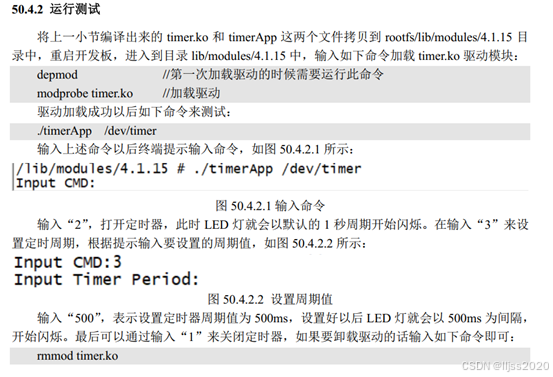
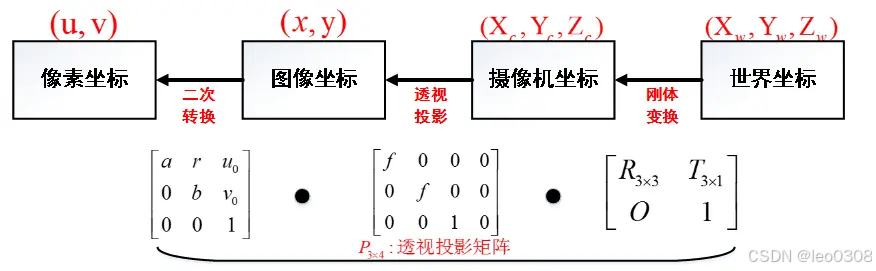
文章目录
- vector的模拟实现
- erase函数
- resize
- 拷贝构造
- 赋值重载
- 函数模版构造及其细节
- 结语
我们今天又见面啦,给生活加点impetus!!开启今天的编程之路
今天我们来完善vector剩余的内容,以及再探迭代器失效!
作者:٩( ‘ω’ )و260
我的专栏:C++初阶,数据结构初阶,题海探骊,c语言
欢迎点赞,关注!!

vector的模拟实现
erase函数
在这里我们会见识到第二种迭代器失效
先来讲解这种算法的思路:首先删除一个元素,我们就要让这个元素后面所有的元素向前一步,把这个元素给覆盖掉,注意特殊情况:头删和尾删。
我们直接来看代码实现:
void erase(iterator pos)
{
assert(pos>=_start&&pos<_finish);//因为_start这个位置可以取到,_finish这个位置娶不到,因为是左闭右开区间
iterator it=pos+1;
while(it<_finish)
{
*(it-1)=*it;//后面位置的元素赋值给前一个元素
it++;//迭代器向后遍历
}
_finish--;//之减了一个元素,所以_finish只用减一个就可以了
}
我们来测试一下:
void test_vector5()
{
Mrzeng::vector<int> v = { 1,2,2,2,3,4,5,6,7,9,8 };//删除为偶数的元素
for (auto& e : v)
{
cout << e << " ";
}
cout << endl;
Mrzeng::vector<int>::iterator it = v.begin()+5;
erase(it);
for(auto& e:v)
{
cout<<e<<" ";//输出1 2 2 2 2 5 6 7 8 9
}
此时我们能够得出正确的结果
我们再来把测试用例改的特殊些:
如果我们要把偶数全部给删除掉,那我们应该写一个循环,遍历到偶数的时候就删除:
来看代码:
Mrzeng::vector<int>::iterator it = v.begin();
while (it < v.end())
{
if (*it % 2 == 0)
{
v.erase(it);//erase迭代器的元素之后这个迭代器一定会失效,所以需要赋值重新修改迭代器
}
}//我们只是将上述代码中循环的这一个部分给修改了,其余部分还是没有修改
此时我们来运行一下代码:
我们发现产生了问题,程序异常退出了,那这个是什么原因呢?
这里就是我们所说的第二种迭代器失效,第一种我们所说的迭代器失效是因为扩容导致了空指针的问题,这里是因为erase的问题造成的
其实如果我们把这个代码放到g++编译器下,这个代码就是正确的,在msvc编译器中,每次erase迭代器位置的值之后编译器都会对这个迭代器进行强制检查,而g++不会对这个迭代器进行强制检查。同时,这个迭代器erase之后就会立即失效,那为啥msvc编译器下有这样的一种机制呢?而在g++编译器下没有这种机制?
假设没有这种机制,我们能够一直来访问这个迭代器,当我一直删除数据的时候,此时容量减少,有没有可能会造成缩容的情况,如果大幅缩容,此时又会开辟新的空间,此时迭代器失效又会回归到第一种类型,那么我不如直接就进行erase位置进行检查。
总结:erase函数中的迭代器使用后会立即失效,不能再利用这个迭代器去遍历我们的vector
那我们应该如何来解决呢?
既然erase迭代器使用后立即失效,那我们就直接重新给这个迭代器赋值。
此时我们将erase(it)这句代码改为:
it=erase(it);//此时我们给it重新赋值
既然此时我们erase函数都有返回值,那我们也要修改erase的整体函数:
erase的最终代码为:
iterator erase(iterator pos)
{
assert(pos>=_start&&pos<_finish);
iterator it=pos+1;
while(it<_finish)
{
*(it-1)=*it;
it++;
}
_finish--;
return pos;
}
为什么我要返回pos呢?因为vector规定,erase之后要返回删除位置的下一个元素,此时我们将pos位置的元素删除,后面的元素是不是走到前面来了,占了pos位置的元素,所以我们这里要返回pos位置的元素
总结:
1: vs下认为erase后it失效,失效迭代器进行强制检查,访问既会报错。
2::g++编译器不会对erase位置的迭代器进行强制检查
3:迭代器必须要重新赋值之后才能够继续使用
其实我们还可以来扩展一个知识点:
利用erase来进行缩容其实是以时间换空间的做法,其实这样不是很适合,因为我们现在电脑的空间都是比较富裕,没有必要为了一点空间而消耗大量时间,而一般的算法其实都是以空间换时间
resize
接下来我们来实现resize,本质上有三种方法:假设我们resize传递过来的参数是n。
如果n>size()&&n<capacity(),只是插数据,如果n>capacity(),扩空间的同时再来插数据。如果n<size(),就会造成缩容。
其实最后我们可以把这个分解成两个情况,插数据和不插数据:
我们直接来看代码实现:
void resize(size_t n,cosnt T& val=T())//使用了隐式类型转换,上一篇文章我们已经讲过了
{
assert(n>=0);
if(n>size())//扩容
{
reverse(n);
while(_finish!=_end_of_storage)//循环插入数据
{
push_back(val);
}
}else{//缩容
_finish=_start+n;//修改_finish就可以了
}
}
拷贝构造
我们先要创建空间,将实参的内容拷贝给这个空间。
例如:
vector(const vector<T>& v)
{
reverse(v.capacity);
for(auto& e:v)
{
push_back(e);
}
}
由于这里涉及到了reverse,我么这里再来补充一个点,我们以一个例子来开头:
void test_vector9()
{
Mrzeng::vector<string> v;
v.push_back("111111111111111111");
v.push_back("111111111111111111");
v.push_back("111111111111111111");
v.push_back("111111111111111111");
v.push_back("111111111111111111");
for (auto& e : v)
{
cout << e << " ";
}
}
来看这一个代码,我们来运行看一下结果:

为什么这里会打印出这个?首先我先说明一下,有些时候我们打印出绒绒绒绒绒,烫烫烫等的原因:
在 C 和 C++ 里,若你声明了一个数组或者分配了一块内存,却没有对其进行初始化,那么这块内存区域就会保留原有的数据。在 Windows 系统下,当使用 Visual Studio 编译器进行调试时,未初始化的栈内存会被填充为 0xCC。而 0xCCCC 在 GBK 编码里代表汉字 “烫”。
我们再来看一下这里如果我们只是插入4个数据的结果:

敏锐的你一定会发现,肯定是这里的扩容步骤出了问题。
这里可以补充一个知识点:代码没有达到预期结果的时候,如果是编译和运行时的错误,此时排除错误的方法只能够利用排除法,先屏蔽掉一部分的代码,随后看整体代码是否报错。
这里我们直接来讲结论吧
首先,扩容肯定就会开空间,此时就一定会有新旧指针,而且,我们对旧空间就指针进行析构之后,我们发现旧空间影响了新空间,所以,这里应该不难想到,这里是新旧指针指向了同一块空间
来看下图解:

那为什么我们这里是指向了同一块空间呢?就是因为memcpy是浅拷贝。有资源的话进行浅拷贝会造成多个指针指向同一块空间。所以我们这里只能手动实现深拷贝,来看下列代码:
void reverse(size_t n)
{
if(n>capacity())
{
T* tmp=new T[n];
size_t old_size=_finish-_start;
if(_start)
{
//memcpy(tmp,_start,sizeof(T)*old_size);
for(size_t i=0;i<size();i++)
{
tmp[i]=_start[i];//一个元素一个元素来进行拷贝
}
delete _start;
}
_start=tmp;
_finish=_start+old_size;
_end_of_storage=_start+n;
}
}
总结:
1:扩容的时候最好还是不要用memcpy来进行数据拷贝,因为我无法确定vector存储的元素是不是包含有资源的,如果有资源的话,必须要实现深拷贝。
2:深拷贝:扩容可能存在,拷贝构造可能存在,因为默认生成的拷贝构造是浅拷贝。
3:tmp[i]=_start[i];代码解释:等价于string1=string2,是调用库中的拷贝构造来完成赋值操作的,因为赋值重载会调用拷贝构造
赋值重载
我们这里以前传统的写法其实就是将数据给他拷贝过去。但是我们这里使用一种比较常用的方法
来看一下代码:
void swap(vector<T> v)
{
std::swap(_start,v._start);
std::swap(_finish,v._finish);
std::swap(_finish,v._finish);
}
vector<T>& operator=(vector<T> v)//这里使用传值调用,这样就直接调用拷贝构造了
{
swap(v);//调用算法库中的swap函数,因为效率问题,我们最好就只用算法库中的swap函数来交换内置类型
return *this;
}
但是这样的话就有一个缺点,万一我们赋值左右操作数都是同一个数,就会造成返回错误,因为在重载函数之后,v会释放掉函数栈帧,析构的话也会造成this指针指向的内容受到影响,但是一般我们不会这样做
或者我们也可以将代码改为这样:
vector<T>& operator=(vector<T>& v)//这里使用传值调用,这样就直接调用拷贝构造了
{
if(this!=&v)
{
vector<T> tmp(v);//拷贝构造一份v
swap(v);//调用算法库中的swap函数,因为效率问题,我们最好就只用算法库中的swap函数来交换内置类型
}
return *this;
}
总结:语法规定,构造函数是一定会调用拷贝构造的。
函数模版构造及其细节
接下里我们来利用函数模版构造vector。
首先:为什么我们这里是需要模版来构造vector,是因为我们可能使用其他容器中的数据来初始化vector。
其次,函数想要传递模版参数,必须事先要有模版声明
我们来写一下这个部分的代码:
template<class InputIterator>
vector(InputIterator first,InputIterator last)
{
while(first!=last)
{
push_back(*first);
first++;
}
}
那么是不是我们这个代码就没有问题了呢?其实不是的,我们这个代码仍然有问题:
倘若我们给构造函数这样传递一个参数:
vector<int> v(10,1);//这里我们想使用10个1来初始化这个vector
我们此时的目标是想要调用这个构造函数:
vector(size_t n, const T& val = T())//这里使用了匿名对象
{
assert(n > 0);
//因为使用匿名对象一定会调用构造函数,但是在函数模版之后,内置类型也有构造函数,使用匿名对象时调用构造函数内置类型会被升级成自定义类型
reverse(n);//查看空间是否足够
for (size_t i = 0;i < n;i++)
{
push_back(val);
}
}
但是此时我们发现会出一个问题,来看:

我们来画图理解一下:

也许你这里会去钻空子,那我们这里将size_t改为int不就好了吗?
但是还有一个极端的情况,如果我们参数传递写为:
vector(10u,1);
字符后面带u的这种极端情况,此时这个会被编译器默认认为是unsigned类型的数据,此时又会调用到模版,又会产生同样的问题,那我们这个应该怎么办呢?
其实,为了防止这种情况的发生,我们就可以直接让着两种情况都给他加上去就好了。
来看这个部分的所有代码:
在这里插入代码片 vector(size_t n, const T& val = T())//这里使用了匿名对象
{
assert(n > 0);
//因为使用匿名对象一定会调用构造函数,但是在函数模版之后,内置类型也有构造函数,使用匿名对象时调用构造函数内置类型会被升级成自定义类型
reverse(n);//查看空间是否足够
for (size_t i = 0;i < n;i++)
{
push_back(val);
}
}
vector(int n, const T& val = T())//这里使用了匿名对象
{
reverse(n);
for (int i = 0;i < n;i++)
{
push_back(val);
}
}
//为什么要这个函数模版,因为防止和上面的使用冲突了
template<class InputIterator>//想要使用函数模版,必须先要对这个模版进行声明
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
first++;
}
}
总结:函数传参会调用类型更加匹配的一个,如果没有类型匹配的,可能会进行隐式类型转换,比如int转变为size_t。
结语
感谢大家阅读我的博客,不足之处欢迎留言指正!!
三更灯火五更鸡,正是男儿读书时,加油,少年!!



![[Windows] VutronMusic v1.6.0 音乐播放器纯净版,可登录同步](https://i-blog.csdnimg.cn/direct/793b84441fb04ecbb99bf79793baa199.png)




![STM32单片机入门学习——第3-4节: [2-1、2]软件安装和新建工程](https://i-blog.csdnimg.cn/direct/9ebb69abc1a741e6aa2a884c159e7f94.png)