Pandas使用pivot_table()方法和crosstab()方法实现透视表。
pivot_table()方法及参数
pivot_table()方法的语法格式如下:
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
data 用来设置要操作的DataFrame数据表。
values 用来设置要计算的列。
Index 用来设置行分组的索引。
columns 用来设置列分组索引。
aggfunc 用来设置进行数据计算的聚合函数或函数列表,默认是求平均。
fill_value 用来设置默认值。
margins 用来设置是否添加行或列的总计。
dropna 如果某一列所有值都是NaN时,该参数用来决定是否删除该列,默认值为True表示删除。
margins_name 当margins为True时,设置margins 行或列的名称,默认为All。
实例
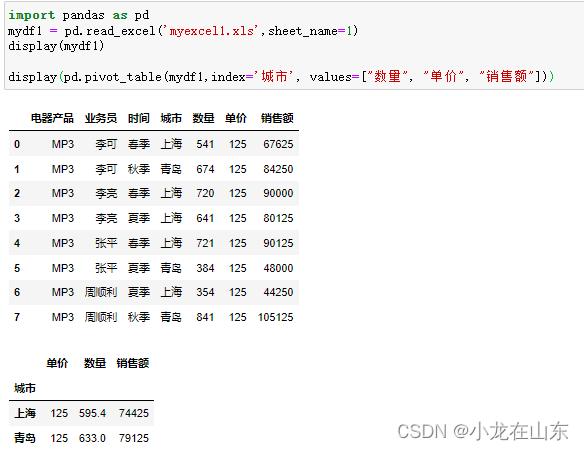
import pandas as pd
mydf1 = pd.read_excel('myexcel1.xls',sheet_name=1)
display(mydf1)
display(pd.pivot_table(mydf1,index='城市', values=["数量", "单价", "销售额"]))