嘿,记得给“机器学习与推荐算法”添加星标
TLDR:今天跟大家分享一篇通过利用聚类算法来操纵物品嵌入特征以此针对联邦推荐场景进行非定向攻击的工作,随后作者针对这一攻击又提出了一种基于一致性的对应防御机制,该论文已被AAAI2023接收。接下来让我们具体看看所提算法是如何工作的吧。

论文:https://arxiv.org/abs/2212.05399
代码:https://github.com/yflyl613/FedRec
近年来,个性化推荐系统在为用户克服信息过载方面发挥着重要作用。大部分的传统推荐算法基于中心化的训练和存储模式来提供服务,虽然这种方式可以提供优良的推荐性能但会存在数据和隐私泄露的风险。尤其是随着最近隐私保护法(比如GDPR等)的颁布,使得企业越来越困难的对用户数据进行集中式存储与训练。联邦推荐系统可以在不传输和集中存储用户私有数据的前提下进行精准推荐,近年来已经得到了研究者的广泛关注,更多联邦推荐算法的研究工作可以参考基于隐私保护的联邦推荐算法综述和一文梳理联邦学习推荐系统研究进展。
虽然联邦推荐系统通过不传输用户私有数据而实现了隐私保护能力,但最近的研究表明在联邦设置下系统很容易受到投毒攻击(poisoning attack)的影响,其分布式的训练过程允许攻击者任意修改局部训练数据或上传的梯度来达到某些恶意目的。更多关于攻击和防御技术可参考推荐系统中的对抗机器学习技术总结。根据攻击者的目的,投毒攻击可分为定向攻击和非定向攻击。在联邦推荐场景中,以前的研究主要集中在试图促进某些目标物品的定向攻击。而非定向攻击旨在降低联邦推荐系统整体性能的研究工作仍然很少被探索。事实上,如果没有有效的防御机制,非定向攻击会持续破坏用户体验,这将导致用户的流失以及服务提供商的收入损失。因此研究联邦推荐场景下的非定向攻击尤为重要。
联邦推荐场景下的非定向投毒攻击主要有以下挑战。1. 首先,考虑到推荐系统通常拥有数百万用户,攻击者控制大量客户端是不现实的。因此攻击方法必须在很少一小部分恶意客户端参与的情况下仍然有效。2. 其次,攻击者只能访问存储在恶意客户端上的一小部分数据,因为客户端在联邦设置下从不共享他们的本地训练数据。3. 非定向投毒攻击的目的是降低联邦推荐系统在任意输入时的整体性能,它比只操纵特定目标项上的模型输出的定向攻击更具挑战性。4. 许多推荐算法都是在带有噪声的隐式用户反馈上进行训练的,这使得推荐算法本身对恶意扰动具有一定的鲁棒性。
为了应对上述挑战,在本文中,首先提出了一种非定向模型投毒攻击方法ClusterAttack,它可以利用一小部分恶意客户端来有效地降低联邦推荐系统的整体性能。其主要思想是通过上传有毒梯度(poisonous gradients),进而将推荐模型的物品嵌入收敛到几个稠密的聚类中,这样就可以让推荐算法为同一聚类中的这些接近的物品生成相似的分数,从而影响正常的排名顺序。针对现有防御方法大多无法有效防御ClusterAttack的问题,其进一步提出了一种基于一致性的防御机制UNION来保护联邦推荐系统免受此类攻击。

首先大致介绍下联邦推荐的流程以及论文中使用的符号系统。设和分别表示推荐系统中个物品和个用户/客户端的集合。这些客户端试图在不共享私有数据的情况下协同训练一个全局模型。我们假设推荐模型的参数由三个部分组成:一个物品模型,它将物品ID转换为物品嵌入,一个用户模型,它从用户特征文件(例如,用户ID或历史交互物品中)推断用户兴趣嵌入,以及一个预测模型,它在给定物品嵌入和用户嵌入的前提下预测排名分数。在每一轮训练中,服务端首先分发当前全局模型参数到个随机选择的客户端。然后每个选定的客户端计算更新梯度的本地数据。然后根据带有正则化的BPR损失来进行训练:
其中,为sigmoid函数,和分别代表正样本和负样本的排序得分。虽然本地客户端将进行更新用户模型,然后将上传到服务端进行聚合更新。最后服务端聚合所有客户端上传的梯度来更新物品嵌入,然后将最新的物品嵌入进行下发。经过多轮训练达到收敛状态。
首先介绍下ClusterAttack,更直观的步骤可参考图1。具体来说,本文使用自适应聚类机制(Algorithm 1)将物品嵌入分割为几个簇(步骤2,3,8),并计算攻击损失进而计算恶意梯度以减少簇内方差。其中表示为:
其中,为聚类个数,为物品的低维嵌入,为聚类中心嵌入。为了使攻击更难以被检测到,文本在将恶意梯度上传到服务器之前,使用从正常梯度估计的范数界来约束恶意梯度,以此让这两者之间的梯度不容易被服务端察觉。

考虑到聚类的数量会对攻击效果产生很大影响,所以设计了自适应聚类算法,在每一轮攻击(步骤8)后自动调整的值,如算法1所示。由于攻击者唯一的攻击效果反馈是,因此在攻击过程中对它进行跟踪,并计算其偏差修正的指数移动平均八本。同时使用两个计数器和分别记录平滑攻击损失增加和减少的轮数。如果在过去的几轮中大部分增加,就假设当前的K值太小,攻击损失不能很好地收敛。因此,需要增加的值,使攻击更容易。相反,如果继续下降,我们进一步降低的值来进行更强的攻击。
由于现有的防御方法大多无法有效防御ClusterAttack,其进一步提出了一种基于一致性的防御机制UNION来保护联邦推荐系统免受此类攻击。具体的,本文要求所有良性客户端(benign clients)使用额外的对比学习任务来训练局部推荐模型,以此来将物品嵌入进行正则化,使其在空间中均匀分布。然后,服务端通过估计更新物品嵌入的一致性来识别这些恶意梯度。服务端具体的算法执行流程如算法2所示。

其中,用来评估分布是否一致的Gap Statistics算法的详细执行过程见算法3。大体思路是,它是通过比较在均匀分布下的期望与包含簇内的变化来确定一组数据中的簇数。如果算法估计存在多个聚类,就认为存在一些恶意梯度,使得物品嵌入出现异常分布的情况。

在客户端上主要要求所有良性客户端训练本地推荐模型,并附加一个对比学习任务,并采用InforNCF作为其对比损失。其中,表示用户有过交互的正样本,则表示从用户未交互过的物品集合中采样得到的负样本。

因此,在使用推荐任务BPR进行训练的同时,额外的对比任务可以将物品嵌入正则化,使其在空间中呈均匀分布。由于这样的优化目标与ClusterAttack的目标相反,对比任务可以减轻其攻击效果,也使服务端更容易区分这些恶意梯度。
最后,在两个经典的推荐模型上测试了在两个数据集上多种攻击方法的实验结果。

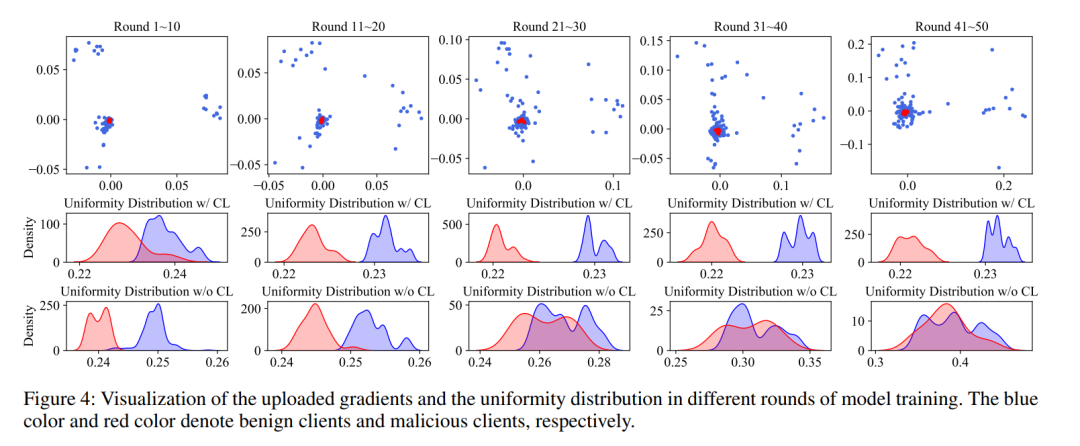
下图展示了随着迭代轮次的增加带有对比学习任务的防御机制与没有带对比学习任务的方法的对比效果。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
论文周报 | 推荐系统领域最新研究进展
SIGIR2022 | 基于生成对抗思想的冷启动推荐算法
TKDE2022 | 基于关系的协同过滤算法
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
喜欢的话点个在看吧👇

![[leetcode.10]正则表达式匹配](https://img-blog.csdnimg.cn/6abff7c2484d4c319cb1dcd91e5a2565.png)