一、使用cookie
这段代码演示了如何使用Python的urllib和http.cookiejar模块来实现网站的模拟登录,并在登录后访问需要认证的页面。
# 导入必要的库
import requests
from urllib import request, parse
# 1. 导入http.cookiejar模块中的CookieJar类,用于存储和管理Cookie
from http.cookiejar import CookieJar
# 2. 导入HTTPCookieProcessor,用于处理HTTP请求中的Cookie
from urllib.request import HTTPCookieProcessor
# 设置请求头,模拟浏览器访问
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"
}
# 创建一个CookieJar对象来存储和管理Cookie
cookiejar = CookieJar()
# 创建一个HTTPCookieProcessor处理器,用于处理Cookie
handler = HTTPCookieProcessor(cookiejar)
# 使用处理器构建一个opener对象,这个opener会自动处理Cookie
opener = request.build_opener(handler)
# 准备登录表单数据
data = {
'__VIEWSTATE': 'pm4yVT0tOjA36YHPhIUtUmKXH1wGoOp7OTyI8HH+3PU0Z6E4bohm2CzOOCCQ9w2fxqb7oHLCxM4uHc+BiH5Ul4xTGRDehq9E/QXr22y4HX+qpA4v+j5qfIvc3PU=',
'__VIEWSTATEGENERATOR': 'B6E3F9D8',
'txtUser': '', # 用户名
'txtPass': '', # 密码
'btnLogin': '' # 登录按钮 使用自己的
}
# 登录页面的URL
loginurl = "http://210.44.176.97/datajudge/login.aspx"
# 创建登录请求对象
# 注意:这里将表单数据编码为URL格式,并转换为字节流
req = request.Request(
loginurl,
data=parse.urlencode(data).encode("utf-8"),
headers=header
)
# 发送登录请求,opener会自动保存服务器返回的Cookie
opener.open(req)
# 如果上面没有抛出异常,意味着登录成功
# 现在可以访问需要登录后才能查看的页面
url = " " #找到自己的
# 创建访问请求对象
reqm = request.Request(url, headers=header)
# 发送请求,opener会自动带上之前保存的Cookie
resp = opener.open(reqm)
# 打印返回的页面内容
print(resp.read().decode("utf-8"))-
Cookie处理机制:
-
使用
CookieJar类创建Cookie容器 -
通过
HTTPCookieProcessor创建处理器,自动处理HTTP请求中的Cookie -
构建
opener对象,后续所有请求都通过这个opener发送,会自动管理Cookie
-
-
模拟登录过程:
-
准备登录表单数据(包括隐藏字段如
__VIEWSTATE) -
发送POST请求到登录页面
-
服务器返回的Cookie会被自动保存在
CookieJar中
-
-
访问受保护页面:
-
使用同一个
opener发送请求 -
opener会自动带上之前保存的Cookie,证明用户已登录
-
成功获取需要认证才能访问的页面内容
-
这种技术常用于:
-
爬取需要登录的网站数据
-
自动化测试需要认证的Web应用
-
模拟用户行为进行网站监控
注意:在实际应用中,应该遵守网站的robots.txt协议和使用条款,不要滥用这种技术。
运行结果:

二、使用session
# 导入requests库,用于发送HTTP请求
import requests
# 设置请求头,模拟浏览器访问
# 注意:这里的User-Agent伪装成Chrome浏览器
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"
}
# 准备登录表单数据
# 注意:ASP.NET网站通常会有__VIEWSTATE和__VIEWSTATEGENERATOR等隐藏字段
data = {
'__VIEWSTATE': 'pm4yVT0tOjA36YHPhIUtUmKXH1wGoOp7OTyI8HH+3PU0Z6E4bohm2CzOOCCQ9w2fxqb7oHLCxM4uHc+BiH5Ul4xTGRDehq9E/QXr22y4HX+qpA4v+j5qfIvc3PU=',
'__VIEWSTATEGENERATOR': 'B6E3F9D8',
'txtUser': '', # 用户名输入框
'txtPass': '', # 密码输入框
'btnLogin': '' # 登录按钮 自己的
}
# 创建一个会话对象
# 会话对象会自动保持Cookie,用于维持登录状态
session = requests.session()
# 登录页面的URL
loginurl = "" #自己寻找
# 发送POST请求进行登录
# 使用data参数发送表单数据,headers参数设置请求头
# 登录成功后,服务器返回的Cookie会自动保存在session中
session.post(loginurl, data=data, headers=header)
# 如果上面没有抛出异常,意味着登录成功
# 现在可以访问需要登录后才能查看的页面
url = ""
# 使用同一个session发送GET请求
# session会自动带上之前登录时获得的Cookie
resp = session.get(url, headers=header)
# 打印返回的页面内容
# resp.text会自动解码响应内容
print(resp.text)-
请求头设置:
-
设置User-Agent模拟Chrome浏览器访问,避免被服务器识别为爬虫
-
-
表单数据准备:
-
__VIEWSTATE和__VIEWSTATEGENERATOR是ASP.NET特有的隐藏字段,用于表单状态管理 -
txtUser和txtPass分别对应登录表单的用户名和密码输入框 -
btnLogin是登录按钮的name属性
-
-
会话管理:
-
requests.session()创建一个会话对象,该对象会自动处理Cookie -
所有通过这个session对象发送的请求都会自动携带相同的Cookie
-
-
登录过程:
-
session.post()发送POST请求到登录页面 -
服务器验证成功后返回的Set-Cookie头会被自动保存
-
-
访问受保护页面:
-
使用同一个session对象发送GET请求
-
自动携带登录Cookie,证明用户已认证
-
获取需要登录才能访问的页面内容
-
-
会话保持:
-
requests.session()创建的会话对象会自动管理Cookie -
相比手动处理Cookie更加方便可靠
-
-
ASP.NET特性:
-
ASP.NET网站通常需要提交
__VIEWSTATE等隐藏字段 -
这些字段的值可以从网页源码或第一次GET请求的响应中获取
-
-
安全性注意事项:
-
代码中包含明文密码,实际应用中应该避免
-
可以考虑从配置文件或环境变量读取敏感信息
-
-
异常处理:
-
实际应用中应该添加try-except块处理网络异常
-
可以检查resp.status_code确认请求是否成功
-
典型应用场景
这种代码通常用于:
-
爬取需要登录的网站数据
-
自动化测试Web应用
-
监控需要认证的网页内容变化
-
自动化操作Web系统
注意:使用时应遵守目标网站的服务条款和robots.txt规定。
运行结果:

三、使用selenium
# 导入所需模块
import time # 用于添加等待时间
from selenium import webdriver # 主模块,用于浏览器自动化
from selenium.webdriver.chrome.service import Service as ChromeService # Chrome服务
from selenium.webdriver.common.by import By # 定位元素的方式
# 设置ChromeDriver路径
driver_path = r"E:\chromedriver\chromedriver.exe" # ChromeDriver可执行文件路径
# 创建Chrome服务实例
service = ChromeService(executable_path=driver_path)
# 初始化Chrome浏览器驱动
driver = webdriver.Chrome(service=service)
# 目标登录页面URL
loginurl = ""
# 打开登录页面
driver.get(loginurl)
# 使用XPath定位用户名输入框并输入用户名
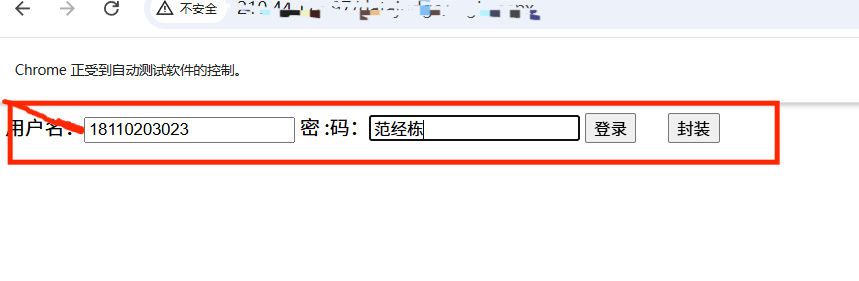
driver.find_element(By.XPATH, "//input[@id='txtUser']").send_keys("18110203023")
# 使用XPath定位密码输入框并输入密码
driver.find_element(By.XPATH, "//input[@id='txtPass']").send_keys("范经栋")
# 等待3秒,确保页面加载完成(实际应用中建议使用显式等待)
time.sleep(3)
# 使用XPath定位登录按钮并点击
driver.find_element(By.XPATH, "//input[@id='btnLogin']").click()
# 等待2秒,确保登录完成
time.sleep(2)
# 打印当前页面的源代码(登录后的页面)
print(driver.page_source)
# 注释掉的代码是之前使用requests库实现的版本,与当前selenium实现做对比
# session.post(loginurl,data=data,headers=header)
# # 意味着登录成功,session对象中已经存储了登录成功地数据
# url="http://210.44.176.97/datajudge/test.aspx"
#
# resp=session.get(url,headers=header)
# print(resp.text)-
初始化浏览器驱动:
-
通过
ChromeService指定ChromeDriver路径 -
创建
webdriver.Chrome实例来控制浏览器
-
-
页面导航:
-
driver.get(loginurl)打开登录页面
-
-
元素定位与操作:
-
使用XPath定位用户名输入框(
id='txtUser')并输入用户名 -
使用XPath定位密码输入框(
id='txtPass')并输入密码 -
使用XPath定位登录按钮(
id='btnLogin')并点击
-
-
等待机制:
-
time.sleep(3)在输入密码后等待3秒 -
time.sleep(2)在点击登录后等待2秒 -
(注:实际项目中建议使用selenium的显式等待
WebDriverWait)
-
-
结果获取:
-
driver.page_source获取当前页面的HTML源码
-
与requests实现的区别
-
模拟方式:
-
selenium实际控制浏览器操作,完全模拟用户行为
-
requests直接发送HTTP请求,更轻量但无法处理JavaScript
-
-
验证处理:
-
selenium能自动处理图片验证码等需要人工交互的情况
-
requests需要额外处理这类验证
-
-
性能:
-
selenium启动浏览器开销大,运行速度慢
-
requests更高效,适合大规模爬取
-
-
应用场景:
-
selenium适合需要完全模拟浏览器行为的复杂场景
-
requests适合简单的API调用或静态页面抓取
-
运行结果:




![[Windows] VutronMusic v1.6.0 音乐播放器纯净版,可登录同步](https://i-blog.csdnimg.cn/direct/793b84441fb04ecbb99bf79793baa199.png)




![STM32单片机入门学习——第3-4节: [2-1、2]软件安装和新建工程](https://i-blog.csdnimg.cn/direct/9ebb69abc1a741e6aa2a884c159e7f94.png)