背景
很多人拿到数据excel文件,然后要写报告,做表格,要各种计算,各种排序,分组聚合,数据透视,然后合并单元格,添加边框,加粗,添加显示规则,添加数据条......然后变成固定格式的表格,复制到word里面或者直接发给领导看。 一样的工作每天或者每月都做的话,重复性的劳动真的很没有意义....
为什么不用Python进行自动化呢,单元格的颜色填充都可以模板化,自定义化。 代码开发完后,以后拿到数据只需双击运行一下代码,就可以模板化输出自己的报告啦
什么?不会写代码...在AI如此发达的今天,不会就问,就学倍。
本次就全场使用gpt编程,来给大家演示怎么对自己的数据进行一个模板化的报告输出。
所有过程都可以使用自然语言和gpt对话完成,让他来写代码,不会编程一样能做出属于自己的自动化程序。
代码实现(提示词实现)
不需要你写代码,你需要和gpt提需求就好了。
我们从头开始,
生成/读取数据
首先我要分析我需要数据,我懒得找数据了....就直接让gpt帮我生成一个数据:
帮我生成一个pandas数据框,要有4列,第一列时间(按月统计),第二列地区,第三列产品名称,第四列销售量。 时间就从2023-11到2024-10。地区就北上广深杭州南京6个城市,产品名称就是产品ABC3众,销售量你numpy正态分布随机来吧
然后gpt就吭哧吭哧的写出代码,你放入python中运行:
import pandas as pd
import numpy as np
# 定义时间范围
date_range = pd.date_range(start='2023-11-01', end='2024-10-31', freq='M').strftime('%Y-%m')
# 定义地区和产品名称
regions = ['北京', '上海', '广州', '深圳', '杭州', '南京']
products = ['产品A', '产品B', '产品C']
# 创建数据框架
data = {
'时间': np.repeat(date_range, len(regions) * len(products)),
'地区': np.tile(np.repeat(regions, len(products)), len(date_range)),
'产品名称': np.tile(products, len(date_range) * len(regions)),
'销售量': np.random.normal(loc=500, scale=100, size=len(date_range) * len(regions) * len(products)).astype(int)
}
df = pd.DataFrame(data)
# 确保销售量非负
df['销售量'] = df['销售量'].apply(lambda x: max(x, 0))
df.shape
df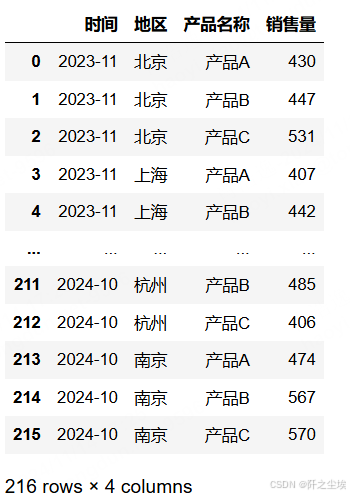
挺好,就是自己想要的样子。
如果你是本地excel数据要读取,那就问gpt,怎么用pandas读取本地文件就好了。你告诉它你数据张什么样,要如何读取......用它写的代码就能读取进来,和我上面生成的这个是一样的。很简单。
分组聚合计算统计量
我们要统计不同地方不同商品的销售量变化,那我就开始问gpt了:
好,现在帮我进行统计,我要输出一个多层索引的表。 首先可以计算一个环比,每个地区每个产品比上个月的销售量环比增加了多少。 然后进行数据的变形,行是不同的时间,列是多层索引,第一层是不同的地区,第二层是不同的商品,取值就是销售量的环比
然后它就会写出代码:
df.sort_values(by='时间', inplace=True)
# 计算环比变化
df['环比'] = df.groupby(['地区', '产品名称'])['销售量'].pct_change()
# 将数据变形为所需的多层索引格式
pivot_table = df.pivot_table(index='时间', columns=['地区', '产品名称'], values='环比')
pivot_table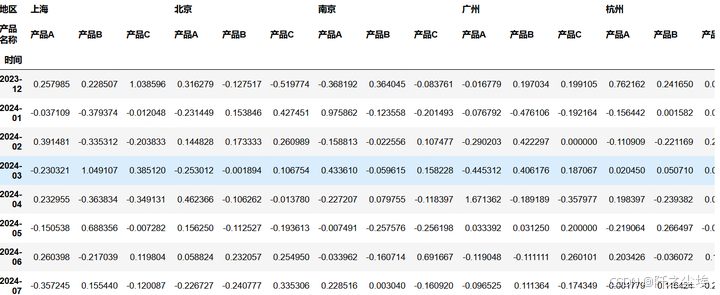
就这么短短几行代码就行了,不比excel方便??
格式化模板样式输出
我们继续,按照自己想要的样式来保存这个Excel表。
一般人做表可能就是添加一下突出单元格规则显示,单元格颜色填充,表头加粗什么的。但是我这里为了演示啥样式python都能实现,也为了考验gpt的理解能力,我就进行了各自花里胡哨的样式添加,什么颜色,填充,字体,下划线,边框,数据条,全部都改一下,所以我的提示词如下:
好,我现在要进行储存,但我想用openxl库进行格式的调整。
1.把pivot_table表头第一层索引使用蓝色填充,字体加大加粗,转为白色,第二层索引使用浅蓝色填充。
2.对产品c的列添加渐变色的数据条,条件格式里面的的数据条。
3.对产品a里面取值大于0.3的单元格浅红色填充,小于0.2的用浅绿色填充。
4.产品b里面大于0.3的单元格的字体加粗,斜线,转为橙色字体,小于0的单元格,边框加满,字体加上下划线
然后gpt就会生成代码:
import pandas as pd
import numpy as np
from openpyxl import Workbook
from openpyxl.styles import PatternFill, Font, Border, Side
from openpyxl.formatting.rule import CellIsRule, ColorScaleRule, DataBarRule
from openpyxl.drawing.image import Image
file_name = 'styled_pivot_table.xlsx'
pivot_table.to_excel(file_name, engine='openpyxl')
# 打开生成的 Excel 文件进行格式化
wb = load_workbook(file_name)
ws = wb.active
# 定义格式
header_fill1 = PatternFill(start_color='0000FF', end_color='0000FF', fill_type='solid') # 蓝色
header_fill2 = PatternFill(start_color='ADD8E6', end_color='ADD8E6', fill_type='solid') # 浅蓝
font_header1 = Font(size=12, bold=True, color='FFFFFF') # 白色字体
# 应用样式到第一层和第二层表头
for cell in ws[1]: # 第一行是第一层表头
cell.fill = header_fill1
cell.font = font_header1
for cell in ws[2]: # 第二行是第二层表头
cell.fill = header_fill2
# 条件格式化
# 为产品C添加数据条
for col in ws.iter_cols(min_row=2, min_col=3, max_col=ws.max_column):
col_header_value = col[0].value
if col_header_value and '产品C' in col_header_value:
col_letter = col[0].column_letter
ws.conditional_formatting.add(f'{col_letter}3:{col_letter}{ws.max_row}',
DataBarRule(start_type='num', start_value=0,
end_type='num', end_value=1,
color='FF638EC6', showValue="None"))
# 为产品A添加特定条件的单元格格式
for col in ws.iter_cols(min_row=2, min_col=1, max_col=ws.max_column):
col_header_value = col[0].value
if col_header_value and '产品A' in col_header_value:
col_letter = col[0].column_letter
# 大于0.3的单元格浅红色填充
ws.conditional_formatting.add(f'{col_letter}3:{col_letter}{ws.max_row}',
CellIsRule(operator='greaterThan', formula=['0.3'],
fill=PatternFill(start_color='FFC7CE', end_color='FFC7CE', fill_type='solid')))
# 小于0.2的单元格浅绿色填充
ws.conditional_formatting.add(f'{col_letter}3:{col_letter}{ws.max_row}',
CellIsRule(operator='lessThan', formula=['0.2'],
fill=PatternFill(start_color='C6EFCE', end_color='C6EFCE', fill_type='solid')))
# 为产品B的特定格式
bold_italic_orange_font = Font(bold=True, italic=True, color='FFA500') # 橙色, 加粗, 斜体
underline_font = Font(underline='single') # 下划线
border_style = Side(border_style='thin', color='000000')
full_border = Border(left=border_style, right=border_style, top=border_style, bottom=border_style)
for col in ws.iter_cols(min_row=2, min_col=1, max_col=ws.max_column):
col_header_value = col[0].value
if col_header_value and '产品B' in col_header_value:
col_letter = col[0].column_letter
# 大于0.3的字体加粗斜体橙色
ws.conditional_formatting.add(f'{col_letter}3:{col_letter}{ws.max_row}',
CellIsRule(operator='greaterThan', formula=['0.3'],
font=bold_italic_orange_font))
# 小于0的单元格加边框和下划线
ws.conditional_formatting.add(f'{col_letter}3:{col_letter}{ws.max_row}',
CellIsRule(operator='lessThan', formula=['0'],
font=underline_font,
border=full_border))
# 保存工作簿
wb.save(file_name)这样,它就把结果表生成好了,我们打开看看效果:
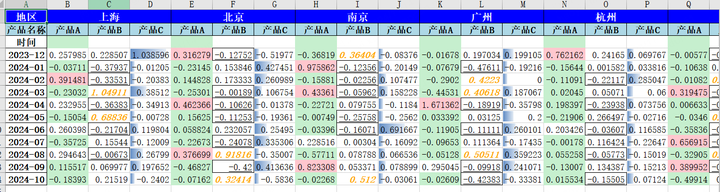
很不错!!!,基本都是按照我的要求来的,美中不足的是产品A我指定的是小于0.2填充为浅绿色,但是它空白的位置也填充为浅绿色了,,,不过无伤大雅。
当然实际工作的表格不可能这么花里胡哨......我只是为了演示 “颜色,填充,字体,下划线,边框,数据条”这些都可以用python调整。并且GPT都能理解,都能写出来,很方便的。
你只需要用自然语言表述出你的需求,然后它写代码,你运行就好了,很简单的。
(当然,也不是完全没门槛,据我观察,很多人是写不出自己的明确需求的.....就我这提示词,他们都写不出来,并且他们很多没有数据思维,可能自己都不知道自己想要的是什么,更别说清楚的表述出来让AI理解了。并且AI也不一定一次都写的对,需要你自己和他反复对话反复调整。但是很多人没这个耐心和能力,觉得AI写的东西不是自己想要的就说它垃圾.....再也不用了....我只能说这种人没有任何自学思维...活该工作效率低)