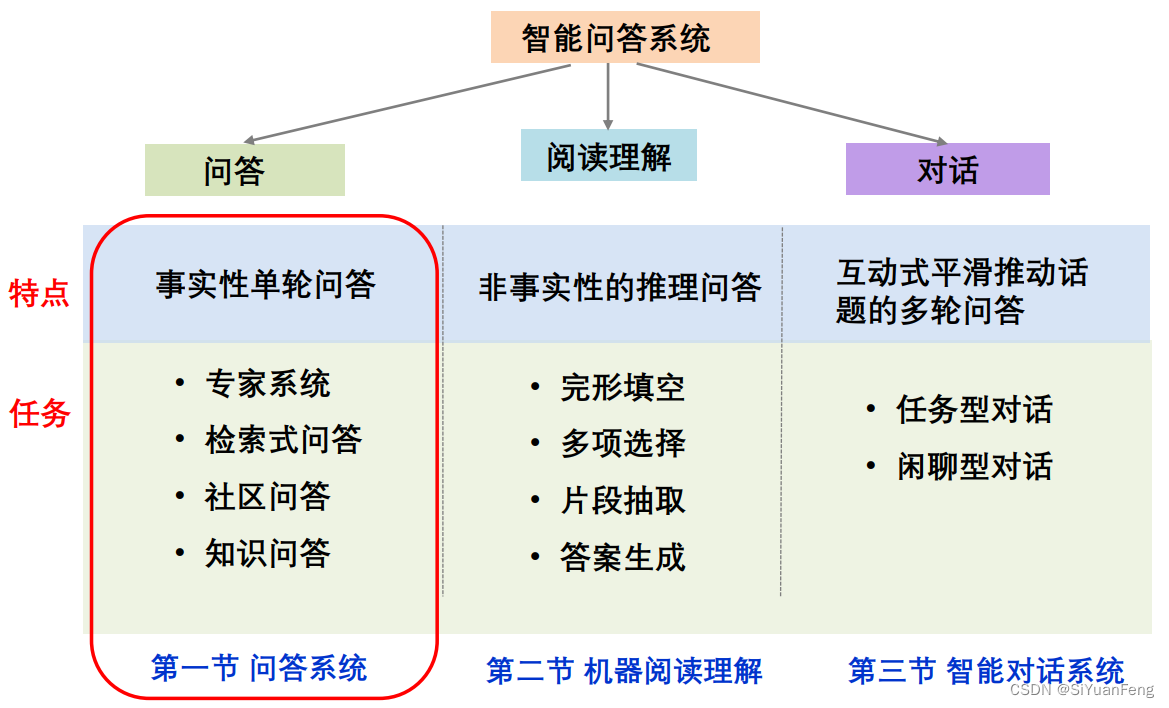
问答系统框架:
特点:提问为事实性问题,单轮问答 (查找答案)
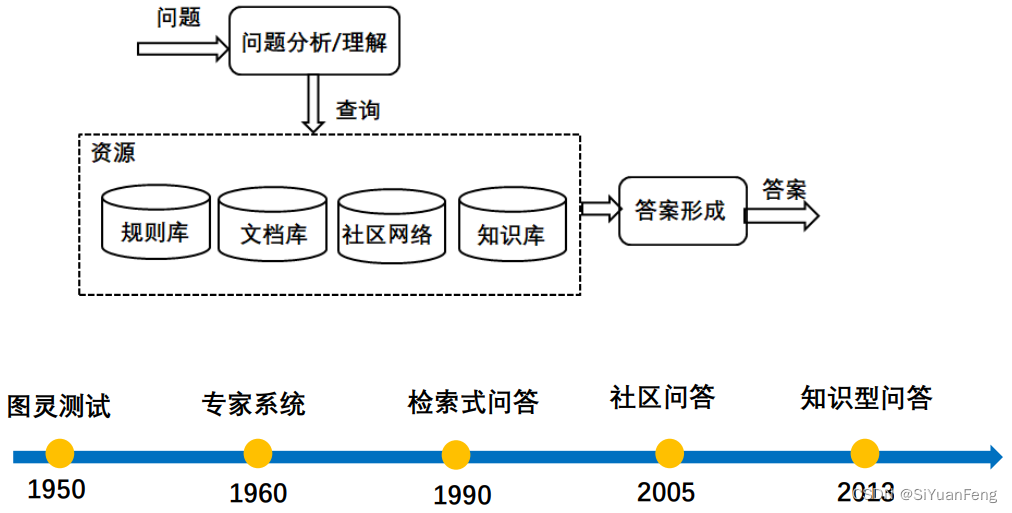
- 问题理解:
对给定的问题进行分析,得到问题句子成分信息、所属类别和潜在答案类型等信息 - 资源分析:
根据问题分析得到的结果信息 在已有的数据集中获得可能含有答案的数据。 - 答案形成:
在得到候选答案集中采用各种技术抽取或生成答案并返回给用户
在问答系统的不同发展阶段,对于这三个基本问题的解决方法随着数据资源的变化在不断变化,从而形成了不同类型的问答系统
内容提要
- 专家系统
- 检索式问答系统
- 社区问答系统
- 知识库问答系统 (重点复习内容)
专家系统
-
特点
问题限定领域;数据基于结构化领域知识数据。它们的后台有一个数据库,保存系统可提供的各种数据。而在用户提问时,系统把用户的问题转换成SQL查询语句,从数据库中查询到数据提供给用户。 -
构建系统关键:
- 需要构建一个特定领域的比完备的结构数据库
- 能准确、高效地把问题转化为查询语言形式的查询
-
局限性:
一般只能用在限定领域 -
核心思想:构建一个特定领域的比完备的结构数据库通过分析问题,把问题转化为一个查询(query),然后在结构化数据中进行查询,返回的查询结果即为问题的答案。
早期的两个比较著名的QA系统:
BASEBALL(1961年)和LUNAR(1973年)两个系统在各自特定的领域取得了巨大的成功。
- BASEBALL:可用来回答美国一个季度棒球比赛的时间地点成绩等 自然语言问题
- LUNAR:可帮助地质学家方便的了解、比较和苹果股阿波罗登月计划积累的月球岩石的各种化学分析数
检索式问答系统
特点:
问题领域开放,基于非结构化Web数据;检索内容为简短的词或词组。
- 问题分析:
- 检测问题类型、答案类型、关注点、关系等
- 问题改写为查询,输入搜索引擎
- 文档与段落检索
- 检索相关文档
- 相关文档划分为片段,对片段进行排序
- 答案抽取
- 在相关片段中抽取备选答案
- 对备选答案进行排序
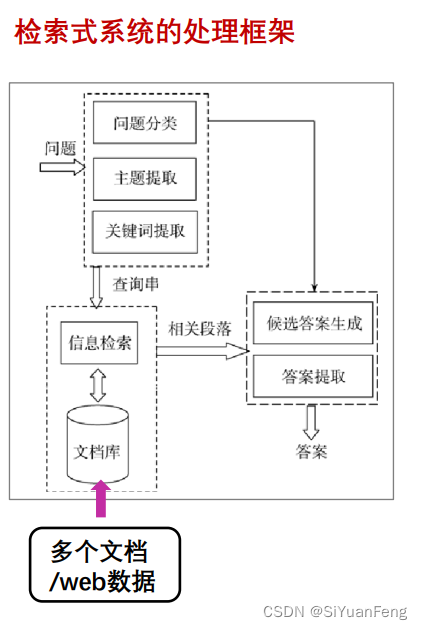 基于大规模文档集的问答系统:信息检索技术和信息抽取技术的结合
基于大规模文档集的问答系统:信息检索技术和信息抽取技术的结合
1.问题分析
主要功能:问题分类 和 关键词提取
- 事实型问题:“谁”、“何时”、“多少”、 “哪里”……
- 定义型问题:“是什么”、“什么是”……
- 复杂型问题:“为什么”、“如何”……
问题分类实现方法
基于规则的方法
- 定义规则模板 : Who {is|was|are|were} Person
- 问题类型词检测 :Which city in China has the largest population?
基于学习的方法(统计法 /深度学习法)
- 定义问题分类
- 标注训练数据的问题类型
- 训练问题类型分类器:问题词/短语、词性、句法树、命名实体等特征
2.关键词提取
根据问题分类,用序列标注法抽取相应类别的实体做为检索关键词
检索模块
主要功能:检索问题答案所在文档与段落
相关文档检索
方法:(文档切分)
- 以连续的n个句子作为一个文档句段
- 以篇章的一个段落(paragraph)为一个文档句段
- 文档进行子话题(subtopic)分割,把一个子话题作为一个句段
句段检索
方法:(特征匹配)
- 句段和问题之间匹配的词的个数
- VSM的余弦相似度
- 深度学习方法(匹配问题)
3. 答案抽取模块
实现方法:( 匹配问题)
• 简单匹配的方法
• 基于表层模式匹配的方法
• 基于多特征的统计机器学习
• 基于深度学习方法
检索式问答实现方式
流水线方式
- 分两步:Document Retriever 和 Document Reader
Document Retriever
- 计算文档的TF-IDF加权的unigram/bigram 向量表示
- 基于问题和文档的向量表示的相似度,对文档排序,选择Top K 文档
Document Reader
特点:将答案抽取转化为抽取式阅读理解问题
- 输入:一个文档段落,一个自然语言描述的问题
- 输出:段落中抽取的答案片段
里面用到的技术:
- Stength-based Re-ranking
- Coverage-based Re-ranking
- Re-ranking combination
流水线方式小结
- Document Retriever + Reading Comprehension Reader框架简化了开放域QA的过程
- 需要进一步探索的方向:
- 多片段全局分析方法
- 片段重排序方法
- 答案重排序方法
- 改进训练过程
端到端方式
• Retriever-Reader的联合学习
• 基于预训练的Retriever-Free方法
Retriever-Reader的联合学习
就是之前说的先Document Retriever再Document Reader
基于预训练的Retriever-Free方法
★ Language Models as Knowledge Bases
• GPT-2是一个在大规模语料训练的基于transformer结构的大型语言模型
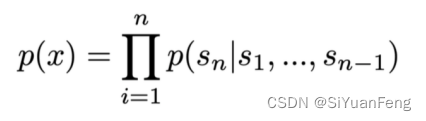
★ How Much Knowledge Can You Pack Into the Parameters of a Language Mode
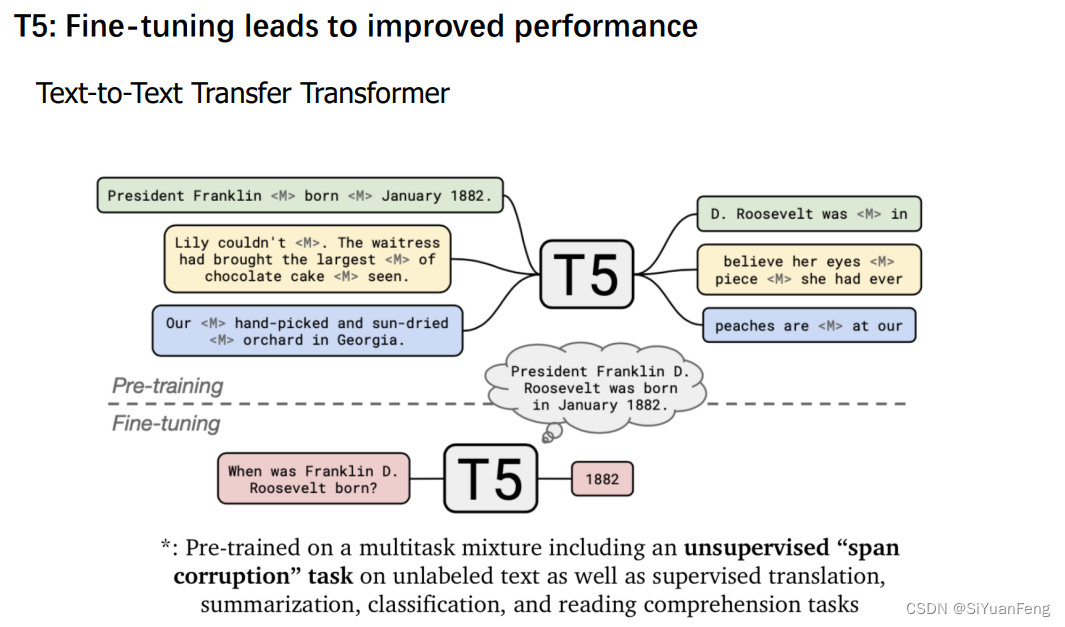
- 在非结构化数据上的大规模预训练模型在不需要检索外部知识的情况下,在开放域QA上获得了和有监督方法匹敌的效果
- 模型效果很大程度上受模型规模的影响
- 如何引入更精准的外部知识和人类经验以进一步提升AI问答能力?(例如:ChatGPT)
社区问答系统
- 社区问答系统
社区问答任务:根据用户所提问题,找到社区中与之相应的答案
- 社区问答包含三个部分:
- 问题分析
- 信息检索部分
- 答案抽取部分
问题分析
在问题分析部分,与问答式检索系统的问题分析部分基本一样,区别在专家系统和问答式检索系统一般都只能处理客观、事实类型的问题。而在社区问答数据中有大量的主观类型的问题,主观问题没有标准答案,而且答案可以多个
信息检索部分
在信息检索部分,与问答式检索系统不同,基于问题答案对的问答系统已经有了问题和对应的答案,不必在文本中搜寻答案,因此在检索部分只需找到和问题类似的问题,然后返回答案或者相似问题列表即可。
- 关键问题:
(1)问题对的检索模型
(2)问题答案对的相似性判断
(1)问题对的检索模型
- 在经过问题分析之后,需要通过信息检索部分把相关的问题检索出来,然后才能在答案抽取部分抽取合适的答案。
(2) 问题答案对的相似性 - 把与给定问题相似的问题找到,然后再在相似的问题中寻找最好的答案。
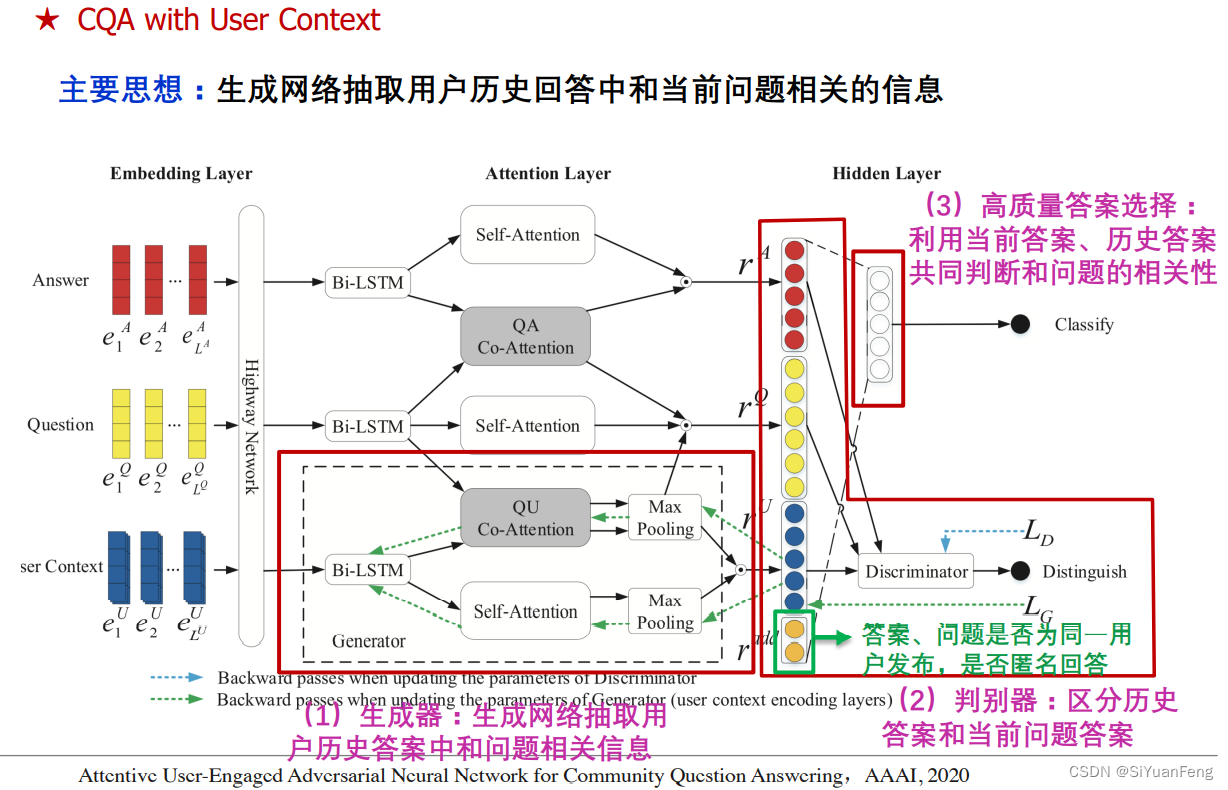
答案抽取部分
在答案抽取部分,由于问题答案对已经有了答案,答案抽取最重要的工作就是判断答案的质量。
答案选择的主要研究问题:
- 问题:答案间的文本匹配问题
- 挑战:问题句子通常较短,答案通常较长,包含大量的噪声和冗余信息,与问题相关的信息十分稀疏
社区问答的特点:
- 包含丰富的元数据,包括用户类型、问题类型、问题发布时间等
- 问题和答案的文本一般较长,包含大量噪声
- 答案质量差距很大
社区问答的优势:
- 解决个性化、开放域、异构、精确的问题
- 社区用户相比机器能够更精准理解问题、更高质量回答问题
- 不断积累丰富的知识
知识库问答系统
基于知识库(知识图谱)的问答系统
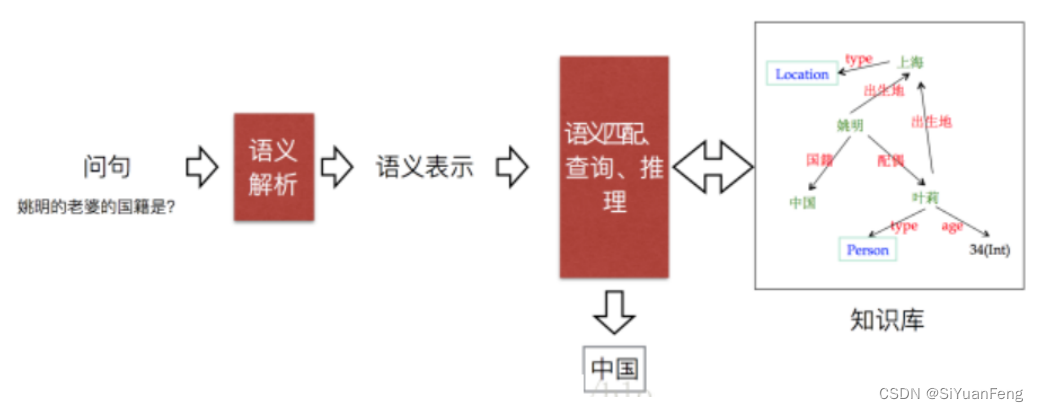
知识库问答任务:
给定自然语言问题,通过对问题进行语义理解和解析,利用知识库进行查询、推理得出答案。
- 问题描述:根据给定问题,在知识图谱中检索/推理相关实体作为答案。
- 特点:回答的答案是知识库中的实体
技术挑战:
- 语言多样性
- 相同问题有多种语言表达方式
- 需要把问题映射到知识图谱的实体上
知识图谱搜索规模大
- 一些freebase中实体包含>160,000邻居
- 大量复合性问题
解决方法
- 语义解析(Semantic Parsing)
偏语言学的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句在知识库中进行查询,从而得出答案。 - 信息抽取(Information Extraction)
通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。 - 向量建模(Vector Modeling)
根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,模型训练完成后则可根据候选答案的向量表达和问题表达的得分进行筛选,得出最终答案。 - 表示学习法
问题主题抽取→ 知识子图抽取 → 知识子图表示 → 问题-知识相关性计算- 优点:不需要定义大量模板,端到端学习
- 不足:回答复杂问题差,缺乏可解释性
最新研究方向:融合文本和知识图谱的问答
- 主要思路
• 通过实体链接关联问题和知识库(文本、知识图谱)中的实体
• 图表示学习进行答案预测 - 代表性工作
• GRAFT-Net [Sun & Dhingra et al., EMNLP 2018]
• Knowledge-aware Reader [Xiong et al., 2019]
★ GRAFT-Net (融合文本和知识图谱的问答)
主要思想:
- 采用文本和知识图谱构建一个异构图
- 采用图神经网络选择异构图上的一个节点作为答案
知识图谱问答的优势
- 人工构建的知识库确保了答案的准确性
- 常识或“简单”问题容易在知识图谱中找到答案
- 如果语义解析(questionàQuey)正确
- 知识图谱的图结构支持多步推理问答
知识图谱问答的局限性
- 依据知识图谱能够回答的问题十分有限
- 只涉及常见的实体与关系
- 知识图谱无法实时更新