一般数据流
数据流的定义
数据流(data stream)是一组有序,有起点和终点的字节的数据序列。包括输入流和输出流。数据流最初是通信领域使用的概念,代表传输中所使用的信息的数字编码信号序列。这个概念最初在1998年由Henzinger提出,他将数据流定义为“只能以事先规定好的顺序被读取一次的数据的一个序列”。
数据流的背景
数据流应用的产生的发展是以下两个因素的结果:
细节数据
已经能够持续自动产生大量的细节数据。这类数据最早出现于传统的银行和股票交易领域,后来则也出现为地质测量、气象、天文观测等方面。尤其是互联网(网络流量监控,点击流)和无线通信网(通话记录)的出现,产生了大量的数据流类型的数据。我们注意到这类数据大都与地理信息有一定关联,这主要是因为地理信息的维度较大,容易产生这类大量的细节数据。
复杂分析
需要以近实时的方式对更新流进行复杂分析。对以上领域的数据进行复杂分析(如趋势分析,预测)以前往往是(在数据仓库中)脱机进行的,然而一些新的应用(尤其是在网络安全和国家安全领域)对时间都非常敏感,如检测互联网上的极端事件、欺诈、入侵、异常,复杂人群监控,趋势监控(track trend),探查性分析(exploratory analyses),和谐度分析(harmonic analysis)等,都需要进行联机的分析。
在此之后,学术界基本认可了这个定义,有的文章也在此基础上对定义稍微进行了修改。例如,S. Guha认为,数据流是“只能被读取一次或少数几次的点的有序序列”,这里放宽了前述定义中的“一遍”限制。
为什么在数据流的处理中,强调对数据读取次数的限制呢?S. Muthukrishnan[89]指出数据流是指“以非常高的速度到来的输入数据”,因此对数据流数据的传输、计算和存储都将变得很困难。在这种情况下,只有在数据最初到达时有机会对其进行一次处理,其他时候很难再存取到这些数据(因为没有也无法保存这些数据)。
推荐系统数据流
经典框架
• 批处理大数据架构
• 流计算大数据架构
• Lambda架构
• Kappa架构
批处理大数据架构
'分布式存储+Map Reduce”的架构只能批量处理已经落盘的静态数据,无法在数据采集、传输的工属具流动的过程中处理数据
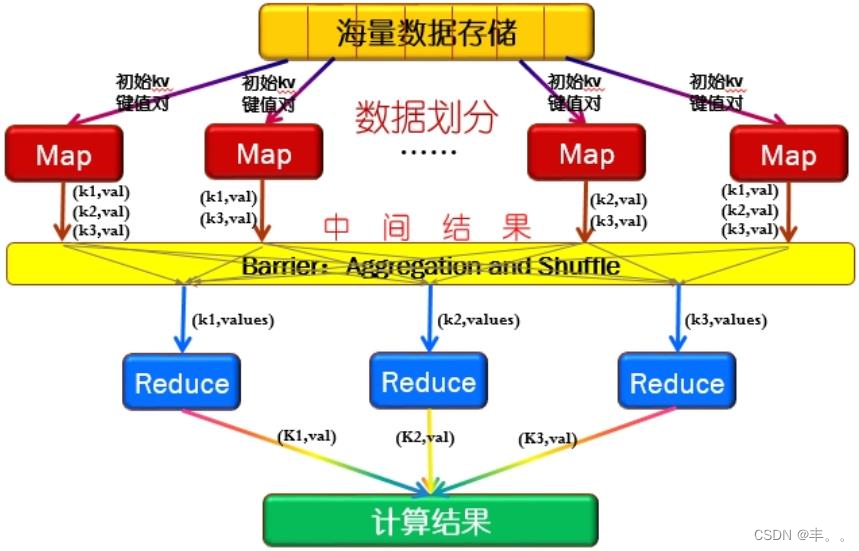
流计算大数据架构
• 分布式流计算大数据架构在数据流产生及传递过程中流式的消费并处理数据。
• 流计算架构中使用滑动窗口,在每个窗口内部,数据被短暂缓存并消费,在完成一个
窗口的数据处理后,流计算平台滑动到下一个时间窗口进行新一轮的数据处理。
• 理论上,流计算平台的延迟仅与滑动窗口的大小有关,滑动窗口的大小基本
以分钟级别居多,数据延迟小。
工具:
Strom、Spark-streaming、Flink
Flink将所有数据均看做流,把批处理当做流计算的特殊情况
Spark-streaming的流计算时小时间片内的小批量处理
Lambda架构&Kappa架构
Lambda架构:
数据通道在数据采集阶段就分为两条:实时流和离线处理
• 实时流保持了流计算框架,以增量计算为主来保障数据实时性(kafka+redis)。
• 离线部分进行批处理,对数据进行全量计算,保障其最终的一致性及最终推荐特征的丰富性(hdfs)。
• 最终数据入库时,实时流数据和离线数据进行合并,利用离线层数据对实时流数据进行校验和纠错。
Kappa架构:
• 解决Lambda架构的代码冗余问题,批处理与实时流都以流计算形式进行
如何在离线环境下利用同样的流处理框架进行数据批处理?
• 需要在原有流处理框架上加上两个新的通路“原始数据存储”和“数据重播”
• 原始数据存储将未经流处理的数据或者日志原封不动地保存到分布式文件系统中
• 将这些原始数据按时间顺序进行重播,采用相同的流处理框架处理,完成离线状态下的数据批处理。



![[oeasy]python0031_挂起进程_恢复进程_进程切换](https://img-blog.csdnimg.cn/img_convert/9f9420c17a6517a37e0382e5899934e4.png)