#012 TensorFlow 2.0 中的 TF 迁移学习

一、说明
在这篇文章中,我们将展示如何在不从头开始构建计算机视觉模型的情况下构建它。迁移学习背后的想法是,在大型数据集上训练的神经网络可以将其知识应用于以前从未见过的数据集。也就是说,为什么它被称为迁移学习;我们将现有模型的学习转移到新的数据集中。
教程概述:
- 介绍
- 使用内置的 TensorFlow 模型进行迁移学习
- 使用 TensorFlow Hub 进行迁移学习
二、为什么迁移学习简介
之 我们已经探讨了如何使用数据增强来提高模型性能。现在的问题是,“如果我们没有足够的数据来从头开始训练我们的网络怎么办?
对 此的解决方案是使用迁移学习方法。一篇更具理论意义的帖子已经发布在我们的博客上。如果需要,请查看它以刷新一些想法。我们可以使用迁移学习将知识从一些预先训练好的开源网络转移到我们自己的简历问题中。
计 算机视觉研究社区在互联网上发布了许多数据集,如Imagenet或MS Coco或Pascal数据集。许多计算机视觉研究人员已经在这些数据集上训练了他们的算法。有时,此培训需要数周时间,并且可能需要许多 GPU。事实上,其他人已经完成了这项任务并经历了痛苦的高性能研究过程,这意味着我们经常可以下载开源权重。
有 很多网络已经过训练。例如,Imagenet 数据集,它由 1000 个不同的类和超过 14 万张图像组成。因此,网络可能有一个 softmax 单元,它输出一千个可能的类之一。我们可以做的是摆脱softmax层并创建我们自己的输出单元来表示例如猫或狗。
由于我们使用下载的权重,我们将只训练与我们的输出层关联的参数,在我们的例子中,这将是一个 sigmoid 输出层。
三、使用内置的 TensorFlow 模型进行迁移学习
让我们首先为训练准备数据集。我们将使用 wget.download 命令下载数据集。之后,我们需要解压缩它并合并训练和测试部分的路径。
import os
import wget
import zipfile
wget.download("https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip")
with zipfile.ZipFile("cats_and_dogs_filtered.zip","r") as zip_ref:
zip_ref.extractall()
base_dir = 'cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
现在,让我们导入所有必需的库并构建模型。我们将使用一个名为MobileNetV2的预训练网络,该网络在ImageNet数据集上进行训练。在这里,我们希望使用除顶部分类图层之外的所有图层,因此我们不会将它们包含在我们的网络中。
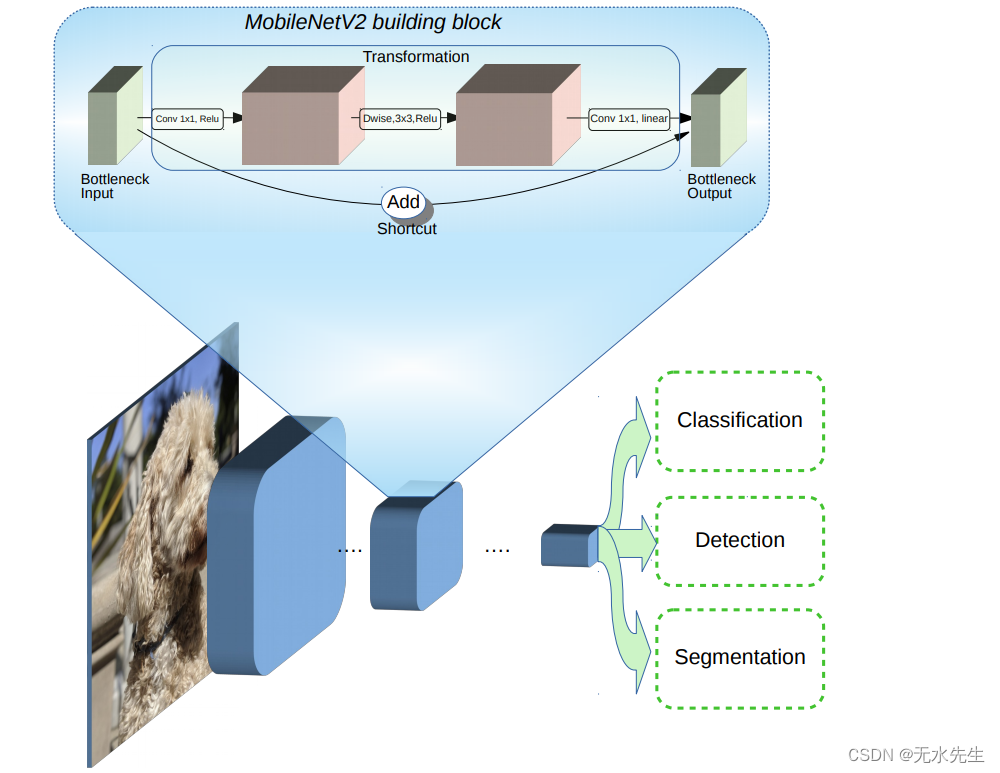
obileNetV2 体系结构概述:https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html
这 个模型和其他预训练模型已经在TensorFlow中可用。
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from tensorflow.keras import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_model = MobileNetV2(input_shape=(224, 224, 3),
include_top=False,
weights='imagenet')
base_model.summary()
如
输出:
Model: "mobilenetv2_1.00_224"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 224, 224, 3) 0
__________________________________________________________________________________________________
Conv1_pad (ZeroPadding2D) (None, 225, 225, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
Conv1 (Conv2D) (None, 112, 112, 32) 864 Conv1_pad[0][0]
__________________________________________________________________________________________________
bn_Conv1 (BatchNormalization) (None, 112, 112, 32) 128 Conv1[0][0]
__________________________________________________________________________________________________
Conv1_relu (ReLU) (None, 112, 112, 32) 0 bn_Conv1[0][0]
__________________________________________________________________________________________________
expanded_conv_depthwise (Depthw (None, 112, 112, 32) 288 Conv1_relu[0][0] 果最后一层输出不同数量的类,那么我们需要有自己的输出单元来输出以下类:猫或狗。有几种方法可以做到这一点:
- 取最后几层的权重,将它们用作初始化并进行梯度下降。这样,我们将重新训练网络的一部分。
- 删除最后几层的权重,使用我们自己的新隐藏单元和我们自己的最终 sigmoid(或 softmax)输出。通过这种方式,我们可以更改输出的数量。
因此,这两种方法中的任何一种都值得尝试。
现在让我们冻结预训练层并添加一个新层,称为 GlobalAveragePooling2D,之后是具有 sigmoid 激活函数的 Dense 层。
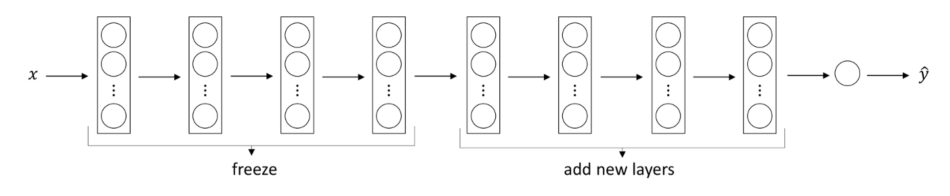
现
base_model.trainable = False
model = Sequential([base_model,
GlobalAveragePooling2D(),
Dense(1, activation='sigmoid')])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
mobilenetv2_1.00_224 (Model) (None, 7, 7, 1280) 2257984
_________________________________________________________________
global_average_pooling2d (Gl (None, 1280) 0
_________________________________________________________________
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________现在是训练步骤的时候了。我们将使用图像数据生成器来迭代图像。现在没有必要为大量时期训练网络,因为我们已经预先训练了一部分网络。
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(224, 224),
batch_size=32,
class_mode='binary')
validation_generator = val_datagen.flow_from_directory(
validation_dir,
target_size=(224, 224),
batch_size=32,
class_mode='binary')
history = model.fit(
train_generator,
epochs=6,
validation_data=validation_generator,
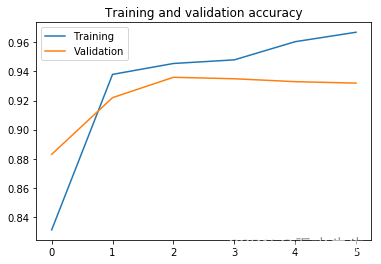
verbose=2)让 我们看看结果。
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, label="Training")
plt.plot(epochs, val_accuracy, label="Validation")
plt.legend()
plt.title('Training and validation accuracy')
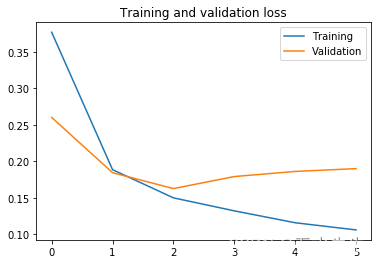
plt.figure()
plt.plot(epochs, loss, label="Training")
plt.plot(epochs, val_loss, label="Validation")
plt.legend()
plt.title('Training and validation loss')3.Text(0.5, 1.0, 'Training and validation loss')
四、 使用 TensorFlow Hub 进行迁移学习
访问预训练模型的另一种方法是TensorFlow Hub。TensorFlow Hub是一个库,用于发布,发现和使用机器学习模型的可重用部分。您可以在此处找到更多预训练模型。
我们将冻结图层并添加一个用于分类的新图层。全连接网络的输入称为瓶颈要素。它们表示网络中最后一个卷积层的激活图。
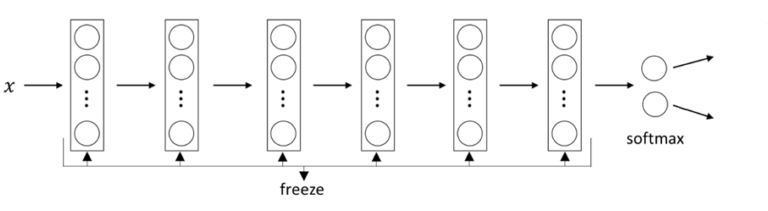
让
在这里,我们也可以使用 TensorBoard,但这次让我们保持简单。
最后,让我们可视化一些预测。在此数据集中,猫标记为 0,狗标记为 1。我们将用蓝色显示正确的预测,用红色显示假。

五、总结
正如我们在上面看到的,使用迁移学习可以帮助我们在短时间内取得非常好的结果。使用数据增强,可以进一步增强结果。
在下一篇文章中,我们将展示如何创建网络并将其转换以在移动设备上使用。