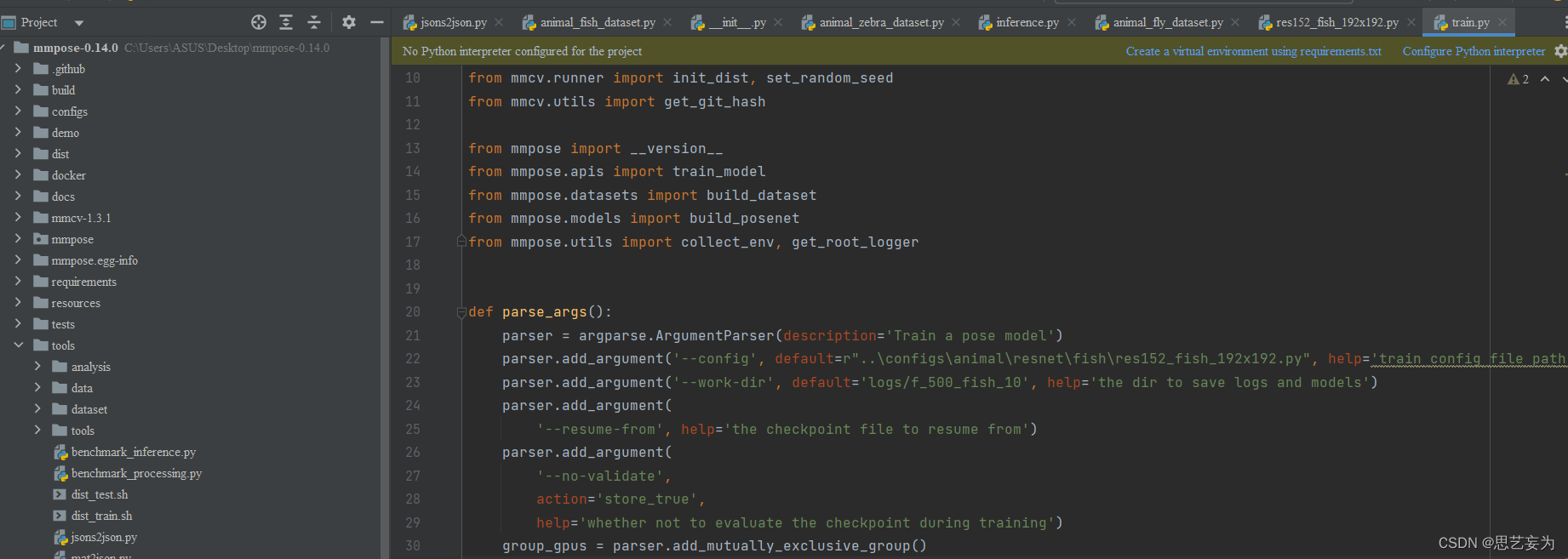
IOU(交并比)
交并比(loU)函数做的是计算两个边界框交集和并集之比。可以用来判断定位算法的好坏。
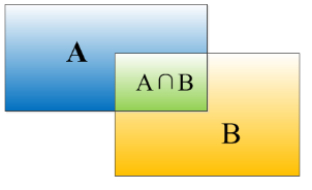
一般来说,IoU大于等于0.5,那么结果是可以接受的,就说检测正确。如果预测器和实际边界框完美重叠,loU就是1,因为交集就等于并集。一般约定,0.5是阈值(threshold),用来判断预测的边界框是否正确。loU越高,边界框越精确。
import cv2
import numpy as np
def CountIOU(RecA, RecB):
xA = max(RecA[0], RecB[0])
yA = max(RecA[1], RecB[1])
xB = min(RecA[2], RecB[2])
yB = min(RecA[3], RecB[3])
# 计算交集部分面积
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
# 计算预测值和真实值的面积
RecA_Area = (RecA[2] - RecA[0] + 1) * (RecA[3] - RecA[1] + 1)
RecB_Area = (RecB[2] - RecB[0] + 1) * (RecB[3] - RecB[1] + 1)
# 计算IOU
iou = interArea / float(RecA_Area + RecB_Area - interArea)
return iou
img = np.zeros((512,512,3), np.uint8)
img.fill(255)
RecA = [50,50,300,300]
RecB = [60,60,320,320]
cv2.rectangle(img, (RecA[0],RecA[1]), (RecA[2],RecA[3]), (0, 255, 0), 5)
cv2.rectangle(img, (RecB[0],RecB[1]), (RecB[2],RecB[3]), (255, 0, 0), 5)
IOU = CountIOU(RecA,RecB)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,"IOU = %.2f"%IOU,(130, 190),font,0.8,(0,0,0),2)
cv2.imshow("image",img)
cv2.waitKey()
cv2.destroyAllWindows()
mAP相关概念
什么是TP,FP,FN,TN
假设分类目标只有两类,分别为P(正例)和N(负例)
TP:预测为P,且实际也为P
FP:预测为P,实际为N(预测出错的)
FN:预测为N,实际为P(预测出错的)
TN:预测为N,实际也为N
从上面的这些符号可以总结,前面的T\F表示预测的准确性,后面的P/N表示预测的类别。
P(精确率)
precision = TP/(TP+FP)
首先看分母,表示的模型预测为正例的个数。精确率表示模型预测正例中正确的个数。举个例子,模型预测100个样本,98个样本预测对了,所以精确率表示了模型的预测能力,精确率越高,模型的性能就越好。精确率更侧重于衡量模型的正例样本预测是否可靠(不能错杀)。
R(召回率)
Recall = TP/(TP+FN)
首先看分母,表示的是数据中正例的个数。召回率表示模型在这个数据集上的表现能力。举个例子,数据集中有100个正例样本,模型预测正例样本的个数为98个,还有2个样本模型预测不出来。召回率更侧重于衡量实际的正例样本是否被遗漏(不能漏杀)。
精确率和召回率:分子都是模型预测正例且正确的个数,分母不一样。精确率的分母表示的模型预测正例的个数,召回率的分母表示数据集实际的正例的个数。所以精确率可以表示模型的预测能力,精确率越高,表示模型的性能就越好。召回率表示的是模型在数据集上的实际情况,也可以认为是模型的泛化性能。
还可以这样认为:

精确率和召回率的分母只有上面的两个错误类型是不同的。 在实际应用中,两个样本出错的代价应该是不同的,假设FP的代价比较高(预测为苹果,实际上是西瓜,那么这种代价就比较高),所以我们可以提高模型的精确率。
ACC(准确率)
ACC = (TP+TN)/(TP+FP+TN+FN)
准确率常被用于衡量一个机器学习模型的综合性能。但是在实际中,样本经常是不均衡的。
AP(平均精确度)
AP 表示的是PR曲线下的面积。