一.概念
以内存为基准,把磁盘文件中的数据以字节形式读入内存中
二.构造器
public FileInputStream(File file)
public FileInputStream(String pathname)
这两个都是创建字节输入流管道与源文件接通
三.方法
public int read() :每次读取一个字节返回,如果发现没有数据可读,返回-1。
public int read(byte[] buffer) :每次用一个字节数组读取数据,返回字节数组读取了多少字节,如果发现没有数据可读,返回-1.
四.执行
方法一:一个一个字节读
1.代码
package org.example;
import java.io.*;
public class day05 {
public static void main(String[] args) throws IOException {
//1.创建文件字节输入流管道与源文件接通:两种方法都行
InputStream f1 = new FileInputStream(new File("D:\\temp\\day05\\a.txt"));
InputStream f2 = new FileInputStream("D:\\temp\\day05\\a.txt");
//2.读取文件的字节数据
int b1 = f1.read();
System.out.println(b1);
System.out.println((char) b1);
int b2 = f1.read();
System.out.println(b2);
System.out.println((char) b2);
int b3 = f1.read();
System.out.println(b3);
}
}
2.结果

上面代码一个一个字节读太麻烦了,而且读取汉字会乱码,下面进行优化
方法二:循环读
1.代码
package org.example;
import java.io.*;
public class day05 {
public static void main(String[] args) throws IOException {
InputStream f1 = new FileInputStream("D:\\temp\\day05\\b.txt");
int b; //用于记住读取的字节
while((b = f1.read()) != -1){
System.out.print((char)b);
}
f1.close();
}
}
上面代码读取性能很差,且读取汉字会乱码,需要进一步改进 ;流使用完必须要关闭,释放系统资源。
2.结果

方法三:每次读取多个字节
1.代码
package org.example;
import java.io.*;
public class day05 {
public static void main(String[] args) throws IOException {
//b.txt内容:abcdefg
InputStream f1 = new FileInputStream("D:\\temp\\day05\\b.txt");
//开始读取文件中的字节数据,每次读取多个字节
byte[] buffer = new byte[4];
int len = f1.read(buffer);
String s = new String(buffer);
System.out.println(s);
System.out.println("读取的字节数"+len);
int len2 = f1.read(buffer);
String s2 = new String(buffer);
System.out.println(s2);
System.out.println("读取的字节数"+len2);
f1.close();
}
}
2.结果

正常情况下,第二次读取的结果应该是efg而不是efgd
3.改进
package org.example;
import java.io.*;
public class day05 {
public static void main(String[] args) throws IOException {
//b.txt内容:abcdefg
InputStream f1 = new FileInputStream("D:\\temp\\day05\\b.txt");
//开始读取文件中的字节数据,每次读取多个字节
byte[] buffer = new byte[4];
int len = f1.read(buffer);
String s = new String(buffer);
System.out.println(s);
System.out.println("读取的字节数"+len);
int len2 = f1.read(buffer);
String s2 = new String(buffer,0,len2);
System.out.println(s2);
System.out.println("读取的字节数"+len2);
f1.close();
}
}
4.结果

这个代码有待优化,用循环进一步优化
方法四:循环读取
1.代码
package org.example;
import java.io.*;
public class day05 {
public static void main(String[] args) throws IOException {
//b.txt内容:abcdefg
InputStream f1 = new FileInputStream("D:\\temp\\day05\\b.txt");
//开始读取文件中的字节数据,每次读取多个字节
byte[] buffer = new byte[4];
int len;
while ((len = f1.read(buffer)) != -1) {
String s = new String(buffer, 0, len);
System.out.print(s);
}
f1.close();
}
}
2.结果

五.问题
上面代码读取性能提升了,但依旧在读取汉字上会产生乱码
解决方案一:定义一个与文件一样大的字节数组,一次性读取完文件的全部字节(不推荐)
方法1
1.代码
package org.example;
import java.io.*;
public class day05 {
public static void main(String[] args) throws IOException {
//c.txt内容:我们在一起abcd
InputStream f1 = new FileInputStream("D:\\temp\\day05\\c.txt");
//这里的19可以用f1.length()获取
byte[] buffer = new byte[19];
int len;
while ((len = f1.read(buffer)) != -1) {
String s = new String(buffer, 0, len);
System.out.print(s);
}
f1.close();
}
}
2.结果
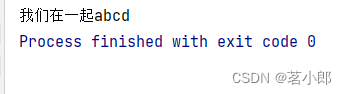
方法2
1.代码
package org.example;
import java.io.*;
public class day05 {
public static void main(String[] args) throws IOException {
//c.txt内容:我们在一起abcd
InputStream f1 = new FileInputStream("D:\\temp\\day05\\c.txt");
final byte[] bytes = f1.readAllBytes();
System.out.println(new String(bytes));
}
}
2.结果
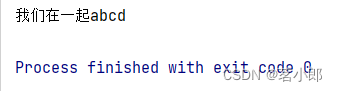
上面代码还有待优化,万一文件特别大,用readAllBytes()会抛出异常。