文章目录
- 一.需求分析
- 二.需求解决
- 2.1 本次实验以california_housing加州房价数据集为例,下载数据集
- 2.2 查看数据集的描述、特征及目标数据名称、数据条数、特征数量
- 2.3 将数据读入pandas的DataFrame并转存到csv文件
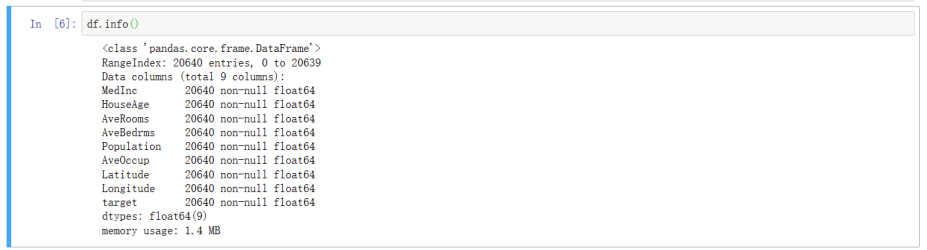
- 2.4 查看数据集各个特征的类型以及是否有空值
- 2.5 对数据集做中心化度量:计算各个特征的中位数和均值,分析中位数和均值情况
- 2.6 对数据集做离散化度量:对第一个特征(收入中位数)画盒图(箱线图),检查孤立点(离群点)并进行分析
- 2.7 【选做】对所有特征画盒图(箱线图),检查孤立点(离群点)并进行分析
一.需求分析
本文主题:基于Pandas的数据预处理技术
本次任务共分为16个任务,将其分为前七个任务和后11个任务,本文探讨其前七个任务。
本文的源代码下载链接:
基于Pandas的数据预处理技术-源代码-机器学习文档类资源-CSDN文库
https://download.csdn.net/download/weixin_52908342/87337635
本次实验内容:
-
本次实验以california_housing加州房价数据集为例,下载数据集
-
查看数据集的描述、特征及目标数据名称、数据条数、特征数量
-
将数据读入pandas的DataFrame并转存到csv文件
-
查看数据集各个特征的类型以及是否有空值
-
对数据集做中心化度量:计算各个特征的中位数和均值,分析中位数和均值情况
-
对数据集做离散化度量:对第一个特征(收入中位数)画盒图(箱线图),检查孤立点(离群点)并进行分析
-
【选做】对所有特征画盒图(箱线图),检查孤立点(离群点)并进行分析
-
对第一个特征(收入中位数)排序后画散点图
-
对第一个特征(收入中位数)画分位数图并分析
-
【选做】对所有特征画分位数图并进行分析
-
使用散点图、使用线性回归方法拟合第一个特征(收入中位数)并分析
-
【选做】使用局部回归(Loess)曲线(用一条曲线拟合散点图)方法拟合第一个特征(收入中位数)数据
-
对第一个特征(收入中位数)画分位数-分位数图并分析
-
对第一个特征(收入中位数)画直方图,查看数据的分布和数据倾斜情况
-
【选做】对所有特征画直方图,查看数据的分布和数据倾斜情况
-
寻找所有特征之间的相关性并找出相关性大于 0.7 的特征对,做特征规约
二.需求解决
2.1 本次实验以california_housing加州房价数据集为例,下载数据集
本次实验以california_housing加州房价数据集为例,下载数据集,先将数据集保存下来,输出查看一下。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
housing=fetch_california_housing()
print(housing.keys())
以california_housing加州房价数据集为例,下载数据集,先将数据集保存下来,输出查看一下。运行结果如下:

2.2 查看数据集的描述、特征及目标数据名称、数据条数、特征数量
在做完上面的下载数据集操作之后将其保存下来,查看数据集的描述、特征及目标数据名称、数据条数、特征数量。输出一下查看效果:
print(housing['DESCR'])
print(housing['feature_names'])
print(housing['target_names'])
X=housing.data
y=housing.target
print('y:',y.shape,y)
print('X:',X.shape,X)
查看数据集的描述、特征及目标数据名称、数据条数、特征数量。效果如下:

2.3 将数据读入pandas的DataFrame并转存到csv文件
我们做完上述步骤数据集的描述、特征及目标数据名称、数据条数、特征数量,将数据读入pandas的DataFrame并转存到csv文件,代码如下:
import pandas as pd
df=pd.DataFrame()
for i in range (X.shape[1]):
df[housing.feature_names[i]]=X[:,i]
df["target"]=y
df.to_csv('cali-housing.csv',index=None
将数据读入pandas的DataFrame并转存到csv文件截图如下:

2.4 查看数据集各个特征的类型以及是否有空值
函数df.info ()作用:数据表的基本信息(维度,列名称,数据格式,所占空间等)。
Pandas dataframe.info()函数的作用是获取一个简洁的dataframe摘要。当对数据进行探索性分析时,它非常方便。为了快速浏览数据集,我们使用dataframe.info()函数。
这个任务需求比较简单哈: 查看数据集各个特征的类型以及是否有空值,只需要一行函数:
df.info()
参数:
verbose:是否打印完整的摘要信息。None遵循display.max_info_columns设置。True或False覆盖显示.max_info_columns设置。
Buf:可写缓冲区,默认为sys.stdout
max_cols:确定打印完整摘要还是简短摘要。None遵循display.max_info_columns设置。
memory_usage:指定是否显示DataFrame元素(包括索引)的总内存使用量。None遵循display.memory_usage设置。True或False覆盖显示.memory_usage设置。’ deep ‘的值相当于True,具有深度内省功能。内存使用以人类可读的单位(base-2表示)表示。
null_counts:是否显示非空计数。如果None,则仅显示帧是否小于max_info_rows和max_info_columns。如果为True,则总是显示计数。如果是False,永远不要显示计数。
查看数据集各个特征的类型以及是否有空值,截图如下:
2.5 对数据集做中心化度量:计算各个特征的中位数和均值,分析中位数和均值情况
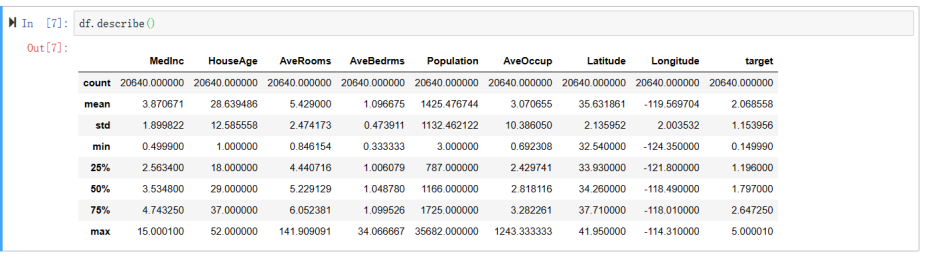
这个任务需求也是非常的简单,我们对数据集做中心化度量:计算各个特征的中位数和均值,分析中位数和均值情况,只需要调用describe函数:
df.describe()
describe函数:用于生成描述性统计数据,统计数据集的集中趋势,分散和行列的分布情况,不包括 NaN值。
参数:
percentiles:赋值类似列表形式,可选
表示百分位数,介于0和1之间。默认值为 [.25,.5,.75],分别返回第25,第50和第75百分位数。 可自定义其它值,用法为df.describe(percentiles=[.xx])。
include:‘all’,类似于dtypes列表或None(默认值),可选
要包含在结果中的数据类型的白名单。对于Series不可用。以下是选项:
‘all’:输入的所有列都将包含在输出中。
类似于dtypes的列表:将结果限制为提供的数据类型。将结果限制为数字类型用法:numpy.number。要将其限制为对象列用法:numpy.object。字符串也可以以select_dtypes(例如df.describe(include=['O']))的方式使用。要选择分类类型,请使用'category'
无(默认):结果将包括所有数字列。
exclude:类似于dtypes列表或None(默认值),可选,
要从结果中除去的黑名单数据类型列表。Series不可用。以下是选项:
类似于dtypes的列表:从结果中排除提供的数据类型。排除数值类型用法:numpy.number。要排除对象列,使用numpy.object。字符串也可以以select_dtypes(例如df.describe(include=['O']))的方式使用。要排除分类类型,请使用'category'
无(默认):结果将不包含任何内容。
对数据集做中心化度量:计算各个特征的中位数和均值,分析中位数和均值情况,运行结果截图:
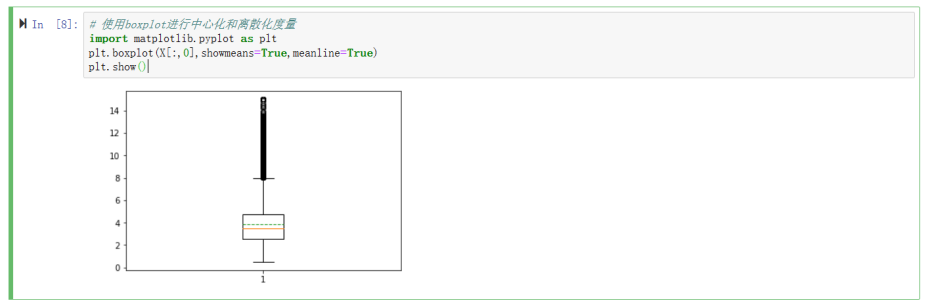
2.6 对数据集做离散化度量:对第一个特征(收入中位数)画盒图(箱线图),检查孤立点(离群点)并进行分析
对数据集做离散化度量:对第一个特征(收入中位数)画盒图(箱线图),检查孤立点(离群点)并进行分析。
考虑使用boxplot进行中心化和离散化度量,代码如下:
import matplotlib.pyplot as plt
plt.boxplot(X[:,0],showmeans=True,meanline=True)
plt.show()
运行结果如下:
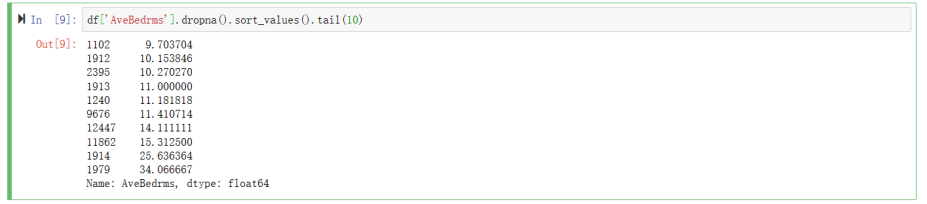
df['AveBedrms'].dropna().sort_values().tail(10)
运行结果如下:
2.7 【选做】对所有特征画盒图(箱线图),检查孤立点(离群点)并进行分析
我们挑战一下这个简单的选做需求:【选做】对所有特征画盒图(箱线图),检查孤立点(离群点)并进行分析
人均收入(MedInc)、房龄(HouseAge)、房间数(AveRooms)、卧室数(AveBedrooms)、小区人口数(Population)、
房屋居住人数(AveOccup)、小区经度(Longitude)、小区纬度(Latitude)
使用boxplot进行中心化和离散化度量:
import matplotlib.pyplot as plt
plt.figure(figsize=(12,12))
for i in range(8):
plt.subplot(4, 2, i+1)
plt.boxplot(X[:,i],showmeans=True,meanline=True)
plt.show()
运行效果截图:
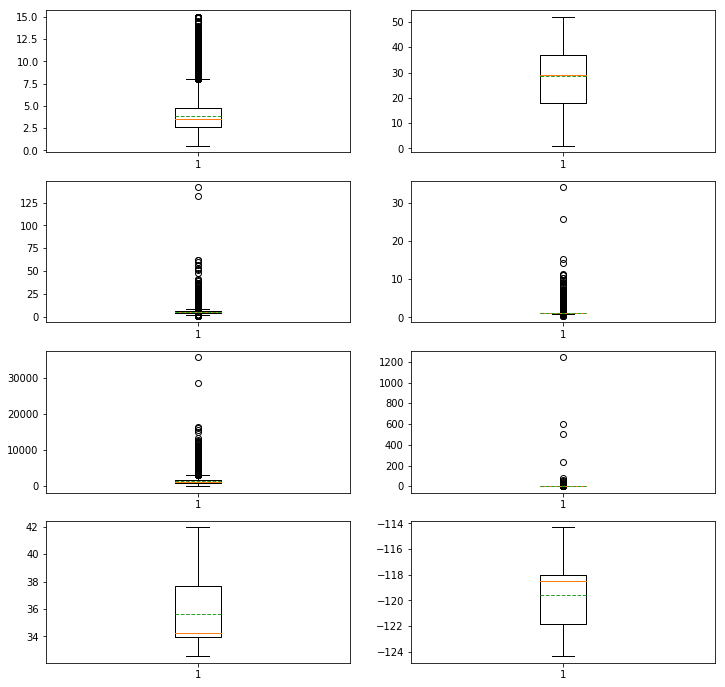
从上面的8个特征值的盒图观察可以看到人均收入(MedInc)、房龄(HouseAge)、房间数(AveRooms)、卧室数(AveBedrooms)、小区人口数(Population)、房屋居住人数(AveOccup)、小区经度(Longitude)、小区纬度(Latitude),这些特征在加州房价数据的盒图。