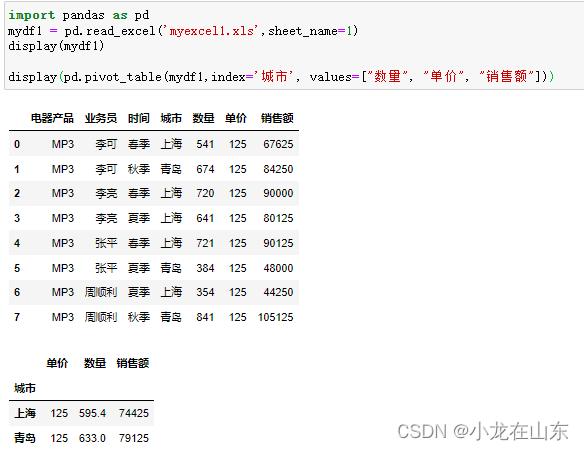
1. 引言
近期,Aztec Labs通过其Immunefi bug bounty program,发出了其有史以来最大的bug bounty——45万美金,给白帽独立安全研究员lucash-dev,以感谢其所发现的Aztec Connect Claim Proof Bug,基本时间轴为:
- 2023年9月12日,收到lucash-dev的submission——声称Aztec Connect在其核心ZK电路中有严重bug。
- 2023年9月12日当天,Aztec团队验证了该submission的有效性,并采取了预防措施(进制公众访问该workflow以避免利用该漏洞)。
- 2023年10月3日,完成补丁修复。
- 2023年10月10日,给该白帽黑客支付了45万美金的bounty。
2. Claim Proof Bug详情
Aztec Connect为针对DeFi应用场景优化的专注隐私的zkRollup系统,使用ZKP来将其系统内的私有交易打包,支持用户相互私有转账,支持向L1合约私有转账。Aztec Connect的显著特性之一是:其DeFi交互,支持用户交换token或在协议内投资。
以多个用户想要对同一L1 DeFi协议投资为例,来说明Aztec Connect的工作原理:
- 1)每个用户向mempool中提交一个DeFi interaction deposit proof。该proof会保持用户身份隐私,但是所投资目标协议和投资金额是公开的。
- 2)sequencer groups试图与同一协议一起交互,一旦sequencer groups有足够的意图来高效切分L1开销,该系统会计算并提交一个rollup proof。
- 3)一旦接收到rollup proof,该智能合约会代替用户,执行实际的投资或交换,接收所返还的tokens。
- 4)在下一rollup,该sequencer完成特殊的claim proofs,给用户切分新收到的tokens。
lucash-dev所发现的bug在claim proof中,且仅可被sequencer利用(如,通过escape hatch)。
核心漏洞在于给特定用户的DeFi interaction计算final output(即,在某DeFi interaction之后能收到多少tokens),可被恶意sequencer欺骗。
若该程序以rust或C编写,则可简单地检查
r
e
s
u
l
t
=
t
o
t
a
l
_
o
u
t
p
u
t
⋅
u
s
e
r
_
i
n
p
u
t
t
o
t
a
l
_
i
n
p
u
t
result=total\_output\cdot \frac{user\_input}{total\_input}
result=total_output⋅total_inputuser_input为整数即可。
但不幸的是,ZK电路基于的是有限域运算,而不是整数运算:
- 因为ZK电路中的基础单位为有限域,需实现复杂的tricks来运行简单的整数运算。若熟悉有限域运算和ZK电路,则可跳过下一节“ZK电路背景知识”内容。
3. ZK电路背景知识
有限域模素数最小教程为:
- 该有限域具有模 p p p,本场景下, p p p是素数(仅可被1和其自身整除)。如 p p p可为5但不可为6。
- 该有限域内所有元素为从0到 p − 1 p-1 p−1的整数。如 F 5 \mathbb{F}_5 F5的元素为 { 0 , 1 , 2 , 3 , 4 } \{0,1,2,3,4\} {0,1,2,3,4}。
- 可做加法运算。若2元素之和大于等于模 p p p,则将其结果减去该模,直到其满足如 3 + 4 = 2 m o d 5 3+4=2\mod 5 3+4=2mod5。
- 对某元素的负数,即为找到与其求和为0的元素,如 1 + 4 = 0 m o d 5 1+4=0\mod 5 1+4=0mod5。
- 乘法运算类似,如 3 ⋅ 3 = 4 m o d 5 3\cdot 3=4\mod 5 3⋅3=4mod5。
- 某元素倒数运算,是指找到与其乘积为1的元素,0没有倒数,其它元素都有相应的倒数。如 4 ⋅ 4 = 1 m o d 5 4\cdot 4=1\mod 5 4⋅4=1mod5。
- 减法运算,是指对其负数做加法运算。除法运算,是指对其倒数做乘法运算。
ZK电路使用有限域运算来包含connected gates。Aztec Connect采用TurboPlonk——可将其看成是对Plonk的扩展指令集。每个gate形式为:
q
m
⋅
w
l
⋅
w
r
+
q
1
⋅
w
l
+
q
2
⋅
w
r
+
q
3
⋅
w
o
+
q
c
=
0
m
o
d
p
q_m\cdot w_l\cdot w_r+q_1\cdot w_l+q_2\cdot w_r+q_3\cdot w_o+q_c=0\mod p
qm⋅wl⋅wr+q1⋅wl+q2⋅wr+q3⋅wo+qc=0modp
其中:
- q m , q 1 , q 2 , q 3 , q c q_m,q_1,q_2,q_3,q_c qm,q1,q2,q3,qc为selectors。由电路编写者选择相应的selectors并定义该电路的逻辑。
- w l , w r , w o w_l,w_r,w_o wl,wr,wo为witness值,可将其看成是某程序执行的中间状态。
该电路中包含很多如上形式的gates,各个
w
w
w值相互以多种方式连接,有些会连接到该电路的输入和输出:
如
y
=
4
x
3
+
2
y=4x^3+2
y=4x3+2,可 以如下gates来表示:
- 1) w l ⋅ w r − w o = 0 m o d p w_l\cdot w_r-w_o=0\mod p wl⋅wr−wo=0modp
- 2) 4 ⋅ w l ⋅ w r − w o + 2 = 0 m o d p 4\cdot w_l\cdot w_r-w_o+2=0\mod p 4⋅wl⋅wr−wo+2=0modp
将第一个gate的 w l w_l wl和 w r w_r wr与第二个gate的 w l w_l wl相连,以表示其对应相同的 x x x值,将第一个gate的 w o w_o wo与第二个gate的 w r w_r wr相连。然后第二个gate的 w o w_o wo为 y y y值。就很容易检查:
- 1) x ⋅ x − x 2 = 0 m o d p x\cdot x-x^2=0\mod p x⋅x−x2=0modp
- 2) 4 ⋅ x ⋅ x 2 − y + 2 = 0 m o d p 4\cdot x\cdot x^2-y+2=0\mod p 4⋅x⋅x2−y+2=0modp
因此,这组具有合适wiring的gates就准确计算了所想表达的 y = 4 x 3 + 2 y=4x^3+2 y=4x3+2。有一些常用标准gates:
- 1) w l ⋅ w r − w r = 0 m o d p w_l\cdot w_r-w_r=0\mod p wl⋅wr−wr=0modp,其中通过wiring有 w l = w r w_l=w_r wl=wr:对应为Boolean gate x ⋅ ( x − 1 ) = 0 m o d p x\cdot (x-1)=0\mod p x⋅(x−1)=0modp,以确保 x x x为0或者1值。
- 2) w l + w r − w o = 0 m o d p w_l+w_r-w_o=0\mod p wl+wr−wo=0modp:为标准加法门。
- 3) w l ⋅ w r − w o = 0 m o d p w_l\cdot w_r-w_o=0\mod p wl⋅wr−wo=0modp:为标准乘法门。
- 4) w l ⋅ w r − 1 = 0 m o d p w_l\cdot w_r-1=0\mod p wl⋅wr−1=0modp:可确保 w l w_l wl为非零值。
- 5)
w
l
1
⋅
w
r
1
−
1
=
0
w_{l_1}\cdot w_{r_1}-1=0
wl1⋅wr1−1=0和
w
l
2
⋅
w
r
2
−
w
o
2
=
0
w_{l_2}\cdot w_{r_2}-w_{o_2}=0
wl2⋅wr2−wo2=0,其中
w
r
1
,
w
r
2
w_{r_1},w_{r_2}
wr1,wr2二者相连:表示
w
o
2
=
w
l
2
w
l
1
w_{o_2}=\frac{w_{l_2}}{w_{l_1}}
wo2=wl1wl2。
- 该gate是电路核心思想的一个很好例子:你无需证明该计算,仅需提供其正确性的witness。
- 为有限域除法运算。求倒数是很重的运算,但展示你找到了相应倒数就trivial多了,仅需要展示二者乘积为1。
3. 基于有限域的整数运算
Aztec Connect中需展示 u s e r _ o u t p u t = t o t a l _ o u t p u t ⋅ u s e r _ i n p u t t o t a l _ i n p u t user\_output=total\_output\cdot \frac{user\_input}{total\_input} user_output=total_output⋅total_inputuser_input为整数,但是是在电路中展示其为整数。
其中的问题之一就在于,整数除法情况下,
u
s
e
r
_
o
u
t
p
u
t
user\_output
user_output大多数情况下都是浮点数,即:
u
s
e
r
_
o
u
t
p
u
t
⋅
t
o
t
a
l
_
i
n
p
u
t
≤
t
o
t
a
l
_
o
u
t
p
u
t
⋅
u
s
e
r
_
i
n
p
u
t
user\_output\cdot total\_input\leq total\_output\cdot user\_input
user_output⋅total_input≤total_output⋅user_input。
因此,需引入除法余数项:【claim ratio equation】
u
s
e
r
_
o
u
t
p
u
t
⋅
t
o
t
a
l
_
i
n
p
u
t
+
r
e
m
a
i
n
d
e
r
=
t
o
t
a
l
_
o
u
t
p
u
t
⋅
u
s
e
r
_
i
n
p
u
t
user\_output\cdot total\_input + remainder = total\_output\cdot user\_input
user_output⋅total_input+remainder=total_output⋅user_input
从而支持满足该约束。但不幸的是,可改变
u
s
e
r
_
o
u
t
p
u
t
user\_output
user_output为任意值,固定
t
o
t
a
l
_
i
n
p
u
t
,
t
o
t
a
l
_
o
u
p
u
t
,
u
s
e
r
_
i
n
p
u
t
total\_input,total\_ouput,user\_input
total_input,total_ouput,user_input值的情况下,只需要调整不同的
r
e
m
a
i
n
d
e
r
remainder
remainder。 我们需确保该relation在整数层面是正确的,而不是在有限域元素层面。为此,需将其每个值拆分为68位limbs,并以school乘法逐元素的相同的方式检查整个relation的正确性。
如
12
⋅
12
=
11
⋅
13
+
1
12\cdot 12=11\cdot 13 +1
12⋅12=11⋅13+1:
- 首先检查低位 2 ⋅ 2 = 1 ⋅ 3 + 1 2\cdot 2=1\cdot 3+1 2⋅2=1⋅3+1,
- 若有进位,则将其加到10位数: 2 ⋅ 1 + 1 ⋅ 2 = 1 ⋅ 3 + 1 ⋅ 1 2\cdot 1+1\cdot 2=1\cdot 3+1\cdot 1 2⋅1+1⋅2=1⋅3+1⋅1
- 检查百位数: 1 ⋅ 1 = 1 ⋅ 1 1\cdot 1=1\cdot 1 1⋅1=1⋅1
当做类似计算时,只需要在内存中计算各个位的乘积,因此不会溢出。用相同的方式来对该claim ratio equation实现整数检查,但limbs(digits)取值范围为 [ 0 , 2 68 − 1 ] [0,2^{68}-1] [0,268−1],而不是 [ 0 , 9 ] [0,9] [0,9]。且每个数字包含4个这样的limbs。因此,有如下代码来实现该check:
// takes a [204-208]-bit limb and splits it into a low 136-bit limb and a high 72-bit limb
const auto split_out_carry_term = [&composer, &shift_2](const field_ct& limb) {
const uint256_t limb_val = limb.get_value();
const uint256_t lo_val = limb_val.slice(0, 68 * 2);
const uint256_t hi_val = limb_val.slice(68 * 2, 256);
const field_ct lo(witness_ct(&composer, lo_val));
const field_ct hi(witness_ct(&composer, hi_val));
lo.create_range_constraint(68 * 2);
hi.create_range_constraint(72); // allow for 4 overflow bits
limb.assert_equal(lo + (hi * shift_2));
return std::array<field_ct, 2>{ lo, hi };
};
// Use schoolbook multiplication algorithm to multiply 2 4-limbed values together, then convert result into 4
// 2-limb values (with limbs twice the size) that do not overlap
const auto compute_product_limbs = [&split_out_carry_term, &shift_1](const std::array<field_ct, 4>& left,
const std::array<field_ct, 4>& right,
const std::array<field_ct, 4>& to_add,
const bool use_residual = false) {
// a = left[0] * right[0];
const field_ct b = left[0].madd(right[1], left[1] * right[0]);
const field_ct c = left[0].madd(right[2], left[1].madd(right[1], left[2] * right[0]));
const field_ct d = left[0].madd(right[3], left[1].madd(right[2], left[2].madd(right[1], left[3] * right[0])));
const field_ct e = left[1].madd(right[3], left[2].madd(right[2], left[3] * right[1]));
const field_ct f = left[2].madd(right[3], left[3] * right[2]);
// g = left[3] * right[3];
if (use_residual) {
const auto t0 =
split_out_carry_term(to_add[0] + left[0].madd(right[0], (b * shift_1) + to_add[1] * shift_1));
const auto r0 = t0[0];
const auto t1 = split_out_carry_term(t0[1].add_two(c + to_add[2], to_add[3] * shift_1 + d * shift_1));
const auto r1 = t1[0];
const auto t2 = split_out_carry_term(t1[1].add_two(e, f * shift_1));
const auto r2 = t2[0];
const auto r3 = left[3].madd(right[3], t2[1]);
return std::array<field_ct, 4>{ r0, r1, r2, r3 };
}
const auto t0 = split_out_carry_term(left[0].madd(right[0], (b * shift_1)));
const auto r0 = t0[0];
const auto t1 = split_out_carry_term(t0[1].add_two(c, d * shift_1));
const auto r1 = t1[0];
const auto t2 = split_out_carry_term(t1[1].add_two(e, f * shift_1));
const auto r2 = t2[0];
const auto r3 = left[3].madd(right[3], t2[1]);
return std::array<field_ct, 4>{ r0, r1, r2, r3 };
};
const auto lhs = compute_product_limbs(left_1, right_1, { 0, 0, 0, 0 }, false);
const auto rhs = compute_product_limbs(left_2, right_2, residual_limbs, true);
bool_ct balanced(&composer, true);
for (size_t i = 0; i < 4; ++i) {
balanced = balanced && lhs[i] == rhs[i];
}
return balanced;
需将每个值切分为4个limbs来表示:
v
a
l
u
e
=
v
a
l
u
e
0
+
v
a
l
u
e
1
⋅
2
68
+
v
a
l
u
e
2
⋅
2
136
+
v
a
l
u
e
3
⋅
2
204
m
o
d
p
value=value_0+value_1\cdot 2^{68}+value_2\cdot 2^{136}+value_3\cdot 2^{204}\mod p
value=value0+value1⋅268+value2⋅2136+value3⋅2204modp
每个limb限定范围为68位,以确保分解正确(范围约束可很容易通过从boolean gaates组合witness来实现)。
该漏洞源自2个核心问题:
- 1)该top limb被限定为68位
- 2)对该remainder没有任何范围限制
// Split a field_t element into 4 68-bit limbs
const auto split_into_limbs = [&composer, &shift_1, &shift_2, &shift_3](const field_ct& input) {
const uint256_t value = input.get_value();
const uint256_t t0 = value.slice(0, 68);
const uint256_t t1 = value.slice(68, 136);
const uint256_t t2 = value.slice(136, 204);
const uint256_t t3 = value.slice(204, 272);
std::array<field_ct, 4> limbs{
witness_ct(&composer, t0),
witness_ct(&composer, t1),
witness_ct(&composer, t2),
witness_ct(&composer, t3),
};
field_ct limb_sum_1 = limbs[0].add_two(limbs[1] * shift_1, limbs[2] * shift_2);
field_ct limb_sum_2 = input - (limbs[3] * shift_3);
limb_sum_1.assert_equal(limb_sum_2);
limbs[0].create_range_constraint(68);
limbs[1].create_range_constraint(68);
limbs[2].create_range_constraint(68);
limbs[3].create_range_constraint(68); // The offending range constraint
return limbs;
};
若想通过分解,约束某值在
2
252
2^{252}
2252到
2
272
2^{272}
2272范围内,若该range constraint为
2
252
2^{252}
2252,则可能丢失一一对应关系。现在对应每个原始值,其由
2
20
2^{20}
220个可能值。更具体来说,由于所有的运算都是对模
p
p
p的取模运算,可在分解中加上
p
p
p,在重构该值是额外的
p
p
p将会小时,因此,原始的整数层面的claim ratio equation将更新为:
(
u
s
e
r
_
o
u
t
p
u
t
+
a
⋅
p
)
⋅
(
t
o
t
a
l
_
i
n
p
u
t
+
b
⋅
p
)
+
r
e
m
a
i
n
d
e
r
+
c
⋅
p
=
(
t
o
t
a
l
_
o
u
t
p
u
t
+
d
⋅
p
)
⋅
(
u
s
e
r
_
i
n
p
u
t
+
e
⋅
p
)
(user\_output+a\cdot p)\cdot (total\_input+b\cdot p) + remainder + c\cdot p = (total\_output+d\cdot p)\cdot (user\_input+e\cdot p)
(user_output+a⋅p)⋅(total_input+b⋅p)+remainder+c⋅p=(total_output+d⋅p)⋅(user_input+e⋅p)
为简化,即假设
u
s
e
r
_
i
n
p
u
t
=
1
user\_input=1
user_input=1,可设置
a
=
0
,
b
=
0
,
c
=
0
,
d
=
1
,
e
=
0
a=0,b=0,c=0,d=1,e=0
a=0,b=0,c=0,d=1,e=0,然后获得equation:
u
s
e
r
_
o
u
t
p
u
t
⋅
t
o
t
a
l
_
i
n
p
u
t
+
r
e
m
a
i
n
d
e
r
=
t
o
t
a
l
_
o
u
t
p
u
t
+
p
user\_output\cdot total\_input + remainder = total\_output + p
user_output⋅total_input+remainder=total_output+p
可调整不同的 u s e r _ o u t p u t user\_output user_output值,只要 u s e r _ o u t p u t ⋅ t o t a l _ i n p u t > t o t a l _ o u t p u t user\_output\cdot total\_input > total\_output user_output⋅total_input>total_output且 u s e r _ o u t p u t ⋅ t o t a l _ i n p u t − t o t a l _ o u t p u t ≤ p user\_output\cdot total\_input - total\_output \leq p user_output⋅total_input−total_output≤p,则将能计算出合适的remainder,由于remainder未被约束,且控制 u s e r _ i n p u t user\_input user_input给了偷TVL的机制。
4. 补丁
首要的问题是禁止对ratio equation中各个不同部分乘以 p p p的动作。如,可简单的对各个limbs做范围约束,使得原始值与切分后的值之间存在一一对应关系:
// Split a field_t element into 4 68-bit limbs
const auto split_into_limbs = [&composer, &shift_1, &shift_2, &shift_3](const field_ct& input,
const size_t MAX_INPUT_BITS) {
const uint256_t value = input.get_value();
constexpr size_t NUM_BITS_PER_LIMB = 68;
ASSERT(MAX_INPUT_BITS <= MAX_NO_WRAP_INTEGER_BIT_LENGTH);
ASSERT(MAX_INPUT_BITS > 0);
const uint256_t t0 = value.slice(0, NUM_BITS_PER_LIMB);
const uint256_t t1 = value.slice(NUM_BITS_PER_LIMB, 2 * NUM_BITS_PER_LIMB);
const uint256_t t2 = value.slice(2 * NUM_BITS_PER_LIMB, 3 * NUM_BITS_PER_LIMB);
const uint256_t t3 = value.slice(3 * NUM_BITS_PER_LIMB, 4 * NUM_BITS_PER_LIMB);
std::array<field_ct, 4> limbs{
witness_ct(&composer, t0),
witness_ct(&composer, t1),
witness_ct(&composer, t2),
witness_ct(&composer, t3),
};
field_ct limb_sum_1 = limbs[0].add_two(limbs[1] * shift_1, limbs[2] * shift_2);
field_ct limb_sum_2 = input - (limbs[3] * shift_3);
limb_sum_1.assert_equal(limb_sum_2);
// Since the modulus is a power of two minus one, we can simply range constrain each of the limbs
size_t bits_left = MAX_INPUT_BITS;
for (size_t i = 0; i < 4; i++) {
// If we've run out of bits, enforce zero
if (bits_left == 0) {
limbs[i].assert_is_zero();
// If there are not enough bits for a full lmb, reduce constraint
} else if (bits_left < NUM_BITS_PER_LIMB) {
limbs[i].create_range_constraint(bits_left);
bits_left = 0;
} else {
// Just a regular limb
limbs[i].create_range_constraint(NUM_BITS_PER_LIMB);
bits_left -= NUM_BITS_PER_LIMB;
}
}
return limbs;
};
令一个问题是,若remainder未被约束,则即使约束了limbs,sequencer仍可能创建为depositor分配比其应得而少得多金额的proof。
观察
u
s
e
r
_
o
u
t
p
u
t
⋅
t
o
t
a
l
_
i
n
p
u
t
+
r
e
m
a
i
n
d
e
r
=
t
o
t
a
l
_
o
u
t
p
u
t
⋅
u
s
e
r
_
i
n
p
u
t
user\_output\cdot total\_input + remainder = total\_output\cdot user\_input
user_output⋅total_input+remainder=total_output⋅user_input equation可知,可保持
t
o
t
a
l
_
i
n
p
u
t
total\_input
total_input不变,通过增加
r
e
m
a
i
n
d
e
r
remainder
remainder来降低
u
s
e
r
_
o
u
t
p
u
t
user\_output
user_output。因此,还需要对
r
e
m
a
i
n
d
e
r
remainder
remainder添加约束
r
e
m
a
i
n
d
e
r
∈
[
0
,
t
o
t
a
l
i
n
p
u
t
)
remainder\in[0,total_input)
remainder∈[0,totalinput):
residual.create_range_constraint(notes::NOTE_VALUE_BIT_LENGTH, "ratio_check range constraint failure: residual");
// We need to assert that residual < a2
// i.e. a2 - residual > 0 => a2 - residual - 1 >= 0
(ratios.a2 - residual - 1)
.normalize()
.create_range_constraint(notes::NOTE_VALUE_BIT_LENGTH, "ratio_check range constraint failure: residual >= a2");
5. 结论
任何像Aztec Connect这样的大型项目,都需要额外注意安全实现,即使其代码以经过大量审计,该bug还是漏了。
如何在未来系统中尽可能减少类似bug的概率呢?未来Aztec Labs计划做如下流程改进,以避免类似bug:
- 1)实现一种机制,使得所有ad-hoc原语实现均禁止。若需要做整数比较,则该代码必须走标准库,应标准库已重点检查过了。
- 2)创建探测未约束值的自动工具,并让审计者重点关注这些未约束值和所派生值。
尽可能让人为错误影响最小化,对于构建强健系统来说至关重要,因此做冗余和自动化测试非常有价值。
参考资料
[1] 2023年10月hackmd Aztec Connect Claim Proof Bug
[2] 2023年10月Aztec Labs博客Aztec Labs Announces Our Largest-Ever Bug Bounty Of $450,000
Aztec系列博客
- Aztec Hybrid Rollup:混合zkRollup,而非zkEVM
- Proof Compression
- Aztec Connect即将主网上线
- Aztec connect bridge代码解析
- Aztec 征集 Rollup Sequencer去中心化提案
- Aztec的隐私抽象:在尊重EVM合约开发习惯的情况下实现智能合约隐私
- 完全保密的以太坊交易:Aztec网络的隐私架构
- Aztec.nr:Aztec的隐私智能合约框架——用Noir扩展智能合约功能
- Aztec交易架构解析
- 混合Rollup:探秘 Metis、Fraxchain、Aztec、Miden和Ola