论文地址:https://arxiv.org/pdf/2103.05950.pdf
代码地址:https://github.com/megvii-research/FSCE
对比学习https://zhuanlan.zhihu.com/p/346686467
目录
- 1、存在的问题
- 2、算法简介
- 3、算法细节
- 3.1、new-baseline
- 3.2、对比建议编码
- 3.3、对比建议编码的损失
- 4、实验
- 验证实验
- 消融实验
- 5、结论
1、存在的问题
小样本目标检测的方法存在的不足是:分类任务相对回归任务的错误率更高。 目标框定位通常很准确,但是目标的类别识别经常发生错误。

样本不足,新类学习到的特征不足以去和基类中相近的目标进行区分,所以新类别容易被归结为基类中易混淆的类。
对比学习可以通过降低不同类别目标的相似性来减小类内差异,增大类间差异,这样就可以减少对于相似类别的误判。
对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。
2、算法简介
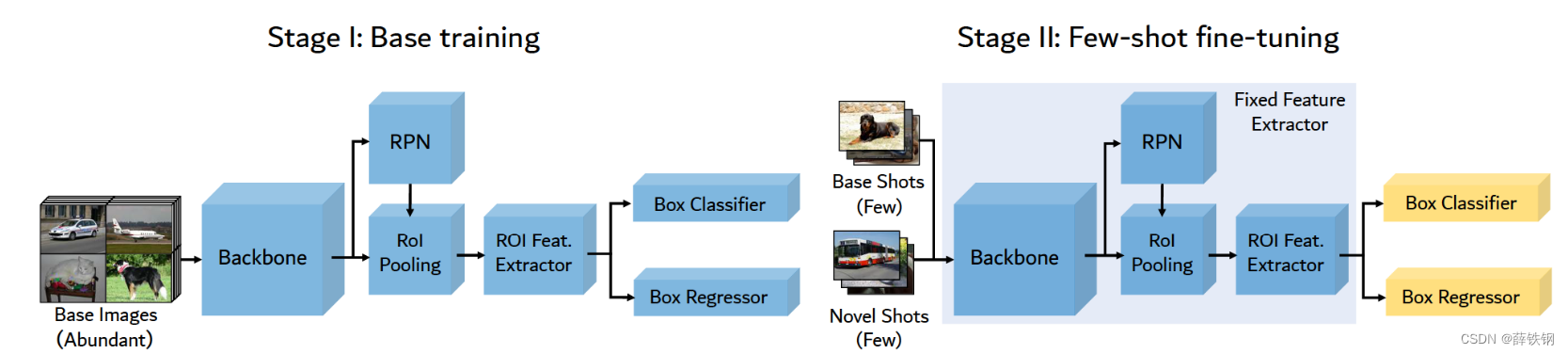
是一个基于微调fine-tune的方法。 第一次将对比学习引入到了小样本目标检测中来。
提出了一种 基于对比建议编码(FSCE)的小样本目标检测方法 ,在RoI 特征提取后添加了一个和回归、分类分支并行的 建议框对比编码(CPE)分支。
训练过程:
首先,使用丰富的基类数据(Dtrain=Dbase)训练Faster R-CNN检测模型。
然后,将训练好的模型迁移到小数据集上。小数据集是由新类和随机抽样的基类组成的混合数据集(
D
t
r
a
i
n
=
D
n
o
v
e
l
∪
D
b
a
s
e
Dtrain=Dnovel\cup Dbase
Dtrain=Dnovel∪Dbase)。在微调过程中,主干特征提取网络被冻结,联合优化回归损失、分类损失和对比建议损失。

3、算法细节
3.1、new-baseline
首先,回顾一下原始两阶段微调方法TFA:
1、在基本训练阶段,利用大量的基类样本对普通的两阶段目标检测网络(如Faster-RCNN等)进行训练。这个阶段是在基类上联合训练整个目标检测器,包括特征提取器和box预测器。
2、在微调阶段,在保持整个特征提取器不变的情况下,将新类随机初始化的权值分配给box预测网络,只微调box分类和回归网络,其他特征提取组件都被冻结了。
因此,其他网络层完全没有参与到新类的训练过程中,RPN,ROI特征提取器只包含从基类中学到的语义信息,这其实可以看作是一种对新类的过拟合训练。
同时,作者发现,在微调阶段,正样本的建议框数量只有基础训练时的1/4,因为许多包含新类别的建议框的置信度很低,会被NMS过滤掉,导致前景建议框的数量也随之减少,网络学习新类别的机会变少。
本文在TFA的基础上提出了一种new-baseline。
new-baseline在解冻RPN和ROI模块的同时应用了以下的两个策略:
1、在微调阶段,原始的TFA的RPN提出来的区域建议框较少, new-baseline使得经过NMS的建议框的最大数量扩大了两倍。 这就带来了更多的前景,相当于增加正样本的数量。
2、标准的ROI的batchsize是512,但前景建议框的数量比512的一半还少,因此 将ROI head 中用于损失计算的抽样建议框的数量减少一半。 相当于增加了前景建议框的数量,使得网络学习到了更多的新类特征。
3.2、对比建议编码
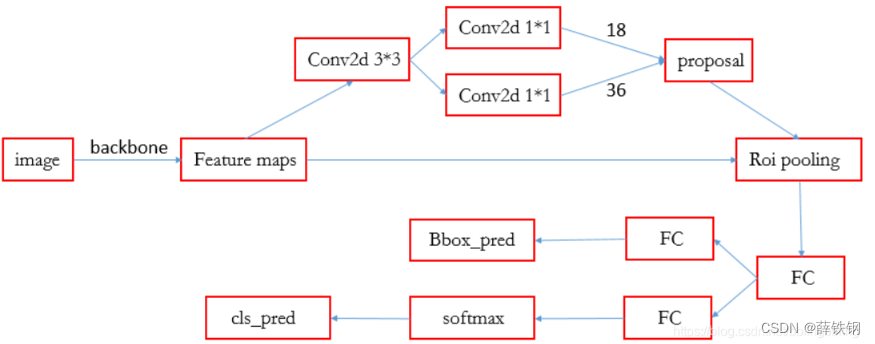
首先,再来回顾一下Faster R-CNN的总体流程:
1、Backbone:conv+relu+pooling.
输入:图像
功能:提取输入图像的特征图
输出:特征图
2、RPN:
输入:Backbone的特征图
功能:生成建议框proposal
输出:建议框proposal
3、ROI Pooling:
输入:建议框proposal 和 Backbone的特征图
功能:将建议框proposal映射到Backbone的特征图上得到proposal feature maps,并将不同大小的proposal feature maps调整至统一大小
输出:一组向量(向量个数=建议框数量,向量大小=CxWxH,其中C为通道数,W=7,H=7)
4、分类分支:
输入:proposal feature maps
功能:得到区域建议框的类别
输出:cls_prob概率向量(区域建议框属于各个类别的概率)
5、回归分支:
输入:proposal feature maps
功能:确定目标检测框的精确位置
输出:每个proposal的位置偏移量bbox_pred
6、ROI head:
是由ROI pooling,box_head以及box_predictor结合在一起的,在Faster R-CNN中,ROI head对RPN产生的proposal进行pooling生成1024维的特征向量,再对该特征向量进行分类,以及bbox回归。
但是常规检测器无法为有限类别的区域建议框建立稳健的特征表示,即对于少样本来说是不够健壮的。
根据实验,在少样本的情况下,正样本分类器不能很好的区分它们。
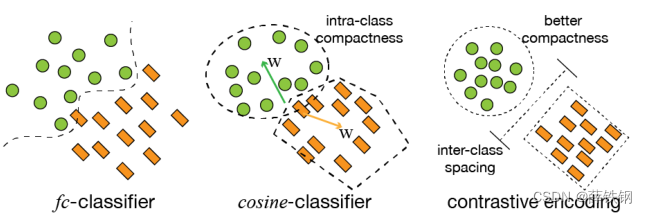
为了更好的从小样本中学到更多的目标特征表示,文章提出了一种 批量对比学习方法(batch contrastive learning) 来更好的对 类内相似性 和 类间差异性 特征进行建模。
具体做法是 在ROI head中加入了一个对比分支(contrastive branch),与回归和分类分支并行,用于度量建议框的相似性
对比分支使用1层多层感知机( 1层神经网络),将1 * 1024的ROI特征转化为1 * 128维的对比特征向量 x i x_{i} xi。随后,计算对比特征向量的相似度分数,并将对比分支的损失加入到总的损失函数中进行优化,使得不同类别距离增大,相同类别距离减少。
采用基于余弦相似度的边界框分类器,计算出RoI 与各个类别的相似性度量。下式表示第 i 个 RoI 与第 j 个类别的相似性度量:
l
o
g
i
t
{
i
,
j
}
=
α
x
i
T
w
j
∣
∣
x
i
∣
∣
⋅
∣
∣
w
j
∣
∣
logit_{\{i,j\}} = \alpha\frac{x_{i}^Tw_{j}}{||x_{i}|| \cdot ||w_{j}||}
logit{i,j}=α∣∣xi∣∣⋅∣∣wj∣∣xiTwj
α
\alpha
α是增大梯度的尺度元素,实验设置为20,
x
i
x_{i}
xi是第 i 个实例的ROI特征,
w
j
w_{j}
wj是第 j 个类别的权重。
在余弦相似投影的超空间内,对比特征向量使用聚类的方法使得簇内距离更小,簇间距离更大。

3.3、对比建议编码的损失
对于每一个mini-batch,有N个ROI特征框,
{
z
i
,
u
i
,
y
i
}
i
=
1
N
\{z_{i},u_{i},y_{i}\}_{i=1}^N
{zi,ui,yi}i=1N,
z
i
z_{i}
zi表示ROI head对第
i
i
i个区域建议框所编码成的128维向量;
u
i
u_{i}
ui表示建议框和真实框的IOU值;
y
i
y_{i}
yi表示真实框的标签。
则设计对比建议编码的损失为:
L
C
P
E
=
1
N
∑
i
=
1
N
f
(
u
i
)
⋅
L
z
i
L_{CPE} = \frac{1}{N}\sum_{i=1}^{N}{f(u_i)}\cdot L_{z_{i}}
LCPE=N1i=1∑Nf(ui)⋅Lzi
L
z
i
=
−
1
N
y
i
−
1
∑
j
=
1
,
j
≠
i
N
∣
∣
{
y
i
=
y
j
}
⋅
l
o
g
e
x
p
(
z
i
~
⋅
z
j
~
/
τ
)
∑
k
=
1
N
∣
∣
k
≠
i
⋅
e
x
p
(
z
i
~
⋅
z
k
~
/
τ
)
L_{z_{i}} = \frac{-1}{N_{y_{i}}-1}\sum_{j=1,j\ne i}^{N}{||\{ y_{i}=y_{j}\}\cdot log \frac{exp(\widetilde{z_{i}} \cdot \widetilde{z_{j}}/\tau)}{\sum_{k=1}^{N}{||_{k\ne i}\cdot exp(\widetilde{z_{i}} \cdot \widetilde{z_{k}}/\tau)}}}
Lzi=Nyi−1−1j=1,j=i∑N∣∣{yi=yj}⋅log∑k=1N∣∣k=i⋅exp(zi
⋅zk
/τ)exp(zi
⋅zj
/τ)
f
(
u
i
)
=
∣
∣
{
u
i
≥
ϕ
}
⋅
g
(
u
i
)
{f(u_i)}=||\{u_{i}\geq \phi\}\cdot g(u_{i})
f(ui)=∣∣{ui≥ϕ}⋅g(ui)
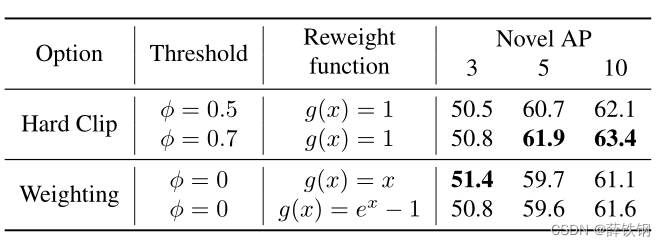
在上面的公式中,使用 f ( u i ) {f(u_i)} f(ui)来减少偏离目标过多的建议框的数目,防止 IoU 得分过低使得proposal 中包含干扰的背景信息。(图像分类的所有语义信息来自于整张图片。而在目标检测问题中,用于分类的语义信息来自于RPN得到的region proposals,有些IOU较低的proposal可能含有较多的非目标信息。)
其中,
z
j
~
=
z
i
∣
∣
z
i
∣
∣
\widetilde{z_{j}}=\frac{z_{i}}{||z_{i}||}
zj
=∣∣zi∣∣zi,表示归一化特征;
z
i
~
⋅
z
j
~
\widetilde{z_{i}} \cdot \widetilde{z_{j}}
zi
⋅zj
表示第
i
i
i个和第
j
j
j个建议框之间的余弦相似度;
N
y
i
N_{y_{i}}
Nyi是具有相同标签
y
i
y_{i}
yi的建议框的数量;
τ
\tau
τ是超参数;
ϕ
\phi
ϕ为IOU阈值,取值为0.7;
g
(
u
i
)
g(u_{i})
g(ui)为权重分配函数,为不同的IOU赋予不同的权重。
最终的损失函数为:
L = L r p n + L c l s + L r e g + λ L C P E \mathbb{L}=L_{rpn}+L_{cls}+L_{reg}+\lambda L_{CPE} L=Lrpn+Lcls+Lreg+λLCPE
其中,
L
r
p
n
L_{rpn}
Lrpn是二元交叉熵损失,用于从众多anchor中得到前景proposals、
L
c
l
s
L_{cls}
Lcls是交叉熵损失,用于proposals分类,
L
r
e
g
L_{reg}
Lreg是smoothed-L1损失,用于box回归。
当在微调阶段传输到新数据时,我们发现对比损耗可以以多任务方式添加到主要Faster RCNN损耗中,而不会破坏训练,
λ
\lambda
λ设置为0.5,以平衡损失规模。
训练过程:
1、首先,使用丰富的基类数据(Dtrain=Dbase)训练Faster R-CNN检测模型。
2、然后,将训练好的模型迁移到小数据集上。小数据集是由新类和随机抽样的基类组成的混合数据集( D t r a i n = D n o v e l ∪ D b a s e Dtrain=Dnovel\cup Dbase Dtrain=Dnovel∪Dbase)。在微调过程中,主干特征提取网络被冻结,联合优化回归损失、分类损失和CPE损失。
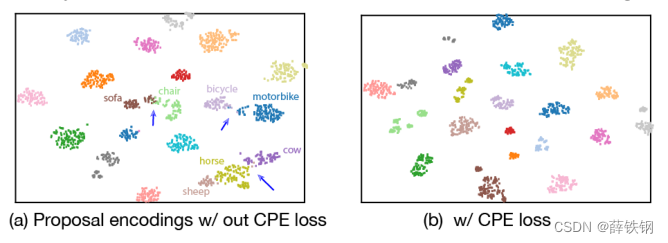
其实就是加了一个同类相吸,异类相斥的模块,使用聚类的方法来增大类间差异。
4、实验
实验参数设置
| 项目 | Value |
|---|---|
| 基线方法 | Faster R-CNN |
| 特征提取器 | ResNet-101+FPN |
| batch-size | 16 |
| 训练方法 | SGD优化器 |
| 动量 | 0.9 |
| 权重衰减 | 0.0001 |
| GPU数量 | 8 |
验证实验
PASCAL VOC PASCAL VOC中的20个类别分为15个基类和5个新类。所有来自PASCAL VOC 07+12 trainval集合的基类数据都被认为是可用的,新实例的K-shot是从新类中随机抽取的,K=1、2、3、5和10。
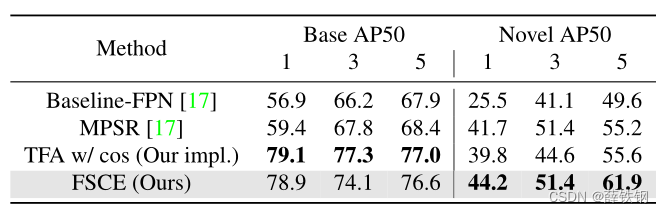
MS COCO 对于COCO中的80个类别,与PASCAL VOC相同的20个类别保留为新类,其余60个类别用作基类。在COCO 2014 val数据集的5K图像上评估了K=10和30个shot的检测性能,并获取了新类的COCOstyle AP和AP75。
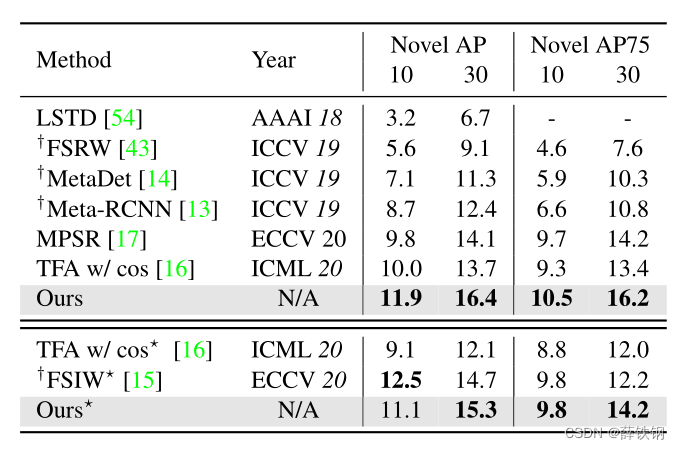
消融实验
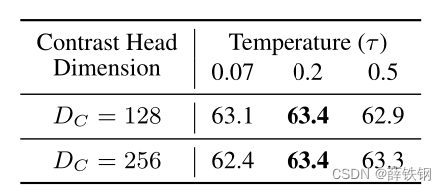
为了确定每个模块的最优参数值进行的消融实验:
1、对比分支的参数消融
2、对比编码损失的参数消融
new-baseline
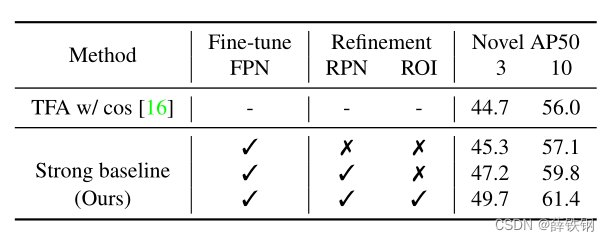
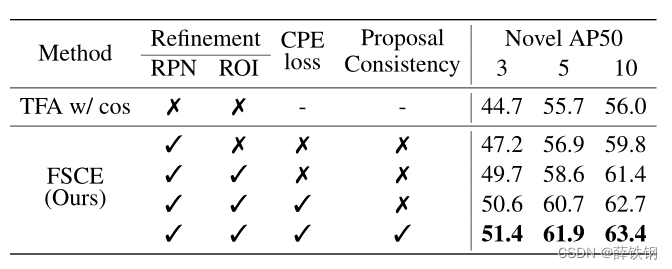
FSCE各个组成模块的消融
5、结论
引入对比学习的思想
对实例进行建模而不是对类别进行建模
对比分支可以作为二阶段网络的一个即插即用模块