想学习第一篇博客:
https://huggingface.co/blog/zh/rlhf
RLHF 技术分解
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,这里我们按三个步骤分解:
- 预训练一个语言模型 (LM) ;
- 聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
- 用强化学习 (RL) 方式微调 LM。
细化:
1. 没啥好说的
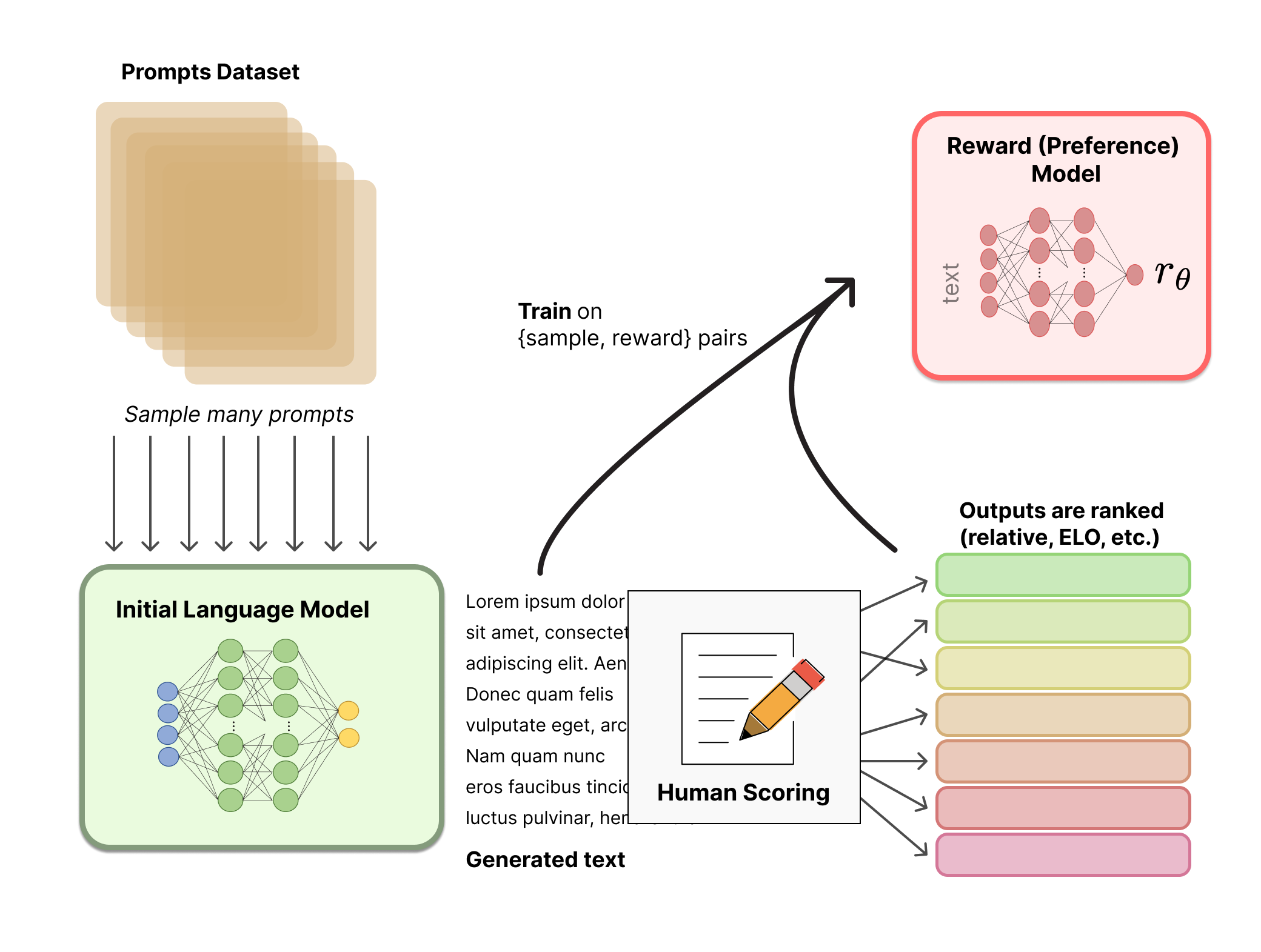
2.关于训练奖励数值方面,这里需要人工对 LM 生成的回答进行排名。起初我们可能会认为应该直接对文本标注分数来训练 RM,但是由于标注者的价值观不同导致这些分数未经过校准并且充满噪音。通过排名可以比较多个模型的输出并构建更好的规范数据集。这个过程中一个有趣的产物是目前成功的 RLHF 系统使用了和生成模型具有 不同 大小的 LM (例如 OpenAI 使用了 175B 的 LM 和 6B 的 RM,Anthropic 使用的 LM 和 RM 从 10B 到 52B 大小不等,DeepMind 使用了 70B 的 Chinchilla 模型分别作为 LM 和 RM) 。一种直觉是,偏好模型和生成模型需要具有类似的能力来理解提供给它们的文本。看来lm和rm可以不同模型.
3. 用强化学习微调
这是最核心的部分.长期以来出于工程和算法原因,人们认为用强化学习训练 LM 是不可能的。而目前多个组织找到的可行方案是使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。
让我们首先将微调任务表述为 RL 问题。首先,该 策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。奖励函数 是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
PPO 算法确定的奖励函数具体计算如下:
将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 y1, y2,将来自当前策略的文本y2传递给 RM 得到一个标量的奖励 $r_θ$
将两个模型的生成文本进行比较计算差异的惩罚项,在来自 OpenAI、Anthropic 和 DeepMind 的多篇论文中设计为输出词分布序列之间的 Kullback–Leibler (KL) divergence 散度的缩放,即 rθ−λrKL 。
这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。此外,OpenAI 在 InstructGPT 上实验了在 PPO 添加新的预训练梯度,可以预见到奖励函数的公式会随着 RLHF 研究的进展而继续进化。我感觉加入梯度是要让训练可控,保证逐渐收敛,而不是跳跃.
也就是新旧模型参数变化不要太大.
最后根据 PPO 算法,我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性) 。PPO 算法是一种信赖域优化 (Trust Region Optimization,TRO) 算法,它使用梯度约束确保更新步骤不会破坏学习过程的稳定性。DeepMind 对 Gopher 使用了类似的奖励设置,但是使用 A2C (synchronous advantage actor-critic) 算法来优化梯度。
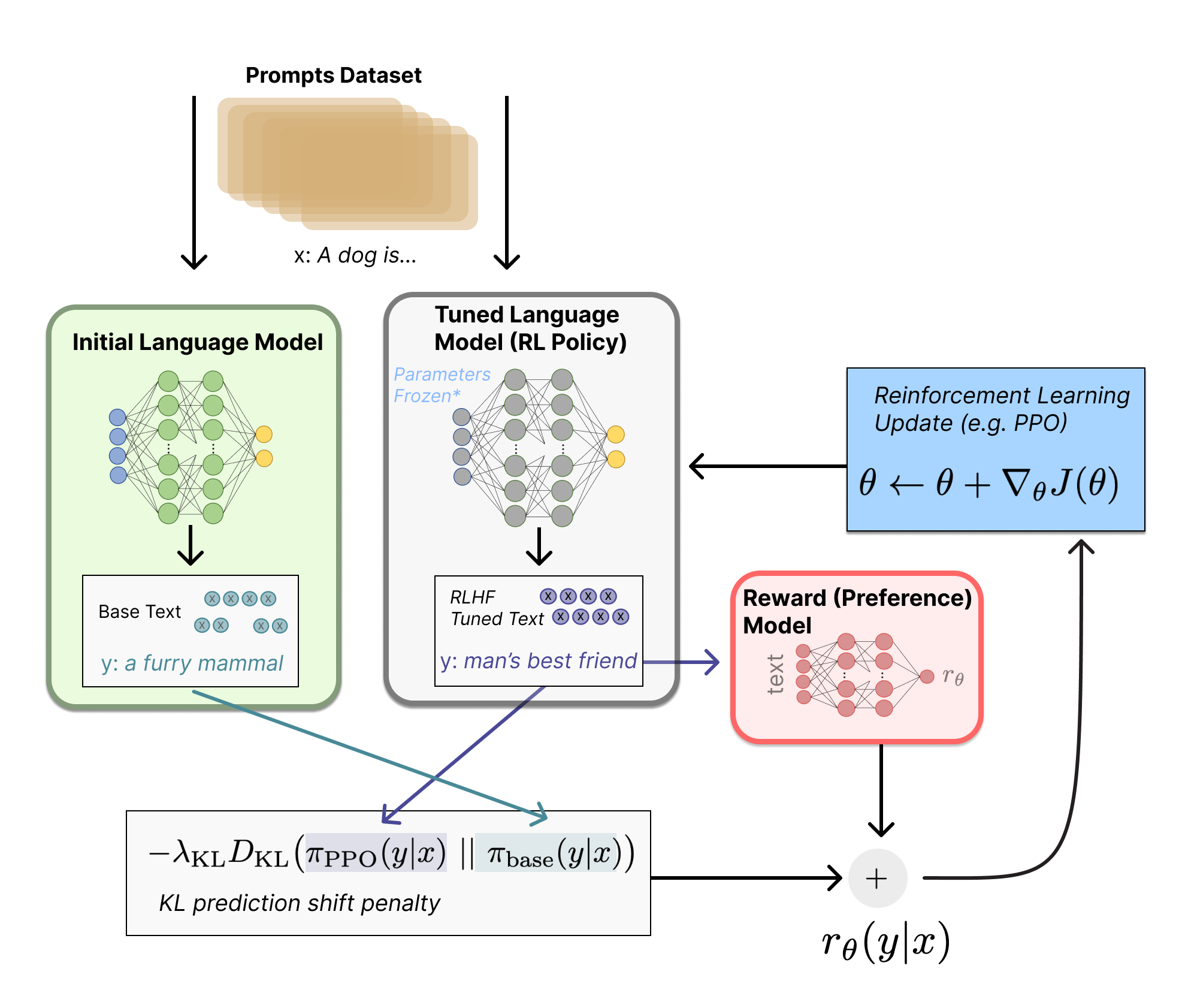
最后我们再来理解一下第三步的图片流程:
图片里面的J函数就是rθ−λrKL. 我理解交替更新两个语言模型的参数.所以这里面写上对于tuned lm 做了参数freeze
训练 RM 需要的奖励标签规模大概是 50k 左右,所以并不那么昂贵 (当然远超了学术实验室的预算) 。
还有一些其他实现.我们继续读blogs.
第二篇:
https://huggingface.co/blog/zh/stackllama
现实中,我看到的rlhf代码跟上面博客里面的不同.因为我们可能无法同时开2个模型进行训练,并且再加上评估模型就更慢了. 还有我们数据集都是成对和打分的. 是现有数据集而不是上一篇博客数据集都是lm给出的. 所以我们还需要看其他的实现, 如何落地. 目前用过的就是trl库包.
这个博客里面的数据集是:https://huggingface.co/datasets/lvwerra/stack-exchange-paired
高效训练策略
即使是最小 LLaMA 模型的训练,都需要大量内存。估算一下: 以 bf16 半精度,每个参数用 2 个字节 (以 fp32 精度四字节的标准),训练时需要 8 个字节 (例如 Adam 优化器,参见 Tramsformers 的 性能文档)。可见 7B 参数量的模型将用 (2+8)* 7B = 70 GB 的内存,并且还可能需要更多用于计算诸如注意力分数的中间值。所以很难在一张 80GB 显存的 A100 上训练。或许你可以使用一些技巧,比如用更高效的半精度训练的优化器来压缩内存,但溢出是迟早的。
另外的可能是 参数高效的微调(Parameter-Efficient Fine-Tuning, PEFT) 技术,比如 peft 库,它可以对使用 8-bit 加载的模型做 低秩优化(Low-Rank Adaptation,LoRA)。
训练时需要 8 个字节 (例如 Adam 优化器).
我们来证明这个结论:
论文:8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION: 第三页:

因为每一次梯度传导, 上一层的梯度算完, 乘以当前层的矩阵即可得到. 所以梯度是不用每一个都存储的. 也就是g0到gt不用存.
所以对于Momentum算法. 我们只需要存mt, mt 就是所有参数的梯度. 所以对于32bit的状态, 我们会用4bit 来存储 . 同理Adam 存mt 和rt即可. 所以是8bite.
1GB=1000*1000*1000bite=10^9/4 float 所以4GB=10^9 float =1B model. 所以momentum 4GB可以训练1B模型. Adam 8GB可以训练1B模型.
所以我们常用的llama7B Adam 训练需要 56GB显存来做全参数训练.
后续我会看trl 库的代码实现