shuffle操作说白了就是重分区操作
在Apache Spark中,任务之间的依赖关系主要分为两类:宽依赖(Wide Dependency)和窄依赖(Narrow Dependency)。这两者之间的主要区别在于它们对任务之间数据的依赖性以及执行方式的不同。
窄依赖意味着任务可以在内存中的管道上迭代并行运行,而不需要等待前一阶段的运行结果。相比之下,宽依赖涉及到shuffle操作,需要等待上一阶段的运行结果才能继续执行程序。
理解和掌握宽窄依赖对于优化Spark作业的性能至关重要。在设计Spark作业时,尽量使用窄依赖,以减少Shuffle的开销。通过合理的分区策略和选择适当的转换操作,可以有效地减少宽依赖的出现。
那么现在让我们来介绍一下spark中那些会导致shuffle的算子:
🧨
1、repartition类的操作:比如repartition、repartitionAndSortWithinPartitions、coalesce等重分区: 一般会shuffle,因为需要在整个集群中,对之前所有的分区的数据进行随机,均匀的打乱,然后把数据放入下游新的指定数量的分区内
2、byKey类的操作:比如reduceByKey、groupByKey、sortByKey等
byKey类的操作:因为你要对一个key,进行聚合操作,那么肯定要保证集群中,所有节点上的,相同的key,一定是到同一个节点上进行处理
3、join类的操作:比如join、cogroup等join类的操作:两个rdd进行join,就必须将相同join key的数据,shuffle到同一个节点上,然后进行相同key的两个rdd数据的笛卡尔乘积
理解了上述内容,现在让我们来上机实践一下:
这里我们使用 toDebugString() 这个方法 返回该RDD及其用于调试的递归依赖项的描述。

代码如下 这里我们先用repartition算子举例:
from pyspark import SparkContext
# repartition 算子
data = [2, 3, 1, 4, 5, 6, 7, 8, 9, 10]
rdd = sc.parallelize(data, 3)
repartitioned_rdd = rdd.repartition(5)
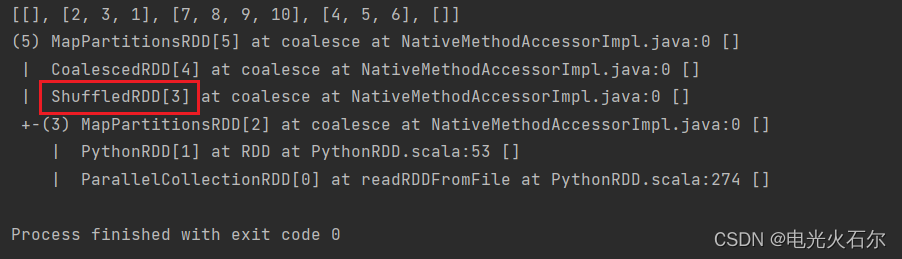
print(repartitioned_rdd.glom().collect())
print(repartitioned_rdd.toDebugString().decode())
我们来看看运行结果:
可以发现这段程序经历了shuffle
现在让我们将上述算子都运行一下,看看是否都经历了shuffle
代码如下,各位读者可自行实验:
from pyspark import SparkContext
sc = SparkContext("local", "apple1")
# 那些会导致shuffle的算子
# =======================================================================================
# 1、分区类算子
# TODO
# repartition 算子
data = [2, 3, 1, 4, 5, 6, 7, 8, 9, 10]
rdd = sc.parallelize(data, 3)
repartitioned_rdd = rdd.repartition(5)
print(repartitioned_rdd.glom().collect())
print(repartitioned_rdd.toDebugString().decode())
# TODO
# repartitionAndSortWithinPartitions 它会在每个分区内对数据进行排序 分区先排序 提高性能嘛
# data = [(1, "apple"), (6, "banana"), (3, "banana"), (2, "orange"), (4, "grape")]
# rdd = sc.parallelize(data, 2) # 创建一个有2个分区的键值对RDD
#
# repartitioned_sorted_rdd = rdd.repartitionAndSortWithinPartitions(numPartitions=2)
# # print(repartitioned_sorted_rdd.glom().collect())
# print(repartitioned_sorted_rdd.toDebugString().decode())
# TODO
# coalesce 减少分区 可以设置是否进行shuffle
# data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# rdd = sc.parallelize(data, 5) # 创建一个有5个分区的RDD
#
# coalesced_rdd = rdd.coalesce(2, shuffle=True) # 将RDD合并到2个分区
# # print(coalesced_rdd.glom().collect())
# print(coalesced_rdd.toDebugString().decode())
# =======================================================================================
# TODO
# reduceByKey
# data = ["apple", "banana", "orange", "banana", "grape", "apple", "orange"]
# rdd = sc.parallelize(data)
# rdd = rdd.map(lambda x: (x, 1))
# rdd2 = rdd.reduceByKey(lambda x, y: x+y)
# # print(rdd2.collect())
# print(rdd2.toDebugString().decode() + '\n')
# TODO
# groupByKey
# rdd3 = rdd.groupByKey()
# print(rdd3.toDebugString().decode() + '\n')
# TODO
# sortByKey 当分区大于1时才有shuffle 因为sortbykey涉及重分区 按照key分组 然后排序
# 如果 RDD 使用了默认的分区器(即 HashPartitioner),并且你要求对 key 进行排序,那么就会发生 shuffle。
# 这是因为默认情况下,HashPartitioner 使用 key 的 hash 值来确定数据所在的分区,
# 这可能导致相同 key 的数据散布在不同的分区中,而进行排序时需要将相同 key 的数据聚合在一起。
# rdd = sc.parallelize(data, 2)
#
# rdd = rdd.map(lambda x: (x, 1))
# print(rdd.glom().collect())
#
# rdd4 = rdd.sortByKey()
# print(rdd4.glom().collect())
# print(rdd4.toDebugString().decode() + '\n')
# =======================================================================================
# TODO
# join 操作
# rdd1 = sc.parallelize([(1, "apple"), (2, "banana"), (3, "orange")])
# rdd2 = sc.parallelize([(1, 5), (2, 3), (3, 8), (1, 6)])
#
# joined_rdd = rdd1.join(rdd2)
# # print(joined_rdd.collect())
# print(joined_rdd.toDebugString().decode() + '\n')
# TODO
# cogroup
# rdd1 = sc.parallelize([(1, "apple"), (2, "banana"), (3, "orange")])
# rdd2 = sc.parallelize([(1, 5), (2, 3), (3, 8), (1, 9)])
#
# cogrouped_rdd = rdd1.cogroup(rdd2)
# result = cogrouped_rdd.collect()
# # map 函数: map 是 Python 内置函数,用于对一个可迭代对象的每个元素应用一个指定的函数。在这里,map 的目标是 list 函数。
# # list 函数: list 是 Python 内置函数,用于将一个可迭代对象转换为列表。
# for k, v in result:
# print(k, tuple(map(list, v)))
# print(cogrouped_rdd.toDebugString().decode() + '\n')