毕设题目为人体姿态估计,之前主要关注在目标检测上,这方面不太熟悉,于是想做一个系列专栏,从0到1学习姿态估计。

参考于大佬-同济子豪兄
姿态估计本质是关键点检测。
人体姿态的估计常常首先预测出人体各个关键点的位置坐标,然后根据先验知识确定关键点之间的空间位置关系,从而得到预测的人体骨架。
2D姿态估计
2D姿态估计就是为每个关键点预测一个二维坐标;


不光是人,所有动物或其他任何物体,只要有关键点的都使用姿态估计

https://github.com/DeepLabCut/DeepLabcut
这个库就是一个动物姿态估计的开源框架,通过少量的标注,即可训练自己的模型。


关键点检测的应用非常之多,如下是检测人的耳朵,将自己耳朵上的穴位准确的定位出来,然后根据提示贴上耳贴。

下面是子豪兄大佬开发的运动检测
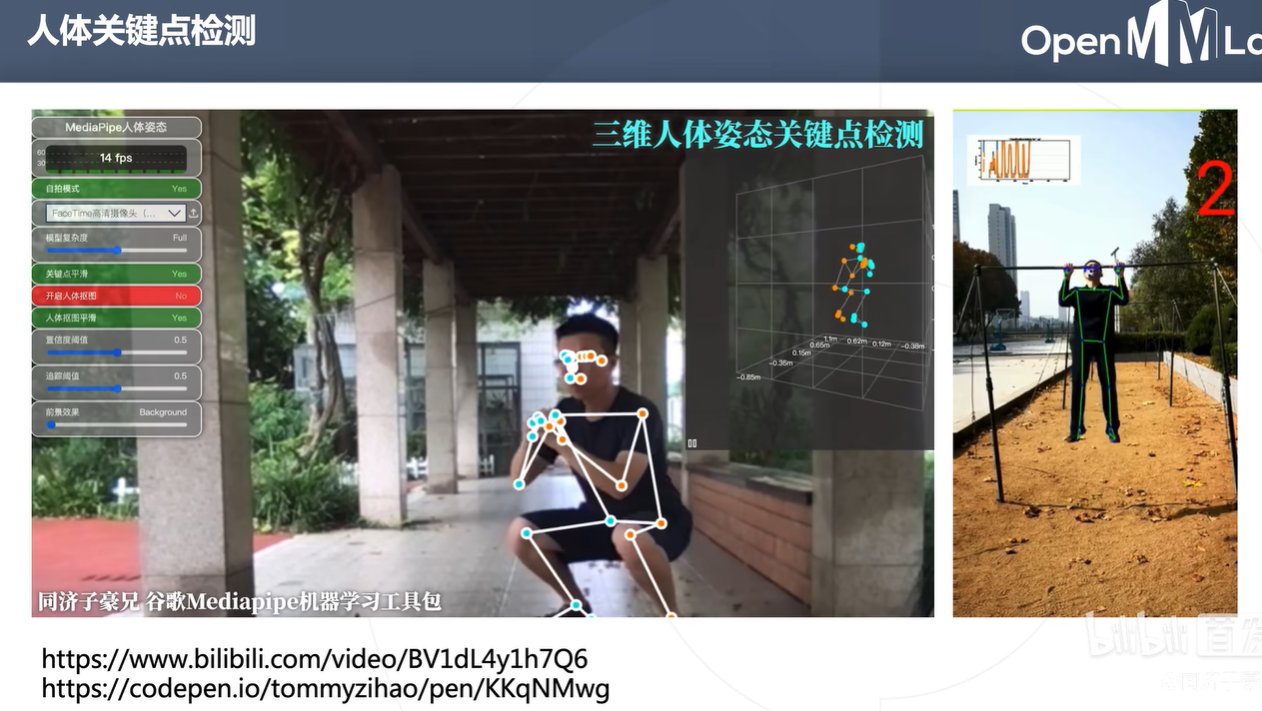
通过人体关键点检测可以进行音量控制,隔空点击等有趣的操作。

下面是识别人脸,比如检测到人脸关键点后,在相关位置画上一个迷宫,再添加一个物理引擎,即可控制走迷宫。
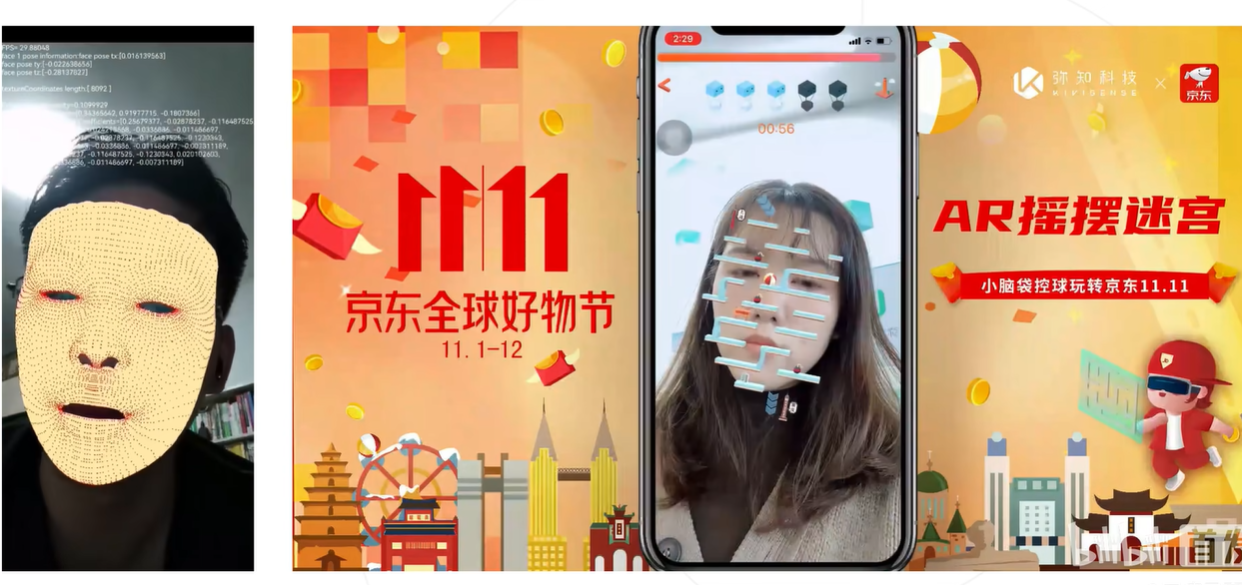
这个是自己摆个姿势,从模型库中挑选一个有累死姿势的图像

3D姿态检测
3D姿态检测比2D的增加了一维深度信息,每个关键点预测一个三维坐标。
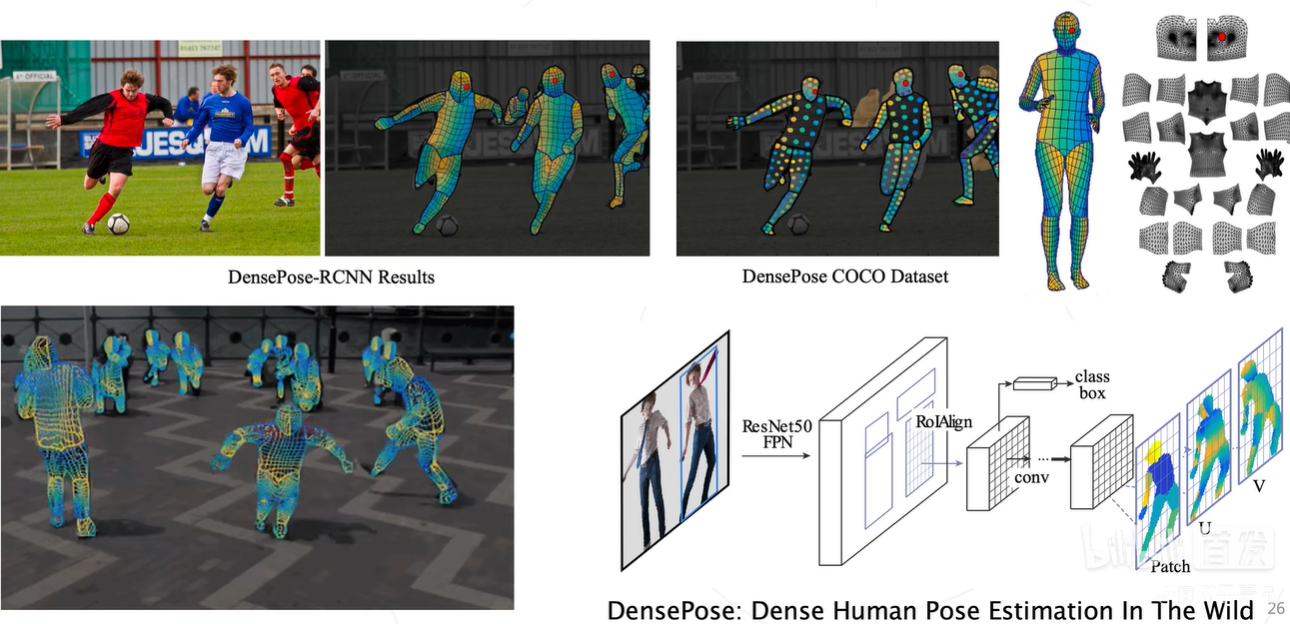

视频行为理解也属于3D的,只是空间上一个坐标给了时间。


综上所述,姿态检测的场景非常多。
https://www.v7labs.com/blog/human-pose-estimation-guide
这篇文章写的很好很基础,之后我会将其翻译成中文
https://www.analyticsvidhya.com/blog/2022/01/a-comprehensive-guide-on-human-pose-estimation/
与上面文章差不多

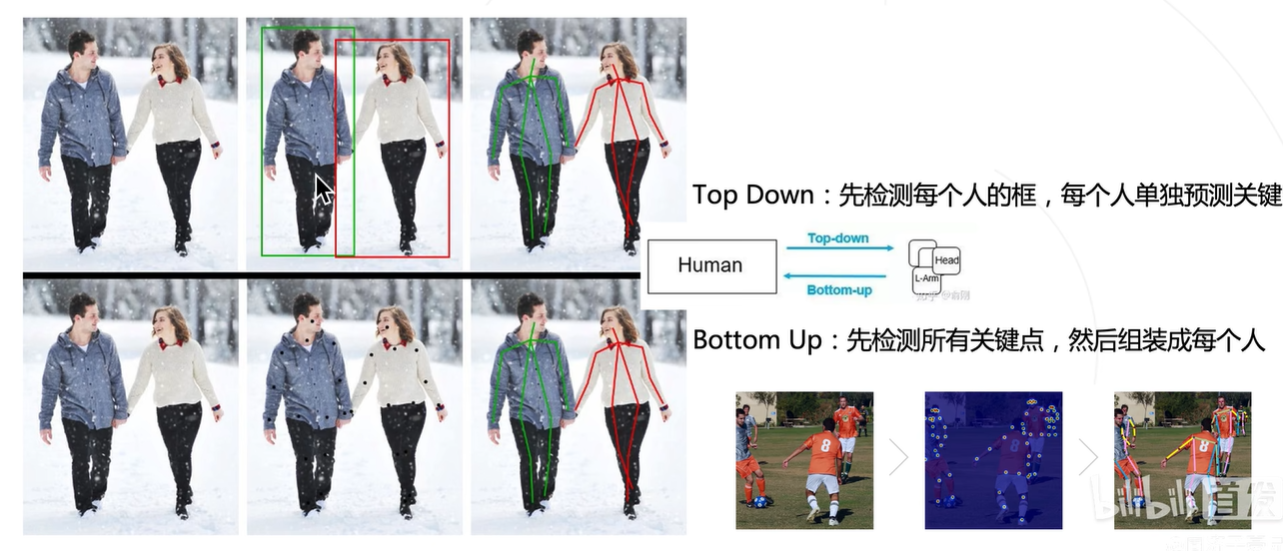
多目标姿态检测主要有两种方式,一种是自顶向下的(Top Down):即先检测目标框,再检测目标框内的关键点;另一种是定下而上的(Bottle Up):即先检测关键点,再根绝关键点分离出目标。
再关键点检测时,主要用基于热力图和回归两种方式

再没有用深度学习时,专家们一般是根据人体的姿态位置特征建一个弹簧模型,当然这种模型鲁棒性非常差,一般换一个角度深知换一个光照强度就不work了。
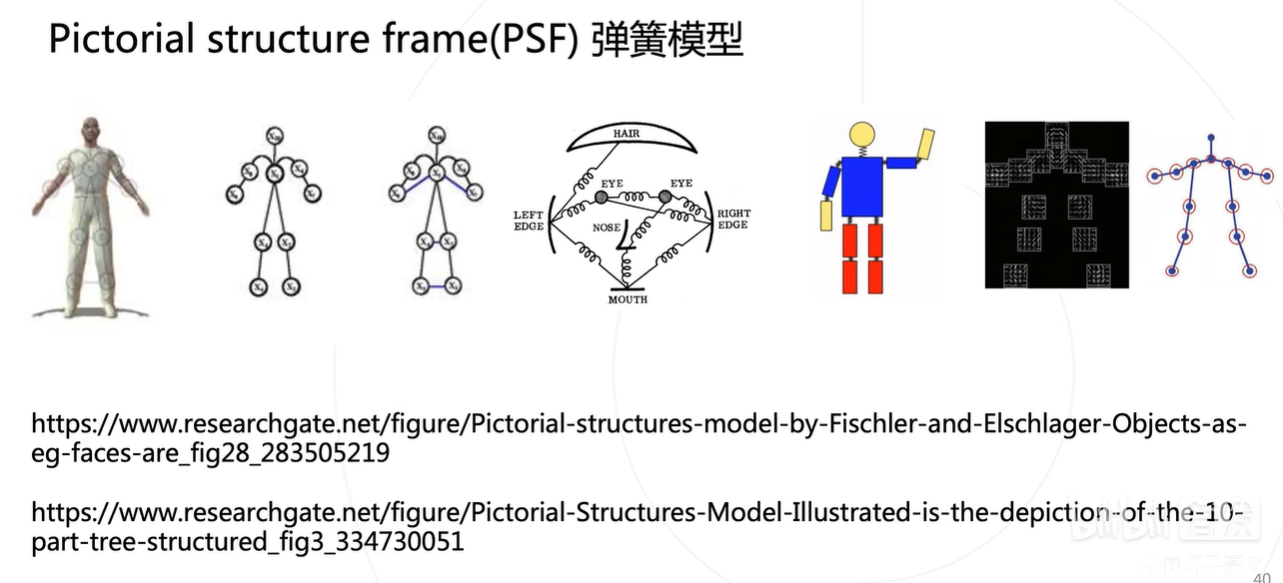

目前主要是用高分辨率卷积神经网络
姿态估计加上sort算法可以进行多目标跟踪

也可以将多个姿态检测组合在一块生成一种模型

这个是通过2D图像,进行姿态估计,然后预测\映射到三维空间