目录
一、基本概念
批与流
数据可以作为无界流或有界流处理
二、什么是Flink?
三、Flink有什么用途?
四、适用场景
五、flink事件驱动
六、flink拥有分层API
flink sql
七、fllink企业级使用
一、基本概念
批与流
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
数据可以作为无界流或有界流处理
无界流有一个起点,但没有定义的终点。它们不会终止并在生成数据时提供数据,无界流必须被连续处理,即事件在被摄取后必须被及时处理。处理无边界数据通常需要以特定顺序(例如事件发生的顺序)来摄取事件,一遍能够推断出结果的完整性。
有界流具有定义的开始和结束。可以通过在执行任何计算之前提取所有数据来处理有界流。由于有界数据始终可以排序,因此不需要有序摄取即可处理有界流。绑定流的处理也被称为批处理。
二、什么是Flink?

Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
支持高吞吐、低延迟(每秒处理百万个事件)、高性能的分布式处理框架。
三、Flink有什么用途?
flink作为实时流处理平台,可以与kafka很好地结合。
- 与kafka的结合,可以让flink作为生产者,不断的向kafka消息队列中产生消息
- 还有一种情况,让flink作为kafka的消费者,读取消息队列中的消息,然后做处理。
四、适用场景
在实际生产的过程中,大量数据在不断地产生,例如金融交易数据、订单数据等,以及我们熟悉的网络流量监控、服务器产生的日志数据,这些数据最大的共同点就是实时从不同的数据源中产生,然后再传输到下游的分析系统。
五、flink事件驱动
参考:来源

- 传统型事务应用程序处理流程:一个事件通过后台应用程序处理,通过读写数据库,将结果返回给用户。
- 事件驱动处理过程:通过收集事件日志,摄入到flink应用中,通过一个本地状态而不去查询关系型数据库,本地状态为了保证稳定性,还可以将状态存到一个持久性存储中,最终通过计算,将结果保存到持久存储或者发送给下游应用使用
六、flink拥有分层API
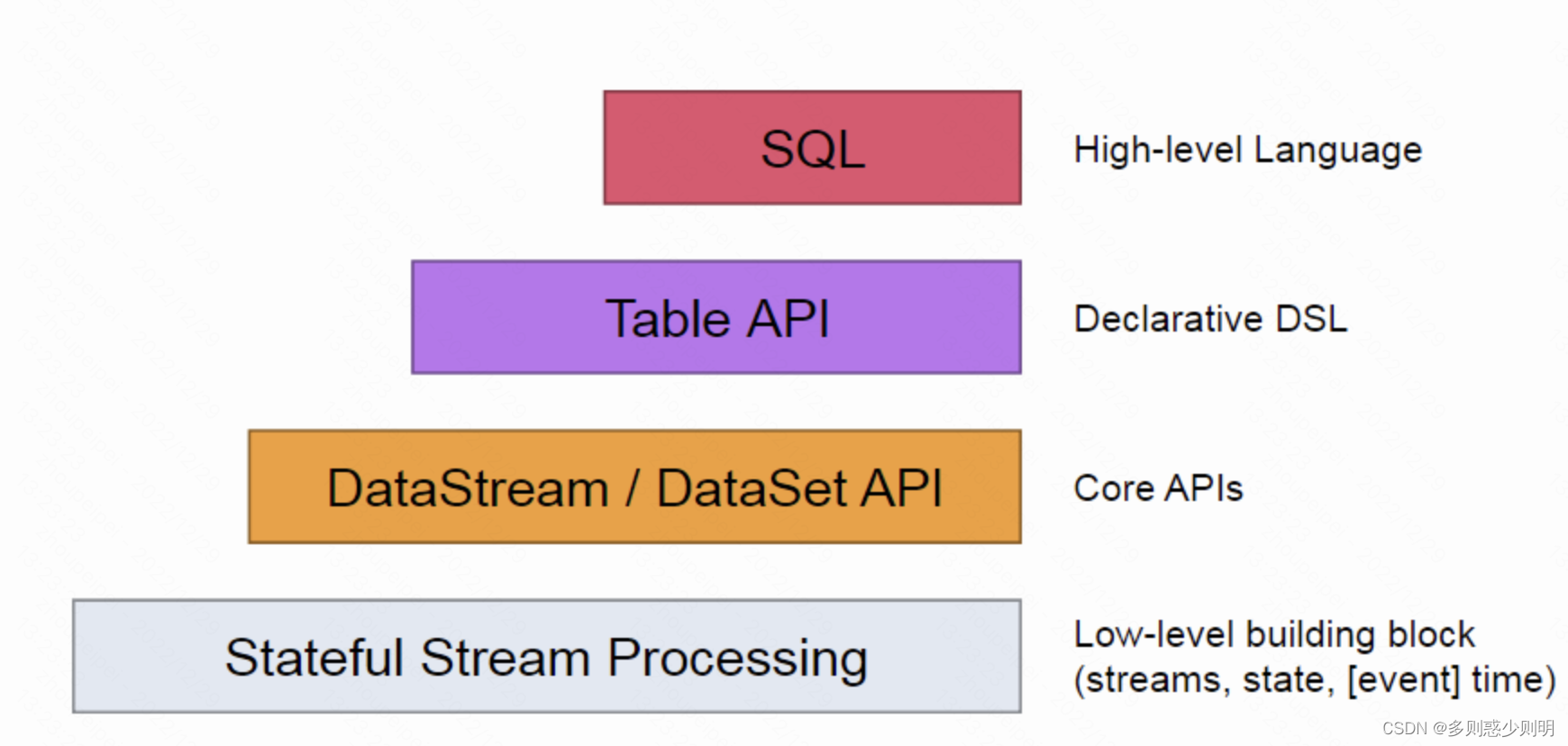
High-level language:高级语言,即使用高级语义描述计算
Declarative DSL:声明式DSL
core APIs:核心API
Stateful Stream Processing:有状态的流处理
low-level building block:低级api,构建块
flink sql
可以对流数据进行类似表一样的处理,可以实现大部分DataStream API和DataSet API的功能;
七、fllink企业级使用
-
一般会再flink上有自己的封装,如 快手的实时开发平台(KwaiStream),基于Apache Flink 构建的、一站式、高性能实时数据处理平台,用于处理各类流式数据的业务场景。
-
业务实际使用上,产品常见使用场景包括:
1)数据流拆分、基础数据清洗
2)PV、UV类型的实时业务统计
3)日志实时分析、操作行为等实时监控&报警
4)与多种数据源类型打通,可以将实时处理后的数据直接落地到OLAP、ES等,供后续业务方使用
5)将各类数据源定为逻辑表(如Redis/Kafka、MySQL),通过使用SQL对逻辑表进行加工处理即可完成对底层数据源的读写操作,使用更加便捷.