Inline
内联函数
内联函数是为了替代宏函数而出来的。
下面用宏实现一个ADD宏函数:
为什么这个ADD宏函数要这么写,首先我们来看,假设这样写:
#define ADD(x,y)(x+y)会有什么问题呢?
宏函数是直接替换了:
3|4+3&4=3|7&3我们发现因为优先级问题,宏函数的直接替换导致结果偏离了我们的预设。
所以我们需要加括号保证优先级,但是这样太麻烦了,如果是一个ADD函数就不用这么麻烦:

因为ADD函数不像ADD宏函数那样无脑替换,它会进行先把实参算完再拿过来给形参,把形参算完之后再返回。
但是函数的调用需要建立栈帧,假如我们需要调一万次ADD函数呢?那这个开销就比较大了,我们可以把ADD函数设为内敛函数:
普通函数:
内联函数:
内联不会展开,也就是可以把这个函数的功能拿过来直接用,而不用建立栈帧。
成员变量的命名风格
下文这样来初始化一个日期类的成员变量
#include<iostream>
using namespace std;
class Data
{
public:
void Init(int year,int month,int day)
{
year = year;
month = month;
day = day;
}
private:
int year;
int month;
int day;
};
int main()
{
Data T;
T.Init(2003,11,29);
return 0;
}我们发现并没有初始化上:
原因: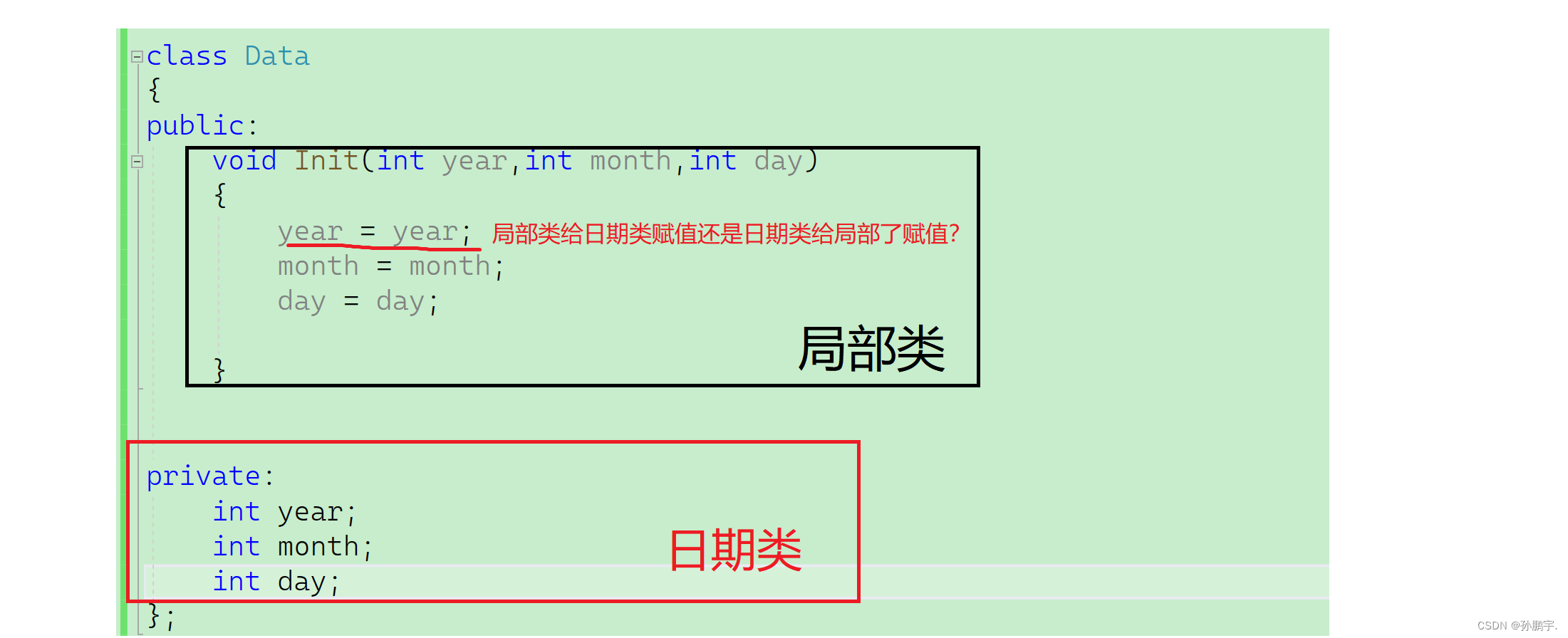
这样写加以区分:
#include<iostream>
using namespace std;
class Data
{
public:
void Init(int year,int month,int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Data T;
T.Init(2003,11,29);
return 0;
}
类的实例化
有这样一个日期类:
class Data
{
public:
void Init(int year,int month,int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};即然有类域,那我们可以这样访问吗?
Data::_year;
Data._year;不可以,因为我们私有的成员变量只是一个声明:
只有声明是不能直接拿来用的,我们需要定义:
Data T;现在定义了一个变量T,就开辟了一块空间,_year,_month,_day的空间也被一把开出来了。
拷贝构造
有如下这么两个类,一个日期类,一个栈类
typedef int DataType;
class Stack
{
public:
Stack(size_t capacity = 3)
{
cout << "Stack()" << endl;
}
// s1(s)
Stack(const Stack& s)
{
cout << "Stack(Stack& s)" << endl;
}
void Push(DataType data)
{
// CheckCapacity();
_array[_size] = data;
_size++;
}
~Stack()
{
cout << "~Stack()" << endl;
}
private:
// 内置类型
DataType* _array;
int _capacity;
int _size;
};class Data
{
public:
void Init(int year,int month,int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;int _month;int _day;
};现在还有一个fun函数,我们把栈类的值拷贝给这个fun函数:
void fun(Data a)
{
}
int main()
{
Data T;
T.Init(2003,11,29);
fun(T);
return 0;
}如果我们把日期类拷贝给fun函数就不会蹦:
void fun1(Data s)
{
}
int main()
{
Data T;
T.Init(2003,11,29);
fun1(T);
return 0;
}
如果我们把栈来拷贝给fun函数就会蹦:
void fun2(Stack s)
{
}
int main()
{
Stack s1;
fun2(s1);
return 0;
}
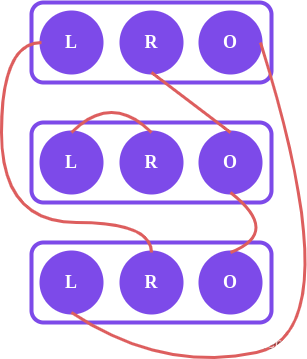
我们可以画图解析一下:
如图,stack的int*_a是在堆上面开辟的空间,内容存在堆上的,_a指向堆。
fun是stack的浅拷贝,fun的_a也指向同一块地址。
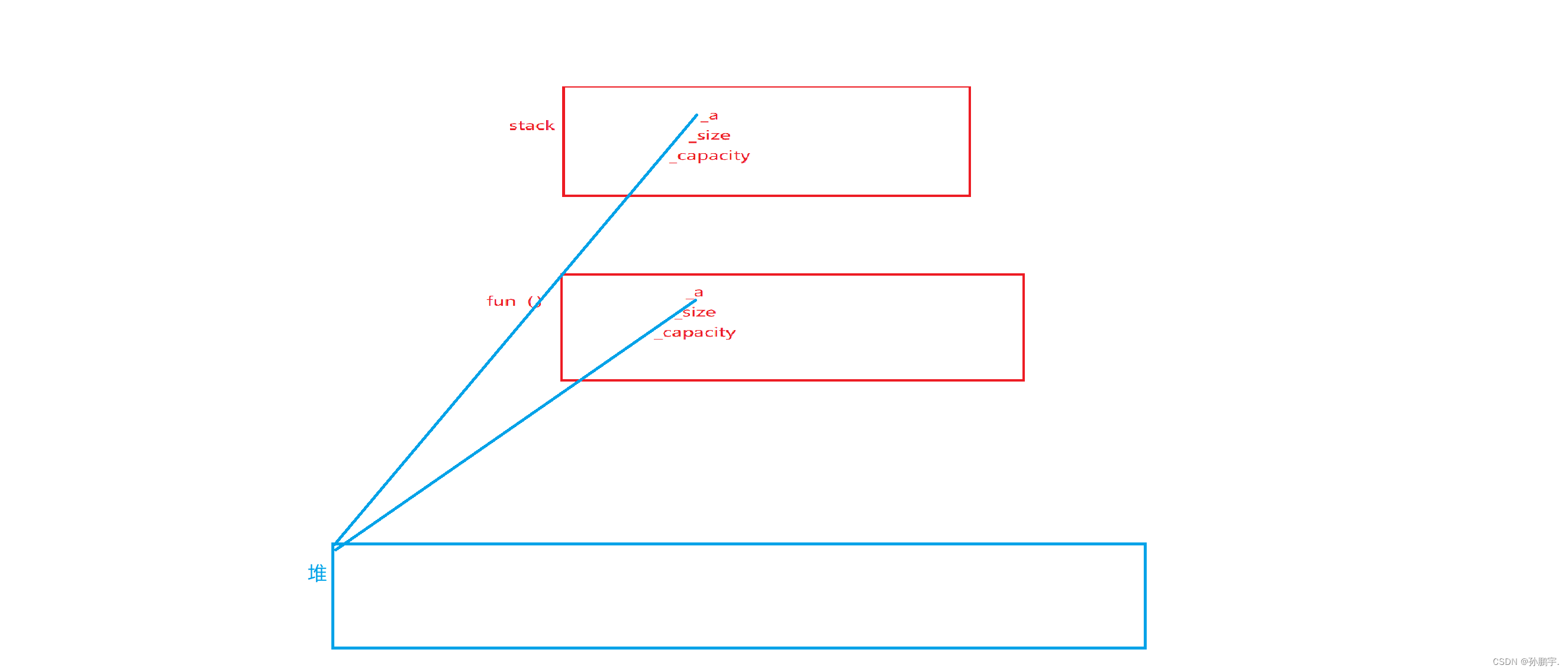
fun后调用,先结束生命周期,先调用析构。此时就把这块空间释放掉了,那么轮到stack的时候会再次调用析构,会再把这块空间释放一次。
看下面这个图,a和s1的_array都指向堆上的同一块地址:

fun函数先析构:

stack再去析构的时候就会报错,因为stack的_a此时是一个野指针,指向了一块已经被释放了的空间: