一、作者
Kai Zhang、Kun Zhang、Mengdi Zhang、Hongke Zhao、Qi Liu、Wei Wu、Enhong Chen
School of Data Science, University of Science and Technology of China
School of Computer Science and Information Engineering, Hefei University of Technology
Meituan
College of Management and Economics, Tianjin University
二、背景
BERT的出现引起了人们对增强语义表示的关注,一些基于BERT、注意力机制以及句法知识的研究也取得了一定的成果,但是在方面情感分析中直接应用注意力机制或微调预训练的BERT时仍然存在一些问题。
首先,大多数现有方法会一次性从句子中选择所有被认为重要的单词。然而,根据神经科学研究,语义理解中的关键词往往会随着阅读过程而动态变化,因此应当反复考虑。
其次,在ABSA任务中简单地使用BERT进行编码效果提升并不明显,因为丰富的资源使得BERT更倾向于关注整个句子的语义,但方面情感分析是有条件的,模型需要基于局部语义来分析不同的方面。
三、创新点
作者为了让模型能够更好地理解方面感知动态语义(aspect-aware dynamic semantics),提出了Dynamic Re-weighting BERT(DR-BERT)模型。
该模型首先利用BERT来学习整个句子的整体语义,然后通过将轻量级的**动态重加权适配器(DRA)**整合到每个BERT编码器层并对其进行微调以适应ABSA任务,其中动态重加权适配器能够将更多的注意力集中在一个更小的区域,并在每一步动态选择并修改关键词的权重。
四、具体实现
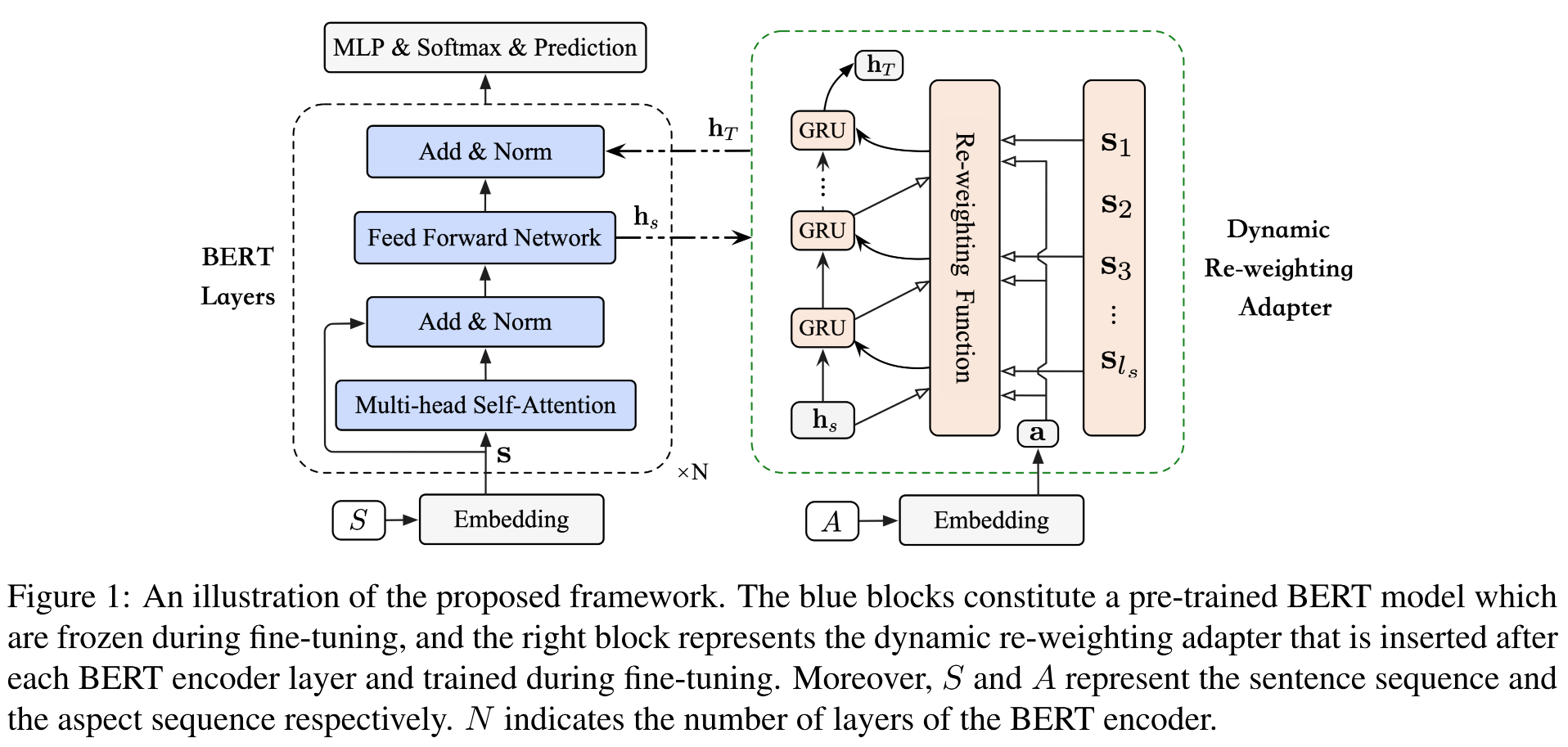
1.嵌入模块
为了更好地表示方面词和上下文词(context word)的语义信息,作者利用嵌入模块将每个单词都映射为低维向量。
对于输入的句子序列 S S S,借助于BERT嵌入可以将 S S S转化为隐藏状态 s = { s i ∣ i = 1 , 2 , … , l s } \mathbf{s} = \{\mathbf{s}_i|i = 1, 2, \dots, l_s\} s={si∣i=1,2,…,ls},我们也可以将隐藏状态 s \mathbf{s} s从某种程度上解释为当前单词的上下文表示。
对于输入的方面序列 A A A,借助于嵌入模块可以将 A A A映射为单词嵌入 a s = { a j ∣ j = 1 , 2 , … , l a } \mathbf{a}^s = \{\mathbf{a}_j|j = 1, 2, \dots, l_a\} as={aj∣j=1,2,…,la},由于某些方面(如“系统存储”)可能由多个单词组成,因此还要借助于 a = { a 1 , l a = 1 ( ∑ j = 1 l a ) / l a , l a > 1 \mathbf{a} = \begin{cases} \mathbf{a}_1, l_a = 1 \\ (\sum_{j=1}^{l_a})/l_a, l_a > 1 \end{cases} a={a1,la=1(∑j=1la)/la,la>1将单词嵌入转化为方面嵌入 a \mathbf{a} a。
2.BERT编码器
a.多头自注意力机制
作者采用具有h个头的MultiHead来获取整个句子的整体语义,输出特征 m \mathbf{m} m的计算过程为: m = { m i ∣ i = 1 , 2 , … , l s } = M u l t i H e a d ( s W h Q , s W h K , s W h V ) \mathbf{m} = \{\mathbf{m}_i|i = 1, 2, \dots, l_s\} = \mathbf{MultiHead}(\mathbf{sW}_h^Q, \mathbf{sW}_h^K, \mathbf{sW}_h^V) m={mi∣i=1,2,…,ls}=MultiHead(sWhQ,sWhK,sWhV)。
b.位置前馈网络
数据经过Self-Attention处理后会交给前馈神经网络,作者采用的FFN由两个线性变换以及二者之间的ReLU激活组成,处理过程可以表示为: f = { f i ∣ i = 1 , 2 , … , l s } = m a x ( 0 , m W 1 + b 1 ) W 2 + b 2 \mathbf{f} = \{\mathbf{f}_i|i = 1, 2, \dots, l_s\} = \mathbf{max}(0, \mathbf{mW}_1 + \mathbf{b}_1)\mathbf{W}_2 + \mathbf{b}_2 f={fi∣i=1,2,…,ls}=max(0,mW1+b1)W2+b2。
作者还利用最大池操作来公平地选择句子中的关键特征,以便在每个重加权步骤开始时获得原始句子表示 h s \mathbf{h}_s hs: h s = M a x _ P o o l i n g ( f i ∣ i = 1 , 2 , … , l s ) \mathbf{h}_s = \mathrm{Max\_Pooling}(\mathbf{f}_i|i = 1, 2, \dots, l_s) hs=Max_Pooling(fi∣i=1,2,…,ls)。
3.动态重加权适配器
DRA的输入包括BERT编码器的输出 h s \mathbf{h}_s hs和初始的方面嵌入 a \mathbf{a} a。
在DRA处理过程的每一步中,首先利用重加权注意力从输入序列 s \mathbf{s} s中为当前输入选择单词。然后利用门控循环单元(GRU)对所选词进行编码并更新语义表示。
DRA中每一步的处理过程可以表示为: a t = F ( s , h t − 1 , a ) \mathbf{a}_t = F(\mathbf{s}, \mathbf{h}_{t-1}, \mathbf{a}) at=F(s,ht−1,a), h t = G R U ( a t , h t − 1 ) \mathbf{h}_t = GRU(\mathbf{a}_t, \mathbf{h}_{t-1}) ht=GRU(at,ht−1),其中 F F F为重加权函数,DRA的初始状态为 h 0 = h s \mathbf{h}_0 = \mathbf{h}_s h0=hs,经过 T T T次处理后便得到了最终的输出 h T \mathbf{h}_T hT。
其中,重加权函数 F F F借助于注意力机制实现,它的目的是在每一步选择最重要的方面相关词(aspect-related word)。重加权过程可以表示为: M = W s s + ( W d h t − 1 + W a a ) ⊗ w \mathbf{M} = \mathbf{W}_s\mathbf{s} + (\mathbf{W}_d\mathbf{h}_{t-1} + \mathbf{W}_a\mathbf{a}) \otimes \mathbf{w} M=Wss+(Wdht−1+Waa)⊗w, m = ω T t a n h ( M ) \mathbf{m} = \omega^T\mathrm{tanh}(\mathbf{M}) m=ωTtanh(M), a t = ∑ i = 1 l s exp ( λ m i ) ∑ k = 1 l s exp ( λ m k ) s i \mathbf{a}_t = \displaystyle\sum_{i=1}^{l_s} \frac{\exp(\lambda m_i)}{\sum_{k=1}^{l_s}\exp(\lambda m_k)}\mathbf{s}_i at=i=1∑ls∑k=1lsexp(λmk)exp(λmi)si,其中 s \mathbf{s} s表示初始的句子嵌入, W s \mathbf{W}_s Ws、 W d \mathbf{W}_d Wd、 W a \mathbf{W}_a Wa和 ω \omega ω均为可训练的参数, m i m_i mi为第i个单词的隐藏状态。当超参数 λ \lambda λ为任意大值时,所选词的注意力得分无限接近1,其他词的注意力得分无限接近0,这样每一个重加权步骤都会从上下文中提取出一个与特定方面最相关的词 a t \mathbf{a}_t at。
4.情感分类
经过N层的BERT和DRA的处理,句子的初始表示 s \mathbf{s} s被转变为特征表示 e N \mathbf{e}_N eN,然后我们将它交给多层感知机(MLP)并借助于softmax层将其映射到不同情感极性的概率分布上,即: R l = R e l u ( W l R l − 1 + b l ) \mathbf{R}_l = \mathrm{Relu}(\mathbf{W}_l\mathbf{R}_{l-1} + \mathbf{b}_l) Rl=Relu(WlRl−1+bl), y ^ = s o f t m a x ( W o R h + b o ) \hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{W}_o\mathbf{R}_h + \mathbf{b}_o) y^=softmax(WoRh+bo),其中 R l \mathbf{R}_l Rl为MLP每一层输出的隐藏状态, R h \mathbf{R}_h Rh则为MLP最终层的输出, y ^ \hat{\mathbf{y}} y^为预测的情感极性分布。
五、实验
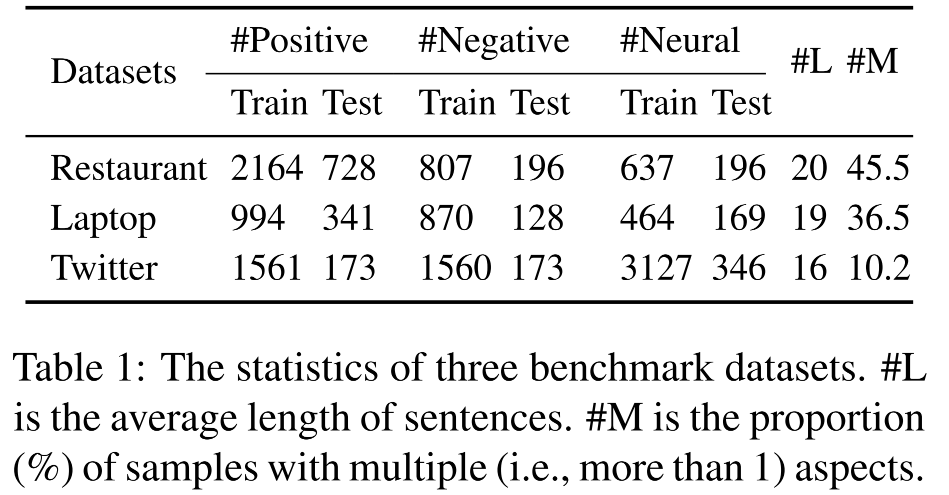
作者采用了Laptop(Pontiki et al., 2014)、Restaurant(Pontiki et al., 2014)和Twitter(Dong et al., 2014)三个数据集作为实验数据集。数据集基本情况如下:
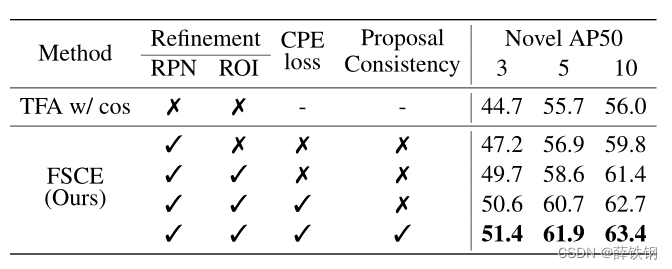
作者采用的基准模型主要分为基于注意力机制的模型和基于预训练的模型两大类,这些基线方法全面覆盖了最近的相关SOTA模型。作者的实验结果如下所示:
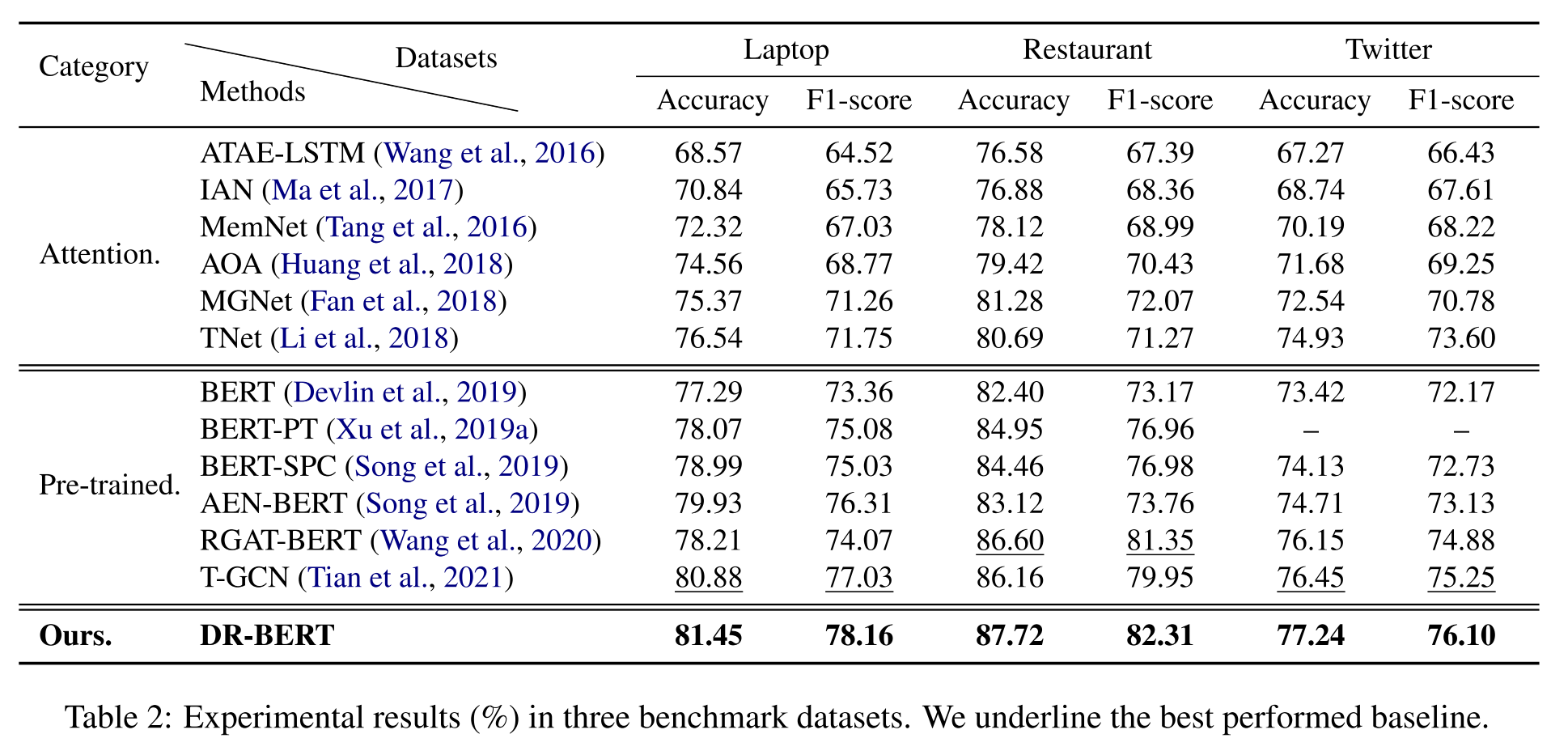
通过实验结果可以发现,基于BERT的方法打败了绝大多数的基于注意力的方法,这个现象也表明了预训练语言模型的强大能力。此外,任务特定的BERT模型表现得也比非特定的模型更好,这说明方面相关信息是ABSA模型性能的关键影响因素。当然,作者的模型也取得了最好的效果。
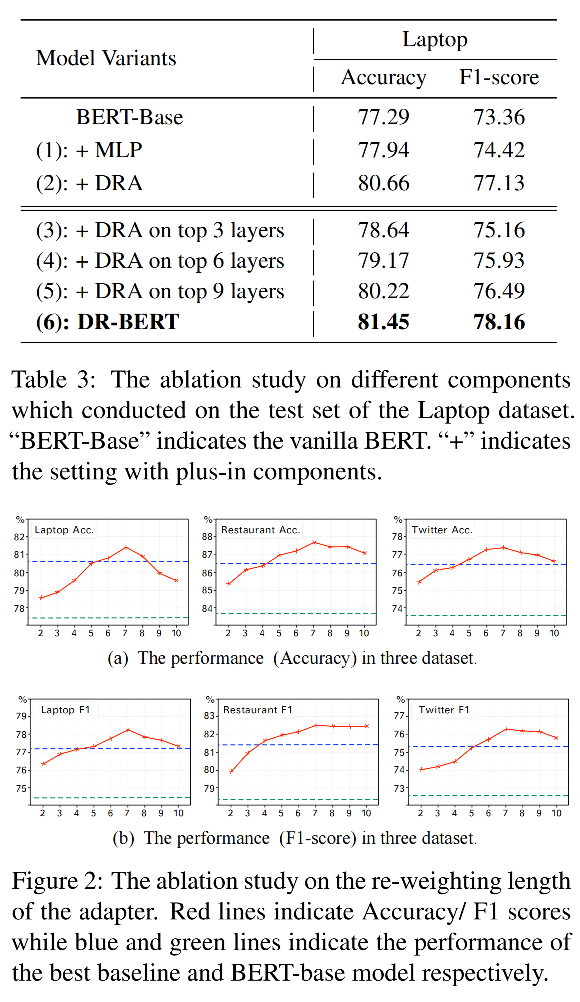
作者的消融实验如下图所示,通过结果可以看出,DRA在最终的情绪预测中比MLP起着更重要的作用。同时,重加权长度在7左右时能取得最好的效果,这种现象与人类记忆集中在近七个单词的心理学发现是一致的。