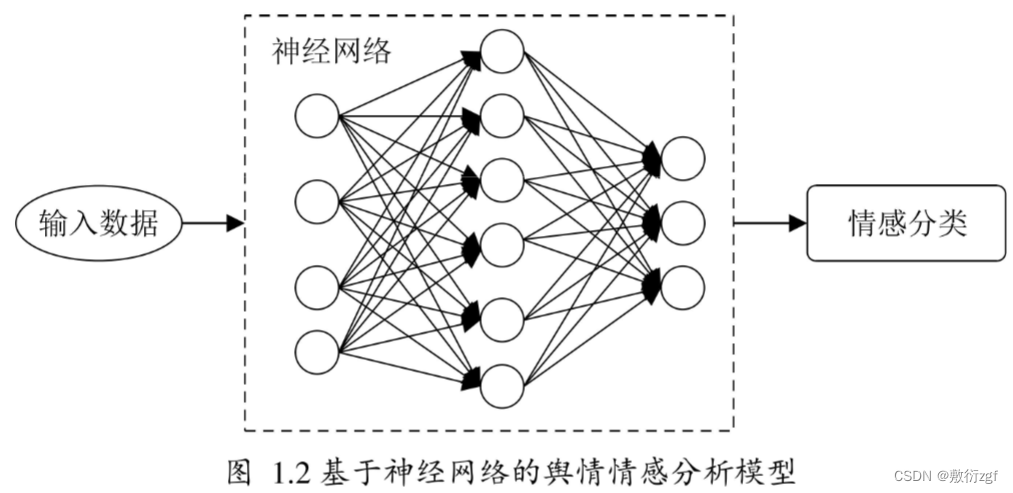
在这篇文章中,我们将学习如何在Power BI中使用Python编程语言进行数据源化。
简介
Python可以说是业界最流行、最普遍的编程语言之一。一方面,Python可用于网络和应用程序开发,另一方面,它在数据世界中也非常流行,特别是在数据科学和数据工程方面。python的普遍性导致它被许多市场领先的工具、软件、框架和SDK采用。例如,在微软的技术栈中,像微软的Visual Studio、微软的Power BI、微软的SQL Server和其他这些流行的工具和技术都对Python有非常强大的集成支持。Python具有处理数据的独特能力,被用于编程,像skikitlearn这样的框架用于数据科学,以及用于渲染可视化的丰富库。Power BI是微软的主要工具和技术栈,用于在企业内部以及Azure云上进行报告和仪表盘制作。它支持使用Python渲染可视化,也支持使用Python导入数据。PowerBI配备了一百多个连接器,支持几乎所有的标准、成熟和新兴的数据源。数据专业人员将Python用于各种数据处理和数据消费相关的用例,并且有很大的潜力重复使用他们现有的代码库来获取和处理数据,并将其用于像PowerBI这样的工具。
Python的安装和设置
由于我们要在Microsoft Power BI中使用Python,我们将需要在本地机器上安装Python的设置。Python可以通过从Python.org下载到本地机器上直接安装。这是在本地机器上配置Python设置的最直接的方法之一。另一种安装python的方法是把它配置成Microsoft SQL Server的一部分,如果你碰巧在本地机器上有一个SQL Server设置的话。安装SQL Server来安装Python并不是一个有效的方法。但反过来说,也可以是设置Python的方法之一。使用SQL Server的Python服务器组件的局限性是,可能会有一些限制或约束,因为SQL Server可能会在其Python安装上安装一些包装器。另外,SQL Server安装的Python发行版是Anaconda发行版,人们可能想要一个特定的Python版本,在这种情况下,应该考虑下载所需的Python版本并在本地机器上独立安装。在本文中,我们假设本地机器上已经配置了Python的安装。
在我们进行实际操作之前,让我们看看Python设置的一些基本但重要的位置,我们可能需要使用这些位置来管理Python,特别是安装包,即库。一个Python安装的主目录如下所示。

托管二进制文件的目录是 Scripts 目录,该目录用于使用 pip 工具构建和安装软件包。使用命令提示符上的 pip 命令,我们可以很容易地在 python 安装中安装库。实际的库被安装在 Lib 目录中。人们可以使用pip命令来安装库,或者下载一个已经构建好的库并将其复制到Lib目录中。要在Power BI中使用python,必须安装三个库--OS、Pandas和matplotlib。一般来说,OS和Pandas(含Numpy)是大多数Python版本中预装的库。但是我们必须使用 "pip install matplotlib "命令来安装matplotlib库。一旦这个库被成功安装,那么可以认为Python设置已经准备好与Power BI一起使用。为了构建库,Python中的pip工具在微软Windows平台上使用Visual C++ 14.0或更高版本。确保你在本地机器上安装了相应的再分配软件。
假设所有需要的库都安装在本地机器上,并且最新版本的PowerBI也安装在本地机器上,打开PowerBI。导航到文件菜单 -> 选项和设置 -> 选项 -> Python 脚本菜单项。我们需要配置这一部分,将PowerBI指向Python的主目录,这样当我们使用Python脚本来获取带或不带预处理的数据集时,它将使用配置的Python设置来执行这些脚本。一般来说,如果系统变量PATH已经被设置,PowerBI会检测到Python安装的主目录。在任何情况下,如果它没有检测到Python的主目录,我们可以手动将PowerBI指向Python安装的主目录。

一旦Python设置完成,我们就可以导航回设计器窗口。点击获取数据菜单项,选择Python脚本连接器。它将打开一个新的窗口来提交Python脚本以供执行。只有数据框架会被解析为表格,并考虑在Power BI报告中进行采购。由于PowerBI已经支持各种各样的数据源,我们可以使用直接连接器来从这些数据源中获取数据。在数据科学中,从GitHub或其他类似来源的网络上刮取数据进行探索性数据分析是一种非常普遍的做法。这可能需要脚本来读取和格式化这些数据,然后再进行采购。因此,我们将考虑用Power BI中的Python连接器来使用一个类似的例子。
键入如下所示的Python脚本。在这个脚本中,第一行,我们正在导入pandas python库,该库通常用于读取数据并将其填充到称为数据框架的表格数据结构中。在脚本的第二行,我们创建了一个名为URL的变量,并将GitHub上的CSV文件的值赋给它。在python脚本的最后一行,我们使用pandas对象,执行read_csv文件,并将URL变量作为参数传给它。这将导致从该文件中读取数据,并将结果输出分配给变量 df。由于read_csv函数的输出是一个数据框,变量df的类型将是一个数据框,这正是我们所需要的,以便将输出检测为一个表格,导入我们的Power BI报告中。

点击 "OK "按钮,进入下一步。在下一步中,Power BI将使用我们之前配置的Python安装来执行这个脚本,然后显示输出的数据进行预览,如下图所示。在PowerBI报告中导入最终数据集之前,我们可以选择在脚本中对数据进行格式化,也可以在PowerBI中对超过这个阶段的数据进行转换。
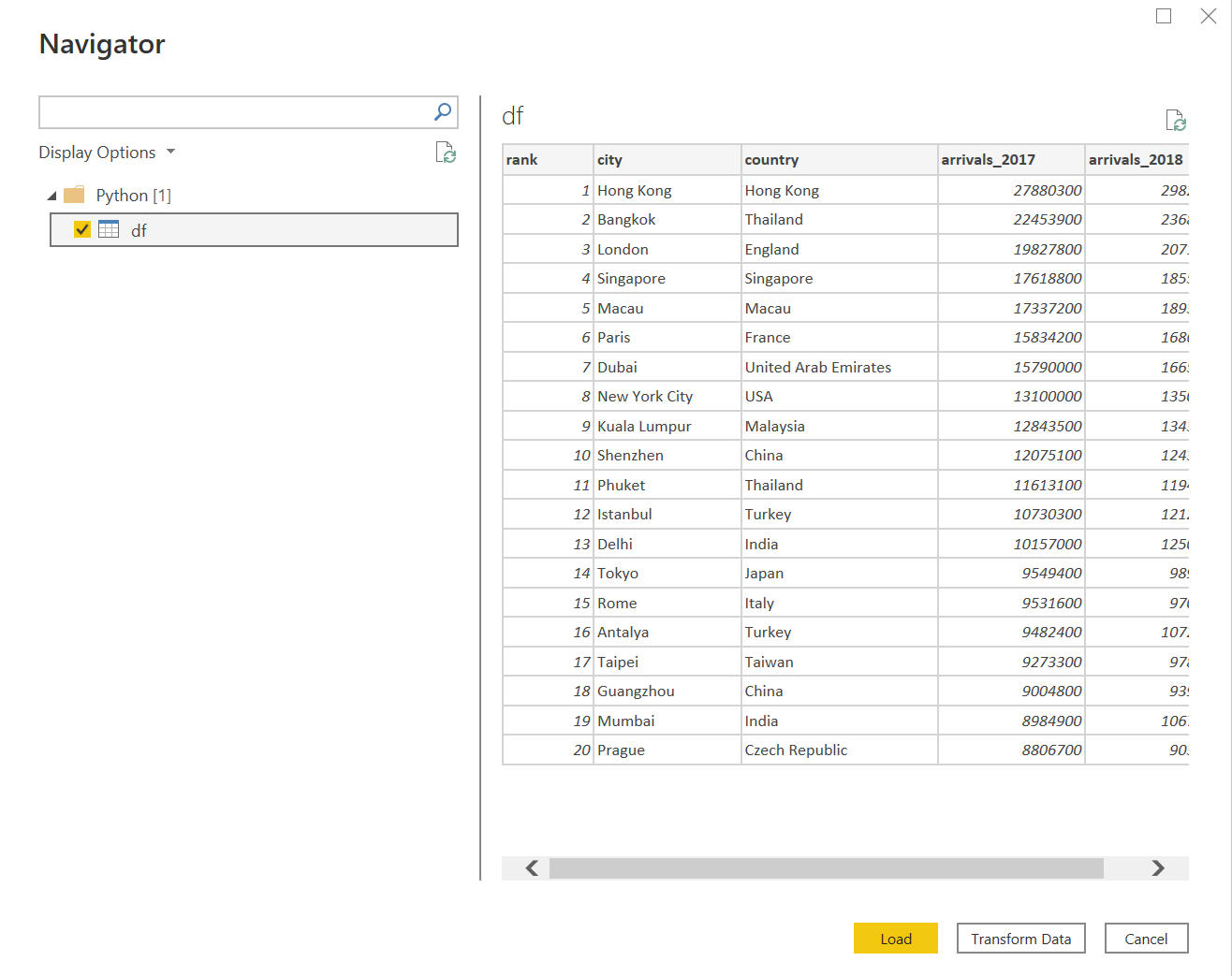
点击加载按钮,将使用Python脚本获取的数据填充到PowerBI报告中。通过这种方式,我们可以在PowerBI的Python脚本连接器中使用Python脚本,使用Python安装来获取数据。
总结
在这篇文章中,我们学习了如何在本地机器上下载、安装和配置 Python。我们探索了Python中的工具和实用程序,它们允许我们安装通常用于处理数据的必要包。我们配置了PowerBI以指向Python的安装,然后使用Python连接器来执行脚本,使我们能够在Power BI报告中获得数据源。

![[leetcode.10]正则表达式匹配](https://img-blog.csdnimg.cn/6abff7c2484d4c319cb1dcd91e5a2565.png)