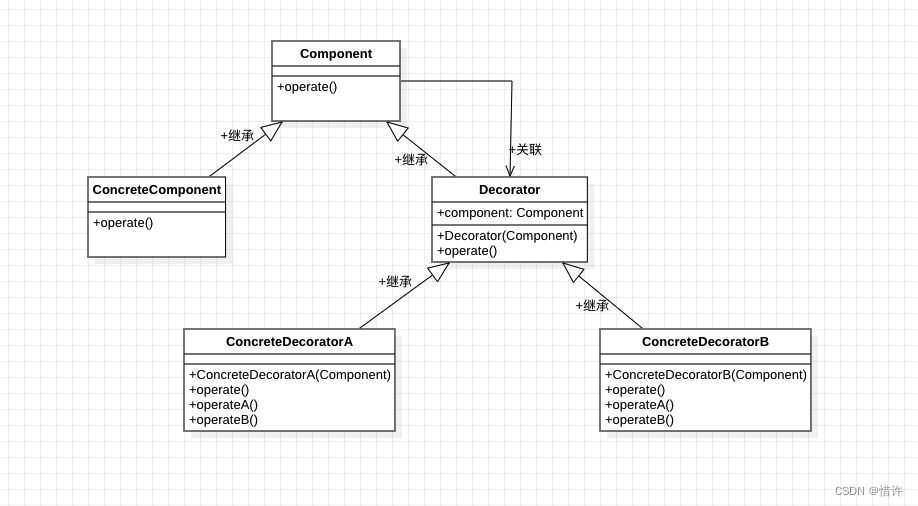
文章目录
- 0. 背景
- 1. 如何理解快照(snapshot)?
- 2. 快照 (snapshot) 的原理
- 2.1 全量快照
- 1. 克隆 (Clone)
- 2. 镜像分离 (Split Mirror)
- 2.2 增量快照
- 1. 写时拷贝(Copy-On-Write)
- **写数据**
- **读数据**
- **优缺点**
- 2. 写时重定向 (Redirect-On-Write)
- **写数据**
- **读数据**
- 优缺点
- 3. Linux 快照 (snapshot)
- 3.1 Linux 快照的原理
- 3.2 COW 设备的结构
- 4. 其它
0. 背景
网上介绍存储快照原理的文章很多,要我说简直是太多了,但大多都只是讲最基础的原理。
我还没有找到一篇可以从基础的原理,落实到随处可见的 linux 中的实现,然后再来一些具体操作例子的文章。
于是我自己产生了写一篇快照科普的想法,希望把快照的基础原理同 linux 下具体的 snapshot 实现结合起来,再来一些操作实验增加对快照的理解。
才写 1/3,就发现这样篇幅太长,于是就把一篇拆分成了现在的两篇,并命名为《Linux 快照 (snapshot) 原理与实践》:
- 第一篇介绍原理,包括:
- 快照基本原理
- Linux 下的快照模型
- 第二篇侧重实践,包括多个 Linux 实验:
- COW 模式下多次写入数据并验证的实验
- ROW 模式下多次写入数据并验证的实验
- 合并 (merge) 操作中 COW 模式和 ROW 模式数据变化的验证
当我把两篇都写完以后才发现仍然有不少问题还没有交代清楚,比如:
- Linux 下快照设备的各种行为关系,
- COW 设备的细节,
- 对驱动代码进行分析,
- 如何对快照设备扩容,
- 如何对快照设备进行调试等。
只不过写作本文的初衷已经达成,所以对 Linux 下快照设备的介绍算是告一段落,至于是否还要继续上面提到的话题,后面看情况吧。
由于网上太多人介绍过快照的基本原理了,所以本篇对快照原理的介绍比较简单,属于一个简要的总结,也没有提及快照的意义,发展和其他话题。如果觉得本篇关于原理的部分介绍得不够详细,请参考我推荐的几篇文章,以及自行搜索。
本篇作为《Linux 快照 (snapshot) 原理与实践》的原理篇:
第 1 节介绍了我对快照的理解,其实我以前对为啥叫快照这个词有些不解,为什么不叫照相,到底什么是快照?要是觉得太废话,请自行跳过。
第 2.1 节总结了两种全量快照方式,感觉应该没啥人用全量快照;
第 2.2 节总结了两种增量快照方式 COW 和 ROW,网上一大堆介绍这个的,我连图都不想画,直接都借用别人的了;
第 3 节介绍了 linux 下的快照模型,本文的精华,应该是目前网上唯一全面介绍 linux 快照细节的文章;
1. 如何理解快照(snapshot)?
snapshot 中文翻译就是快照,但快照究竟是什么? 我在网上看到一个解释,觉得特别准确:
快照 (snapshot),来自照相领域的概念,是指特定时间点的一个状态。
来源: 《Git快照(snapshot)到底该如何理解?》, https://www.h5w3.com/82381.html
所以,
-
当我们拍照时,照片就表示了被拍摄物体在特定时间点的一个状态;
-
当我们使用 git 对版本进行管理时,每个节点(commit, branch, tag)对应一个快照,记录 git 仓库在该节点的状态;
-
当我们对文件系统创建快照时,快照记录了文件系统在该时间点的状态;
快照有什么用呢?
按照《Git快照(snapshot)到底该如何理解?》一文引用的场景:
想象一下,给一张桌子拍一张照片,纪录了桌子上所有物品的位置、状态,这样就可以称之为快照了。
我们不必存储所有的物品,只需存储这个照片就可以了,下一次想恢复以前的状态的时候,只需要翻出当时的那张照片,再把物品按照那张照片里的位置摆放一下就OK了。
–来自V2EX:https://www.v2ex.com/t/124019
所以,对于 git 仓库,只需要将每一个文件的内容恢复到节点时的状态;对于文件系统,只需要将每个 block 的数据恢复到快照时的状态,这样就能完整还原当时的场景了。
在写完这段以后,我特地翻出去看了下维基百科上关于 snapshot 的解释:

**图 1. 维基百科对 snapshot 的解释 **
- 照相术语,一张没有经过准备拍摄下来的照片就叫做 snapshot。
- 计算机存储术语,snapshot 表示系统在某个特定时间点的状态。

图 2. 维基百科对 Snapshot (computer storage) 的解释
进一步解释 snapshot:
在计算机系统中,快照是系统在特定时间点的状态。该术语是作为摄影中的类比而创造的。它可以指系统状态的实际副本或某些系统提供的功能。
简直惊了个呆,对我来说,这里已经简简单单、明明白白地解释了什么是 snapshot,这天杀的墙~
另外,从这里也能看到,snapshot(快照) 和 photography(照相) 有些细微的区别:

图 3. 维基百科对 Snapshot (Photography) 的解释
其实我觉得维基百科中文页面的这个解释更接近我们的理解习惯:

图 4. 维基百科对抓拍的解释
所以,snapshot (快照) 实际上是对系统状态的抓拍,表示了系统在某个特定时间点的状态。
2. 快照 (snapshot) 的原理
这里讨论的快照 (snapshot) 实际上是指存储快照。
关于存储快照的原理,可以参考以下这几篇:
- 百度百科: 《存储快照》
- 博客园文章: 《快照技术解析》, 《探究快照技术》
- 华为企业服务网站: 《COW、ROW 快照技术原理》
前几篇从宏观上说明快照的基本原理,而《COW、ROW快照技术原理》除了讲述原理外,更多地深入一层介绍了 COW 和 ROW 快照的读写操作细节。
有了上面这几篇之后,关于快照的原理其实不需要再啰嗦一遍了。但为了内容的完整性,这里还是再简要说明下,更多详细的内容请参考前面这几篇文章~
按照 SNIA 的定义, 快照有全量快照 (full snapshot) 和增量快照 (incremental snapshot) 两种类型。网上介绍快照原理的文章中提到了多种不同的快照技术:
- 全量快照
- 克隆 (Clone)
- 镜像分离 (Split Mirror)
- 增量快照
- 写时拷贝 COW (Copy-On-Write)
- 写时重定向 ROW (Redirect-On-Write)
2.1 全量快照
1. 克隆 (Clone)
克隆 (Clone) 快照创建的是数据的完整副本,快照的对象可以是一个存储卷、一个文件系统或者一个 LUN,Clone 的优点是具有高可用性,但缺点也很明显,就是在创建的时候,数据要完整的复制一份。
使用克隆 (Clone) 快照需要面对的一个非常严重的问题是每个快照都需要占用和源数据空间一样大的存储空间。尤其对快照需求较大、较多的情况,资源成本会非常高。另外就是创建的时候消耗时间较长。
克隆 (Clone) 快照创建的时刻,系统的所有的操作都会停止,创建一个和源数据空间大小一样的快照空间,将数据完整拷贝到快照空间中,快照完成后,系统恢复正常工作。
这段话来自: https://www.cnblogs.com/zhaochunhui/p/13597675.html
仔细看这段话,跟备份操作一个意思。
2. 镜像分离 (Split Mirror)
镜像分离 (split mirror) 快照也属于全量快照,这种快照方式比较简单,先创建一个源卷的镜像卷,每次磁盘写入数据的时候,都会往源卷和快照卷同时写入内容。当启动快照时,则镜像卷能快速脱离,生成一个快照卷。
简而言之,镜像分离 (split mirror) 快照在读操作时没有任何影响,在写操作时会有两次写入操作,分别是写入源卷与镜像卷。
2.2 增量快照
1. 写时拷贝(Copy-On-Write)
在源卷之外创建一个快照卷,用于存放快照数据。
写数据
在新数据第一次写入到源卷的某个存储位置时:
- 先将原有的内容读取出来,写到快照卷中
- 然后再将新数据写入到源卷的存储设备中。
操作 1 只在第一次写入数据时发生,下次针对这一位置的写操作直接将新数据写入到源卷中,不再执行写时复制操作。

图 5. 写时拷贝 (COW) 模型
图片来源: https://www.cnblogs.com/jing99/p/7446214.html
因此,源卷存放的始终是当前的最新数据。
读数据
如果需要访问某个时间点的快照数据:
- 对没有改变过的块直接从源卷读取
- 对已经改变并被复制的块则从快照卷读取
如果需要访问最新数据,直接从源卷读取。
优缺点
优点:COW 在进行快照操作之前,不会占用任何的存储资源,也不会影响系统性能。
缺点:
-
降低源卷的写性能。当修改源数据时,会发生三次读写操作:
- 读取源数据。
- 将源数据写入快照卷中。
- 将新数据写入源卷中。
如果写入数据频繁,那么这种方式将非常消耗I/O。
-
没有快照完整的物理副本。快照卷仅仅保存了源卷的部分数据。
-
拷贝到快照卷中的数据量超过了保留空间,快照就将失效。
2. 写时重定向 (Redirect-On-Write)
ROW 的实现原理与 COW 非常相似,区别在于 ROW 对源卷的首次写操作,会将新数据重定向到预留的快照卷中。所以,ROW 快照中的原始数据依旧保留在源卷中,并且有些系统为了保证快照数据的完整性,在创建快照时,源卷状态会由读写变成只读。
写数据
在新数据第一次写入到源卷的某个存储位置时,将会被重定向写入到快照卷中。
当数据被再次改写时,系统会给更新过的数据在快照卷中选择一个新的存储位置,前一次写入重定向在快照卷中的数据得以保留,但不会被引用。

图 6. 写时重定向 (ROW) 模型
图片来源: https://www.cnblogs.com/jing99/p/7446214.html
因此,源卷存放的始终是创建快照时的旧数据。
读数据
如果需要访问某个时间点的快照数据,直接从源卷读取。
如果需要访问最新数据:
- 对没有改变过的块直接从源卷读取
- 对已经改变并被重定向的块则从快照卷读取
优缺点
优点:不会降低源卷的写性能。源卷创建快照后的写操作会被重定向,所有的写 I/O 都被重定向到快照卷中,而所有快照数据(旧数据)均保留在源卷中。因此更新数据只需要一个写操作,解决了 COW 写两次的性能问题。
缺点:
-
没有最新数据完整的物理副本。
ROW 的快照卷保存了源卷改动后的新数据,但并不是完整的最新数据副本。因此,当创建了多个快照时,会产生一个快照链,源卷数据的变动追踪以及快照的删除将变得异常复杂。在恢复快照时会不断地合并快照文件,造成较大的系统开销。
-
读性能下降。由于采用了重定向写,使得原本连续的数据分散到了磁盘中,连续写变成了随机写,造成读性能下降。
另外,由于源卷存放的是创建快照时的旧数据,为了让源卷得到更新后的数据,还需要执行一次合并操作,将快照卷中改动后的数据写回到源卷中。
3. Linux 快照 (snapshot)
基于快照的原理,可以有各种具体的实现,这里主要讨论 linux 系统中快照的实现。
3.1 Linux 快照的原理
Linux 下快照 (snapshot) 属于增量快照,基于 Device Mapper 驱动实现,快照设备是 Device Mapper 众多虚拟设备中的一种。
Device Mapper 对 snapshot 的支持,代码位于 drivers/md 目录,文档请考:
Documentation/admin-guide/device-mapper/snapshot.rst
在线版本: https://docs.kernel.org/admin-guide/device-mapper/snapshot.html
如果
Documentation/admin-guide目录不存在,请检查目录Documentation/device-mapper。
如果您不想深入代码,但又希望透彻了解 snapshot,强烈建议参考官方文档。因为这是一手资料,网上所有其它解读都是二手了,包括本篇。
不懂看一手资料和二手资料有什么区别?微信转我 88,我来告诉你,别问为啥要 88 这么多,智商税。
这个官方文档看不懂?那就去公众号加我微信讨论吧~
对于增量快照,除了源卷以外,不论是 COW 方式还是 ROW 方式都需要再分配一个快照卷。在 linux 中,这个快照卷统一被称为 COW 设备。
事实上,在 linux 的代码和文档中,并没有提及 COW 和 ROW 这两种增量快照的方式,甚至都没有出现 “ROW” 这 3 个字母。正是因为理论上增量快照有 COW 和 ROW 两种方式,而在实际的 linux 驱动和文档中都没有看到,这一度让我走了不少弯路。
所以,linux 快照对 COW 和 ROW 两种方式都支持,只不过都称之为 Copy-On-Write 罢了。
对于 linux 下的 snapshot,其能够虚拟的 target device 有 3 类,分别是: snapshot-origin, snapshot 和 snapshot-merge。这 3 个设备对应于各自不同的场景:
- snapshot-origin,所有读取操作都直接映射到后端设备中,所谓后端设备,就是这里说的源卷。对每一次写入操作,原始数据(源卷中的旧数据)会被保存到 COW 设备中,新数据写入到源卷中。
- snapshot,所有写入操作都保存到 COW 设备中。对于读取操作,如果数据没有改动,则从源卷读取数据; 如果数据改动了,则从 COW 设备读取数据;
- snapshot-merge,用于将 COW 设备中的数据合并 (merge) 回源卷中;
对 snapshot-origin 和 snapshot 设备的读写操作是不是有点眼熟?
没错,snapshot-origin 设备对应于 COW 操作模型,snapshot 设备对应于 ROW 操作模型。
这里假设有两个物理设备 source 和 cow,分别对应于源卷和快照卷。基于这两个物理设备虚拟出两个快照设备 snapshot-origin 和 snapshot,如下图所示:
source 和 cow 本身也可以是虚拟设备(现实中 cow 基本都是虚拟设备),这里为了方便描述,假定二者都为物理设备。

图 7. Linux 快照设备的 COW 和 ROW
对于 snapshot-origin 设备,写入操作时,把源卷 source 设备中的旧数据复制到快照卷 cow 设备中(步骤 1’),然后将新数据写入到源卷 source 设备中(步骤 1)。读取操作则直接映射到源卷 source 设备中(步骤 2);
对于 snapshot 设备,写入操作时,直接将新数据写入到快照卷 cow 设备中(步骤 3)。读取时,没改动的数据映射到源卷 source 设备(步骤 4’‘),改动过的数据映射到快照卷 cow 设备中(步骤 4’)。
另外,这里的 snapshot-origin 和 snapshot 虚拟设备可以同时存在,而且二者可以共用一个快照卷 cow 设备。因此,快照卷 cow 设备中同时保存了 COW 和 ROW 操作的数据。
至于 snapshot-merge,其唯一的目的就是将快照卷 cow 中的数据合并 (merge) 回源卷 source,比如以下的这些场景:
-
对于 COW 操作,源卷始终保持最新数据,快照卷保存了旧数据,如果需要将源卷回滚到快照时间点的状态,就需要执行合并 (merge) 操作,将快照卷中的旧数据写回源卷。
-
对于 ROW 操作,源卷始终保持了快照时间点的状态,而快照卷保存了最新的数据,如果需要源卷更新到最新状态,也需要执行合并 (merge) 操作,将快照卷中的新数据写入到源卷。
一句话,COW 方式中对源卷还原 (还原到快照点),或 ROW 方式中对源卷更新 (更新成最新数据),都需要执行合并 (merge) 操作。Android 虚拟分区系统的更新就属于后者。
因此,对 snapshot-merge 设备,有一些特殊的要求:
- snapshot-merge 和 snapshot 使用同样的参数,只在持久快照 (persistent snapshot)下有效
- snapshot-merge 承担 snapshot-origin 的角色,如果源卷还存在 snapshot-origin 设备,则不得加载
- snapshot-merge 将快照卷 cow 中的更改块合并回源卷 source 中
- 合并开始以后,merge 之外的其它方式对源卷的修改将会被推迟到合并完成以后
这里解释了这么多,总结起来就是:
如果在 snapshot-origin 设备上操作,对应 COW 模型;
如果在 snapshot 设备上操作,对应 ROW 模型;
snapshot-merge 承担 snapshot-origin 的角色,将快照卷 cow 中的更改快合并回源卷 source 中;
3.2 COW 设备的结构
Linux 上的快照设备属于块设备,其最小的 block 单位为 sector,大小为 512 byte。
各种快照操作以 chunk 数据块的方式进行,chunk 是比 sector 大的数据块,大小在创建 snapshot 时通过 chunksize 设置。比如设置 chunksize = 8,表明 1 个 chunk 由 8 个 sector 构成,因此 1 x chunk = 8 x sector = 4KB。snapshot 驱动中默认的 chunksize 为 32,对应 chunk 大小为 16KB。
从前面可以看到,通过增量快照映射出来的设备,其数据可能保存在源卷上,也可能保存在快照设备上。
如何确定一块数据到底应该在源卷上,还是快照设备上呢?答案就是通过快照卷上的查找表,或者说映射表。
对 Linux 的快照来说:
- 如果查找表存在针对某块数据的记录,那数据在源卷和快照卷都存在,读取和写入就要进行相应选择处理。
- 如果查找表不存在针对某块数据的记录,则数据只存在于源卷之上,读取时只需要在源卷上操作即可。
总体上,一个快照卷设备大致的结构如下所示:

图 8. COW 设备的结构
在一个快照卷 COW 设备中:
- 一开始的头部是 1 个 chunk 的 disk header;
- 接下来就是查找表本身,如果查找表很小,则占用 1 个 chunk,如果很大,可能会占用多个 chunk;
- 然后就是查找表对应的数据块区域,每一块数据占用 1 个 chunk;
- 在数据块区域结束后是空闲块;
目前没有打算非常详细地描述 COW 设备的细节,后面看情况再决定是否单独用一篇文章来介绍。
4. 其它
下一篇将以实战的方式,通过 Linux 终端的命令行工具,验证 Linux 快照的各种特性,进一步加深对快照的理解,包括:
- COW 模式下多次写入数据并验证的实验
- ROW 模式下多次写入数据并验证的实验
- 合并 (merge) 操作中 COW 模式和 ROW 模式数据变化的验证
也欢迎加我微信进一步讨论,在公众号“洛奇看世界”后台回复"wx" 即可获取个人微信号。
本文参考了以下文章,对这些文章的作者一并表示感谢:
-
《存储快照》
- https://baike.baidu.com/item/%E5%AD%98%E5%82%A8%E5%BF%AB%E7%85%A7/5204871
-
《快照技术解析》
- https://www.cnblogs.com/jing99/p/7446214.html
-
《探究快照技术》
- https://www.cnblogs.com/zhaochunhui/p/13597675.html
-
《COW、ROW 快照技术原理》
- https://support.huawei.com/enterprise/zh/doc/EDOC1100196336/
-
《Git快照(snapshot)到底该如何理解?》
-
https://www.h5w3.com/82381.html