回溯算法解题套路框架
- 前言
- 回溯算法的框架
- 排列(元素无重不可复选)
- 46. 全排列
- 解析
- 子集(元素无重不可复选)
- 78. 子集
- 解析
- 组合(元素无重不可复选)
- 77. 组合
- 解析
- 子集/组合(元素可重不可复选)
- 90. 子集 II
- 解析
- 面试题
- 31. 下一个排列
前言
回溯算法的框架
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
# 做选择
排除不合法的选择
路径.add(选择)
backtrack(路径, 选择列表)
# 撤销选择
路径.remove(选择)
其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」。
什么叫做选择和撤销选择呢,这个框架的底层原理是什么呢?下面我们就通过「46. 全排列」这个问题来解开之前的疑惑,详细探究一下其中的奥妙!
排列(元素无重不可复选)
46. 全排列
问题描述
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例1
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例2
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例3
输入:nums = [1]
输出:[[1]]
代码
//存储结果
List<List<Integer>> result = new ArrayList<>();
public List<List<Integer>> permute(int[] nums) {
//记录路径
LinkedList<Integer> track = new LinkedList<>();
backtrack(nums, track);
return result;
}
void backtrack(int[] nums, LinkedList<Integer> track) {
//到达叶子节点,将路径存入result
if (track.size() == nums.length) {
result.add(new LinkedList<>(track));
return;
}
for (int i = 0; i < nums.length; i++) {
//排除不合法的选择
if (track.contains(nums[i])) {
continue;
}
//做选择
track.add(nums[i]);
//进入下一层
backtrack(nums, track);
//取消选择
track.removeLast();
}
}
解析
我们在高中的时候就做过排列组合的数学题,我们也知道 n 个不重复的数,全排列共有 n! 个。那么我们当时是怎么穷举全排列的呢?
比方说给三个数 [1,2,3],你肯定不会无规律地乱穷举,一般是这样:
先固定第一位为 1,然后第二位可以是 2,那么第三位只能是 3;然后可以把第二位变成 3,第三位就只能是 2 了;然后就只能变化第一位,变成 2,然后再穷举后两位……
其实这就是回溯算法,我们高中无师自通就会用,或者有的同学直接画出如下这棵回溯树:

只要从根遍历这棵树,记录路径上的数字,其实就是所有的全排列。我们不妨把这棵树称为回溯算法的「决策树」。
为啥说这是决策树呢,因为你在每个节点上其实都在做决策。比如说你站在下图的红色节点上:

你现在就在做决策,可以选择 1 那条树枝,也可以选择 3 那条树枝。为啥只能在 1 和 3 之中选择呢?因为 2 这个树枝在你身后,这个选择你之前做过了,而全排列是不允许重复使用数字的。
现在可以解答开头的几个名词:[2] 就是「路径」,记录你已经做过的选择;[1,3] 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层叶子节点,这里也就是选择列表为空的时候。
如果明白了这几个名词,可以把「路径」和「选择」列表作为决策树上每个节点的属性,比如下图列出了几个蓝色节点的属性:

我们定义的 backtrack 函数其实就像一个指针,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层叶子节点,其「路径」就是一个全排列。
「路径」和「选择」是每个节点的属性,函数在树上游走要正确处理节点的属性,那么就要在这两个特殊时间点搞点动作:

子集(元素无重不可复选)
78. 子集
问题描述
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例1
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例2
输入:nums = [0]
输出:[[],[0]]
代码
List<List<Integer>> res = new LinkedList<>();
// 记录回溯算法的递归路径
LinkedList<Integer> track = new LinkedList<>();
// 主函数
public List<List<Integer>> subsets(int[] nums) {
backtrack(nums, 0);
return res;
}
// 回溯算法核心函数,遍历子集问题的回溯树
void backtrack(int[] nums, int start) {
// 前序位置,每个节点的值都是一个子集
res.add(new LinkedList<>(track));
// 回溯算法标准框架
for (int i = start; i < nums.length; i++) {
// 做选择
track.addLast(nums[i]);
// 通过 start 参数控制树枝的遍历,避免产生重复的子集
backtrack(nums, i + 1);
// 撤销选择
track.removeLast();
}
}
解析
使用 start 参数控制树枝的生长避免产生重复的子集,用 track 记录根节点到每个节点的路径的值,同时在前序位置把每个节点的路径值收集起来,完成回溯树的遍历就收集了所有子集:

最后,backtrack 函数开头看似没有 base case,会不会进入无限递归?
其实不会的,当 start == nums.length 时,叶子节点的值会被装入 res,但 for 循环不会执行,也就结束了递归。
组合(元素无重不可复选)
如果你能够成功的生成所有无重子集,那么你稍微改改代码就能生成所有无重组合了。
你比如说,让你在 nums = [1,2,3] 中拿 2 个元素形成所有的组合,你怎么做?
稍微想想就会发现,大小为 2 的所有组合,不就是所有大小为 2 的子集嘛。
所以我说组合和子集是一样的:大小为 k 的组合就是大小为 k 的子集。
77. 组合
问题描述
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
示例
输入:n = 1, k = 1
输出:[[1]]
代码
List<List<Integer>> res = new LinkedList<>();
// 记录回溯算法的递归路径
LinkedList<Integer> track = new LinkedList<>();
// 主函数
public List<List<Integer>> combine(int n, int k) {
backtrack(1, n, k);
return res;
}
void backtrack(int start, int n, int k) {
// base case
if (k == track.size()) {
// 遍历到了第 k 层,收集当前节点的值
res.add(new LinkedList<>(track));
return;
}
// 回溯算法标准框架
for (int i = start; i <= n; i++) {
// 选择
track.addLast(i);
// 通过 start 参数控制树枝的遍历,避免产生重复的子集
backtrack(i + 1, n, k);
// 撤销选择
track.removeLast();
}
}
解析
这是标准的组合问题,但我给你翻译一下就变成子集问题了:
给你输入一个数组 nums = [1,2…,n] 和一个正整数 k,请你生成所有大小为 k 的子集。
还是以 nums = [1,2,3] 为例,刚才让你求所有子集,就是把所有节点的值都收集起来;现在你只需要把第 2 层(根节点视为第 0 层)的节点收集起来,就是大小为 2 的所有组合:

子集/组合(元素可重不可复选)
90. 子集 II
问题描述
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
输入:nums = [0]
输出:[[],[0]]
代码
List<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> track = new LinkedList<>();
public List<List<Integer>> subsetsWithDup(int[] nums) {
// 先排序,让相同的元素靠在一起
Arrays.sort(nums);
backtrack(nums, 0);
return res;
}
void backtrack(int[] nums, int start) {
// 前序位置,每个节点的值都是一个子集
res.add(new LinkedList<>(track));
for (int i = start; i < nums.length; i++) {
// 剪枝逻辑,值相同的相邻树枝,只遍历第一条
if (i > start && nums[i] == nums[i - 1]) {
continue;
}
track.addLast(nums[i]);
backtrack(nums, i + 1);
track.removeLast();
}
}
解析
按照之前的思路画出子集的树形结构,显然,两条值相同的相邻树枝会产生重复:

所以我们需要进行剪枝,如果一个节点有多条值相同的树枝相邻,则只遍历第一条,剩下的都剪掉,不要去遍历:
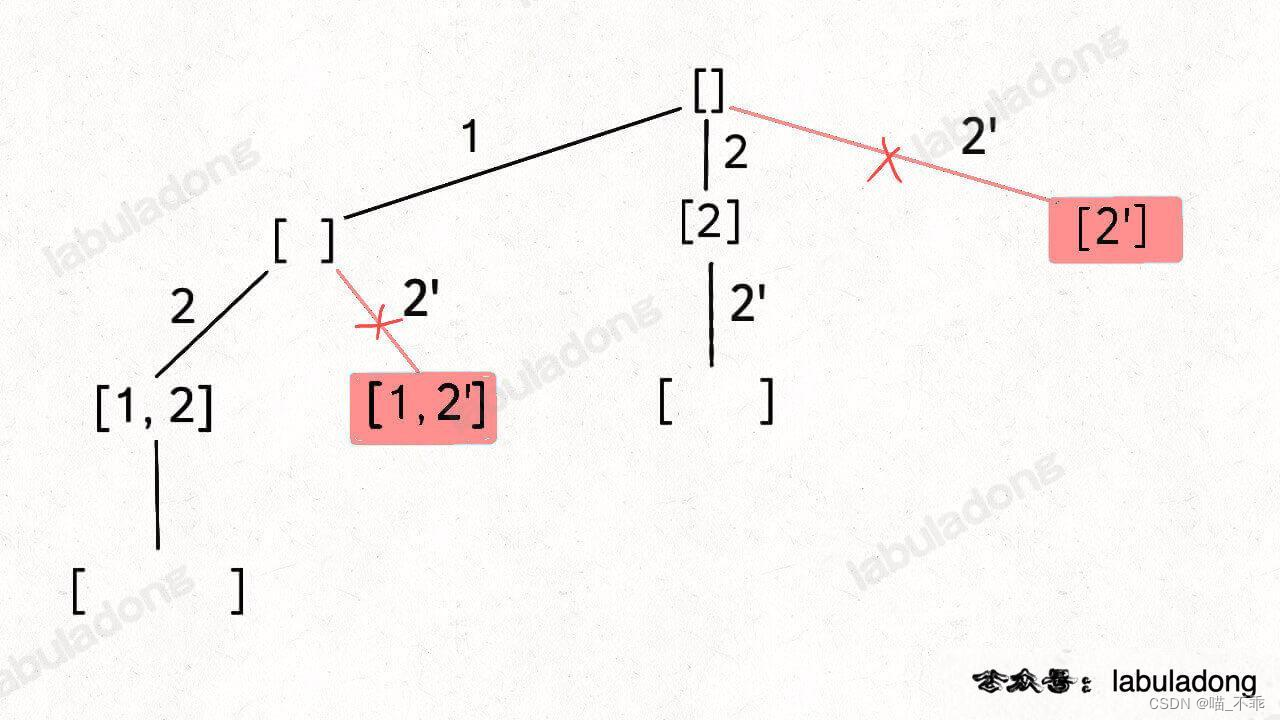
体现在代码上,需要先进行排序,让相同的元素靠在一起,如果发现 nums[i] == nums[i-1],则跳过:
这段代码和之前标准的子集问题的代码几乎相同,就是添加了排序和剪枝的逻辑。
至于为什么要这样剪枝,结合前面的图应该也很容易理解,这样带重复元素的子集问题也解决了。
面试题
31. 下一个排列
问题描述
实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
必须原地修改,只允许使用额外常数空间。
示例
1,2,3 → 1,3,2
3,2,1 → 1,2,3
1,1,5 → 1,5,1
代码
求下一个全排列,可分为两种情况:
1.例如像 5 4 3 2 1这样的序列,已经是最大的排列,即每个位置上的数非递增,这时只需要翻转整个序列即可
2.例如像 1 3 5 4 2这样的序列,要从后往前找到第一个比后面一位小的元素的位置,即第二个位置的3,然后与其后第一个比它大的元素交换位置,得到 1 4 5 3 2,再将 5 3 2翻转得到 1 4 2 3 5即可
// 1 3 5 4 2
static void nextPermutation(int[] nums) {
int n = nums.length;
if (n <= 1) {
return;
}
//找到i(num[i]<num[i+1]) 第一个非降序的下标,i后面的元素都是降序的,证明已经是最大值
int i = n - 2; //1
while (i >= 0 && nums[i] >= nums[i + 1]) {
i--;
}
//数字整体降序,已经是最大值,这时候只需要通过反转就可以得到最小值
if (i < 0) {
reverse(nums, 0, n - 1);
}
//从(i,n-1)范围内遍历找到比nums[i]大的数字,倒着遍历(因为i至n-1的数字整体降序,倒着遍历找到第一个比num[i]大的数字)
int j = n - 1; //3
while (i < j && nums[j] <= nums[i]) {
j--;
}
//i和j交换
swap(nums, i, j); //i:1 j:3 结果 1 4 5 3 2
reverse(nums, i + 1, n - 1); //为保证数字是最小的,所以i+1至n-1的反转 结果 1 4 2 3 5
}
static void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
static void reverse(int[] nums, int start, int end) {
while (start < end) {
swap(nums, start++, end--);
}
}
来源(算法小抄):https://labuladong.gitee.io/algo/1/8/
下一个排列(视频讲解):https://www.bilibili.com/video/BV1Rz4y1Z7hx