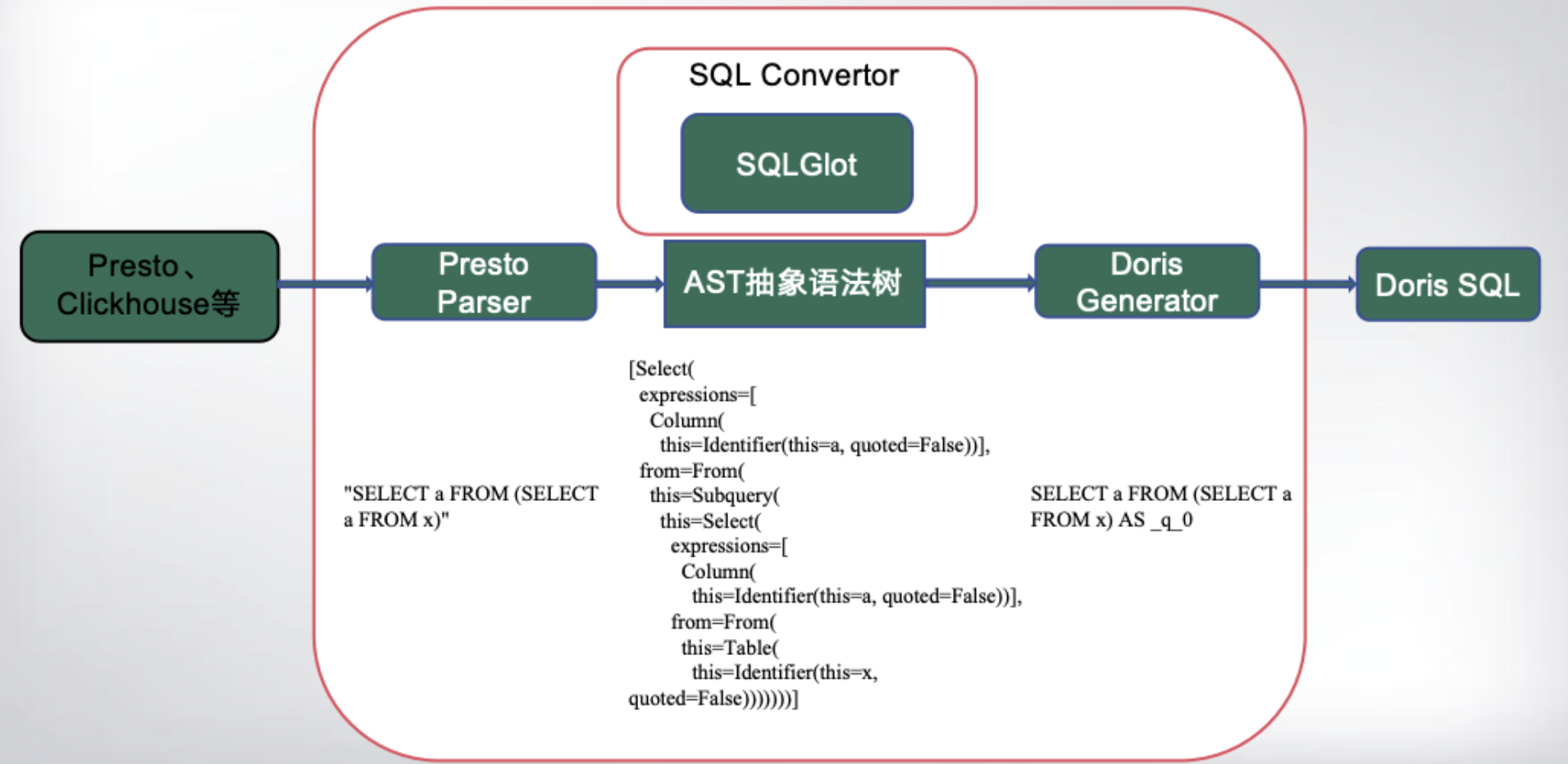
三维重建是计算机视觉和图形学的重要研究方向,其算法在不同场景下的效果差异较大。以下是当前主流的三维重建算法及其特点,按技术路线分类整理:
1. 传统几何方法
(1)结构光(Structured Light)
- 原理:通过投射编码的光栅图案到物体表面,利用相机捕捉变形后的图案计算深度。
- 特点:精度高(亚毫米级),但依赖专用设备(如投影仪和标定相机)。
- 应用:工业检测、逆向工程(如Artec Eva扫描仪)。
(2)立体视觉(Stereo Vision)
- 原理:通过两个或多个相机的视差计算深度。
- 特点:需要精确标定和纹理丰富的场景,在无纹理区域效果差。
- 改进:Semi-Global Matching (SGM) 算法优化了视差图生成。
(3)运动恢复结构(Structure from Motion, SfM)
- 原理:从多张无序图像中恢复相机位姿和稀疏点云。
- 工具:COLMAP(开源标杆)、VisualSFM。
- 缺点:依赖特征匹配,计算量大,难以处理弱纹理场景。
(4)多视图立体(Multi-View Stereo, MVS)
- 原理:在SfM基础上生成稠密点云,如PMVS、CMVS算法。
- 效果:稠密重建但计算时间长,需GPU加速。
(5)SLAM(实时定位与建图)
- 代表算法:ORB-SLAM3(支持单目/双目/RGB-D)、LSD-SLAM。
- 特点:实时性强,适合动态场景(如机器人、AR)。
2. 深度学习方法
(1)单目深度估计(Monocular Depth Estimation)
- 模型:MiDaS、DPT-Hybrid、AdaBins。
- 优势:仅需单张RGB图像,实时性好。
- 缺点:精度较低,依赖训练数据分布。
(2)多视图立体匹配(Learned MVS)
- 代表工作:MVSNet(2018)、Cascade MVSNet、Patchmatchnet。
- 效果:在DTU等数据集上超越传统MVS,但需要多视角输入(≥3张图)。
(3)隐式神经表示(Neural Radiance Fields, NeRF)
- 核心思想:用MLP网络建模场景的辐射场和密度,通过体渲染生成新视角。
- 优势:渲染质量极高,细节逼真,支持复杂光照。
- 缺点:训练慢(数小时)、推理实时性差,依赖大量视角(>100张图)。
- 改进版:Instant-NGP(加速训练)、NeRFusion(稀疏输入)、DynamicNeRF(动态场景)。
(4)基于体素/点云/网格的重建
- 模型:Pix2Vox(体素生成)、PointNet++(点云处理)、Mesh R-CNN。
- 应用:从单张图像生成粗糙3D形状,适合物体级重建。
3. 混合方法(传统+深度学习)
- DeepSFM:用深度学习优化SfM中的特征匹配和深度估计。
- NeuralRecon:结合SLAM与神经网络实现实时稠密重建。
- COLMAP+NeRF:用COLMAP生成位姿后输入NeRF提升渲染质量。
效果对比与推荐
| 场景 | 推荐算法 | 原因 |
|---|---|---|
| 高精度静态物体扫描 | 结构光/激光扫描 | 工业级精度(0.1mm级),但需专用设备。 |
| 多视角图像重建 | COLMAP(SfM+MVS)或MVSNet系列 | 开源易用,稠密重建效果稳定。 |
| 新视角合成(照片级) | NeRF及其变种(如Instant-NGP) | 渲染质量最优,适合虚拟现实、影视特效。 |
| 实时动态场景 | SLAM(如ORB-SLAM3)或NeuralRecon | 低延迟,适合AR/VR、机器人导航。 |
| 单张图像重建 | 单目深度估计(如MiDaS)+ 表面重建算法 | 便捷但精度有限,适合快速原型设计。 |
未来趋势
- 实时NeRF:通过哈希编码、轻量级网络(如Instant-NGP)加速训练和渲染。
- 泛化性提升:Zero-shot重建(如使用扩散模型先验)。
- 动态场景处理:结合光流估计和时空建模(如DynamicNeRF)。
实际应用中需根据数据条件(图像数量、设备)、精度需求、实时性要求综合选择。目前学术界更关注NeRF的改进,而工业界仍依赖传统方法(如COLMAP)或混合方案。