一、LinkedList的概述
1. LinkedList是双向链表实现的List
2. LinkedList是非线程安全的
3. LinkedList元素允许为null,允许重复元素
4. LinkedList是基于链表实现的,因此插入删除效率高,查找效率低(虽然有一个加速动作)
5. LinkedList是基于链表实现的,因此不存在容量不足的问题,所以没有扩容的方法
6. LinkedList还实现了栈和队列的操作方法,因此也可以作为栈、队列和双端队列来使用。推荐了解java培训课程。

二、LinkedList的分析
2.1LinkedList的存储结构
LinkedList是由双链表的数据结构组成的
public class LinkedList{
// 元素个数
transient int size = 0;
/**
* 指向第一个节点的指针
* 不变性:
* 1. 如果first = null,则last=null
* 2. 如果first.prev == null,则first.item != null
*/
transient Node<E> first;
/**
* 指向最后一个节点的指针
* 不变性:
* 1. 如果first = null,则last = null
* 2. 如果last.next == null,则last.item != null
*/
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next; // 下一个Node的引用
Node<E> prev; // 上一个Node的引用
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
/**
* 创建一个空list
* */
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
}

2.2添加元素
2.2.1从头部添加
// 从头插入
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null) // 当前List中没有元素,size=0
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}

2.2.2从尾部添加
public boolean add(E e) {
linkLast(e);
eturn true;
}
public void addLast(E e) {
linkLast(e);
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)// 当前List中没有元素,size=0
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}

2.3.删除节点
2.3.1从头部删除
// 移除首节点,并返回该节点的元素值
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// 删除首节点f
private E unlinkFirst(Node<E> f) {
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null) // size=1
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}

2.3.2从尾部移除
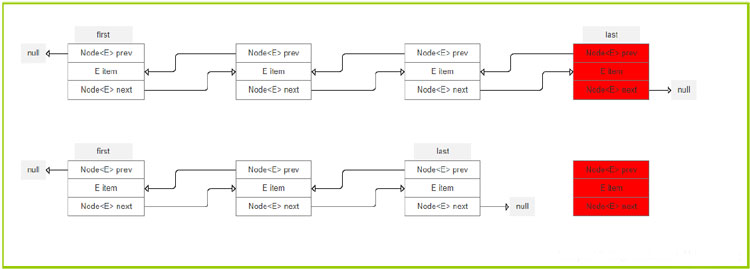
2.3.3根据索引移除
public E remove(int index) {
checkElementIndex(index);// 检查索引index范围
return unlink(node(index));
}
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {// x为首节点
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {// x为尾节点
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
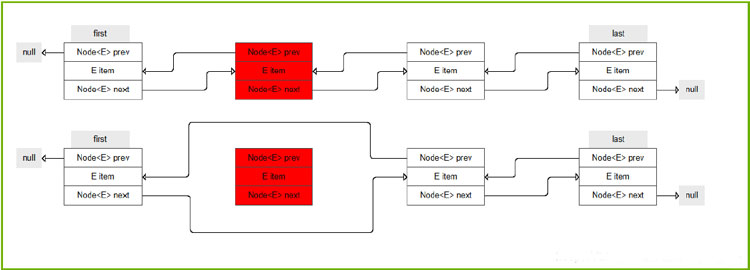
2.4获取节点数据
2.4.1获取头部数据
// 获取首节点的数据
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
2.4.2获取尾部数据
// 获取尾节点的数据
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
2.4.3根据索引获取节点数据
// 获取索引对应节点的数据
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 类似折半查找
Node<E> node(int index) {
if (index < (size >> 1)) {// 从前半部分查找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {// 从后半部分查找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
三、总结:LinkedList和ArrayList的比较
1. 顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只要往指定位置塞一个数据就好了
2. LinkedList则不同,每次顺序插入的时候LinkedList将new一个对象出来,如果对象比较大,那么new的时间势必会长一点,再加上一些引用赋值的操作,所以顺序插入LinkedList必然慢于ArrayList
3. ArrayList的遍历效率会比LinkedList的遍历效率高一些
4. LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Node的引用地址
5. ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址
(1) 如果确定插入、删除的元素是在前半段,那么就使用LinkedList
(2) 如果确定插入、删除的元素在比较靠后的位置,那么可以考虑使用ArrayList
(3) 如果不能确定插入、删除是在哪儿呢?建议使用LinkedList,
·一来LinkedList整体插入、删除的执行效率比较稳定,没有ArrayList这种越往后越快的情况
·二来插入元素的时候,弄得不好ArrayList就要进行一次扩容,而ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作