嘿,记得给“机器学习与推荐算法”添加星标
鉴于经典的协同过滤算法的有效性和易用性,基于物品的协同过滤方法已被广泛应用于工业领域,并在近年来被广泛研究。基于物品的协同过滤方法的关键在于物品之间的相似度测量,但本文认为这是一个粗粒度的数值,其难以捕捉用户对物品不同属性方面的细粒度偏好。

如图1所示,用户A和用户B都观看了电影《Inception-盗梦空间》和《Interstellar-星际》,这两部电影都是由克里斯托弗-诺兰导演的科幻电影。同时,用户A看了另一部《Matrix-黑客帝国》,用户B看了《Dunkirk-敦刻尔克》。根据传统的基于物品的协同过滤方法的原理,如果两个项目在用户的购买记录中频繁出现,它们可以被视为 "相似 "或相互关联。因此,在传统意义上,电影《敦刻尔克》会被认为与用户A的观看历史中的电影相似,然后它可能会被推荐给用户A。然而,这样的推荐将无法捕捉到细粒度的偏好,因为用户A因为同一类型的科幻电影而观看这三部电影,而对克里斯托弗·诺兰导演的战争电影没有兴趣。
基于此,本文提出了一个叫做双注意力机制的关系嵌入模型REDA(Relation Embedding with Dual Attentions)来解决这些挑战,在此基础上,其设计了一个新的范式,叫做基于关系的协同过滤,以实现高性能的推荐。

REDA本质上是一个深度神经网络模型,它采用了物品关系嵌入方案来表示物品间关系。它的特点是具有双注意力提炼的多分解物品嵌入的功能,并采用了一种新颖的关系优化方案进行端到端学习。然后,通过聚合一个用户的所有购买物品之间的物品关系嵌入,进而提出了一个关系型的用户嵌入,它不仅可以描述用户的细粒度偏好,还可以缓解数据的稀疏性问题。
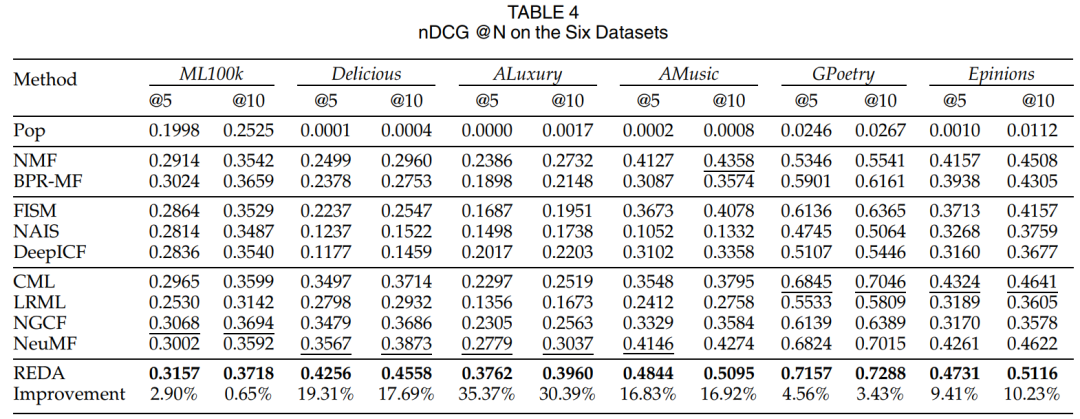
最后,本文在六个真实世界的数据集上进行了广泛的实验,结果表明,所提出的REDA优于十种最先进的方法。特别是,REDA显示了对数据和关系稀疏性的巨大稳健性、学习可解释物品方面的能力,以及大规模推荐的潜力。

更多技术细节大家可以移步原始论文进行精读。
原文链接:https://ieeexplore.ieee.org/document/9495128
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
AAAI2023 | 均匀序列更好: 时间间隔感知的序列推荐数据增强方法
论文周报 | 推荐系统领域最新研究进展
Kaggle多目标推荐算法竞赛,赶紧一起组队来战
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
喜欢的话点个在看吧👇



![[oeasy]python0031_挂起进程_恢复进程_进程切换](https://img-blog.csdnimg.cn/img_convert/9f9420c17a6517a37e0382e5899934e4.png)