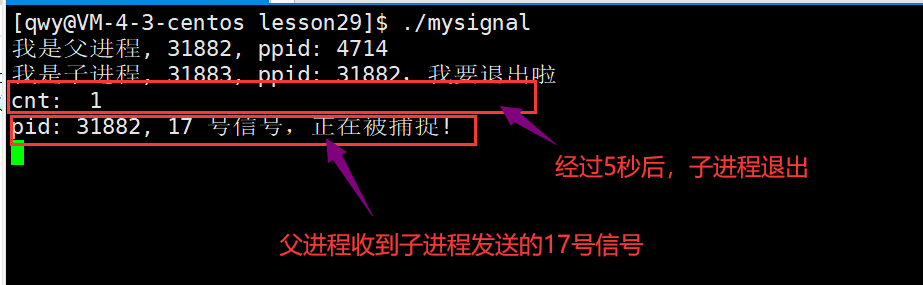
非递归遍历的核心是用栈模拟递归的调用过程,通过手动维护栈来替代系统栈,实现前序、中序和后序遍历。以下是三种遍历的代码实现与关键逻辑分析:
一、二叉树遍历
1.1、前序遍历(根 → 左 → 右)
核心逻辑:访问根节点后,先压右子节点再压左子节点(利用栈的 LIFO 特性)。
步骤:
- 根节点入栈。
- 循环弹出栈顶元素并访问。
- 若存在右子节点,入栈;若存在左子节点,入栈。
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
final LinkedList<TreeNode> stack = new LinkedList<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
res.add(node.val); // 访问根节点
if (node.right != null) stack.push(node.right); // 右子先入栈
if (node.left != null) stack.push(node.left); // 左子后入栈
}
return res;
}
1.2、中序遍历(左 → 根 → 右)
核心逻辑:先遍历到最左叶子节点,再回溯处理中间节点和右子树。
步骤:
- 持续压左子节点入栈,直到左子为空。
- 弹出栈顶元素访问,并将当前指针转向右子节点。
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
final LinkedList<TreeNode> stack = new LinkedList<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()) {
// 压左子树到栈底
while (cur != null) {
stack.push(cur);
cur = cur.left;
}
cur = stack.pop();
res.add(cur.val); // 访问当前节点(左子处理完)
cur = cur.right; // 转向右子树
}
return res;
}
1.3、后序遍历(左 → 右 → 根)
核心逻辑:需确保左右子树均已处理后再访问根节点,常用双栈法或标记法。
方法1:双栈法(反向输出根右左)
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
final LinkedList<TreeNode> stack1 = new LinkedList<>();
final LinkedList<TreeNode> stack2 = new LinkedList<>();
stack1.push(root);
while (!stack1.isEmpty()) {
TreeNode node = stack1.pop();
stack2.push(node); // 辅助栈存储逆序
if (node.left != null) stack1.push(node.left); // 左先入栈1
if (node.right != null) stack1.push(node.right); // 右后入栈1
}
// 逆序输出即为后序
while (!stack2.isEmpty()) {
res.add(stack2.pop().val);
}
return res;
}
方法2:单栈标记法(记录访问状态)
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
final LinkedList<Pair<TreeNode, Boolean>> stack = new LinkedList<>();
stack.push(new Pair<>(root, false));
while (!stack.isEmpty()) {
Pair<TreeNode, Boolean> pair = stack.pop();
TreeNode node = pair.getKey();
boolean visited = pair.getValue();
if (node == null) continue;
if (visited) {
res.add(node.val);
} else {
stack.push(new Pair<>(node, true)); // 根标记为已访问
stack.push(new Pair<>(node.right, false));
stack.push(new Pair<>(node.left, false));
/* 中序
stack.push(new Pair<>(node.right, false));
stack.push(new Pair<>(node, true)); // 根标记为已访问
stack.push(new Pair<>(node.left, false));
*/
/* 先序
stack.push(new Pair<>(node.right, false));
stack.push(new Pair<>(node.left, false));
stack.push(new Pair<>(node, true)); // 根标记为已访问
*/
}
}
return res;
}
class Pair<k,B>{
public Pair(k key, B value) {
this.key = key;
this.value = value;
}
k key;
B value;
public k getKey() {
return key;
}
public void setKey(k key) {
this.key = key;
}
public B getValue() {
return value;
}
public void setValue(B value) {
this.value = value;
}
}
二、关键对比与总结
| 遍历方式 | 栈操作特点 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|
| 前序 | 根 → 右 → 左入栈,出栈顺序根 → 左 → 右 | O(n) | O(n) |
| 中序 | 持续压左子,回溯时处理根和右子 | O(n) | O(n) |
| 后序 | 双栈反转根右左为左右根,或标记访问状态 | O(n) | O(n) |
优化建议:
- 统一写法:通过标记法(如
Pair<节点, 是否已访问>)可统一三种遍历,仅调整入栈顺序。 - 避免大栈深度:对于极不平衡的树(如链状结构),递归可能导致栈溢出,非递归更安全。
适用场景:
- 前序:快速复制树结构(先创建父节点)。
- 中序:二叉搜索树的有序输出。
- 后序:释放子树内存(先处理子节点再父节点)。
三、常见问题
-
为什么后序遍历比前序/中序复杂?
后序需确保左右子树均处理完才能访问根节点,需额外机制(如辅助栈或标记状态)保证顺序。 -
非递归和递归的性能差异?
递归代码简洁但隐含函数调用栈开销;非递归手动管理栈,空间复杂度相同,但常数因子更优。 -
如何处理层次遍历?
使用队列(BFS),而非栈(DFS)。每次处理一层节点,按层加入结果列表。